Spring Cleaning Your Databases
11 Comments
Even with lots of monitoring in place, we should perform periodic checks of our SQL Servers.
Think of this like “Spring Cleaning”, except I would recommend that it be more frequently than just once a year. Doing it monthly might be a bit ambitious due to our busy schedules, but quarterly could be achievable.
Below are the areas I recommend for Spring Cleaning your databases.
SP_BLITZ
There is so much good stuff reported by sp_Blitz. You’ll find common health, security and performance issues in there. Once you’ve fixed the issues of concern, you should periodically check if there are any new issues being reported. Did someone enable xp_cmdshell? Is it reporting any poison waits? Is there a new sysadmin that you weren’t aware of? This once happened at my previous job. Desktop Support team had added a user to our DBA group because it resolved an issue. This user was not even in IT. Imagine the damage that could have been done since it was common for most people to have Management Studio installed.
For more information about sp_Blitz, go here and here.
SP_BLITZINDEX
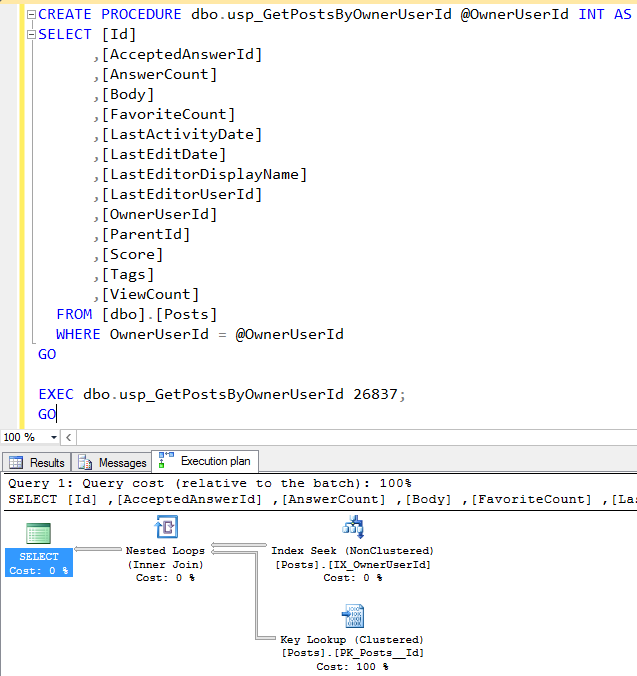
sp_BlitzIndex does a sanity check of the indexes in your database. You can increase your query performance by having the right indexes on your tables. sp_BlitzIndex helps with that. Don’t just look at it once, review the output on a regular basis, especially the High Value Missing Index, Duplicate Keys, Borderline Duplicate Keys, Unused NC Index, Active Heap sections.
For more information about sp_BlitzIndex, go here.
HIGH-VALUE MISSING INDEXES
When adding high-value missing indexes, be sure you aren’t creating a duplicate or borderline duplicate key index. Review your current indexes to determine if the high-value missing index can be combined with an existing one. Maybe an existing index just needs some INCLUDEs.
DUPLICATE AND BORDERLINE DUPLICATE INDEXES
Duplicate key indexes mean that you have two or more indexes that have the same exact key. Borderline duplicate key indexes mean two or more indexes start with the same key column but do not have completely identical keys. You may be able to combine these into one index, but analysis is needed as there are some that shouldn’t be touched.
Check this out to get more details about duplicate and borderline duplicate keys.
UNUSED INDEXES
Unused indexes are tricky. When you are analyzing this data, you have to keep in mind that this data is only available since the last restart. If you rebooted the server yesterday and are viewing the data today, you might see a lot of unused indexes in the list. But are they really unused? Or have the indexes not just been used YET? This is a very important point when deciding to disable or drop an index based on this list. If you reboot your servers monthly due to Microsoft security patches, consider reviewing the list the day prior to the reboot. I once dropped an index 3 weeks after the server was rebooted, thinking that the entire application workload must have been run by now. A few days later, I got a call on the weekend that the database server was pegged at 100% CPU utilization. I reviewed which queries were using the most CPU and found that the top query’s WHERE clause matched the index I had dropped. That query only ran once a month, which is why it hadn’t recorded any reads yet. We later moved that monthly process to another server that was refreshed regularly with production data.
HEAPS
Generally speaking, a table should have a clustered index. A good exception is staging tables, such as those needed for ETL processing. When a table doesn’t have a clustered index, it’s called a heap.
Heaps are great for INSERTs but not for SELECTs. DELETEs leave the space behind unless a table lock is used during the delete, either via a table hint or by lock escalation. Empty space takes up space in backups, restores and memory. If you scan the heap, you must also scan the empty space even if there are no rows. And then there’s UPDATEs. UPDATEs can cause forwarded records if the updated data does not fit on the page. Forwarding pointers are used to keep track of where the data is (a different page). This means extra and random IO.
Heaps cause fragmentation, extra reads and sometimes a huge waste of space.
Just say NO to heaps unless it’s a staging table or some other really, really good reason.
DATABASE SIZE AND GROWTH
Is your database growing faster than you expect? Knowing how big your database is and how fast it is growing can help you plan for future hardware upgrades including memory and disk space.
DISK SPACE
Most of us have monitoring in place to alert when a drive is running out of free space. Wouldn’t it be nice to proactively add storage before you receive an alert? Keep track of total and free disk space over time to help you determine when to add more space or even when to order more storage.
VIRTUAL LOG FILES
If a database has a high number of Virtual Log Files (VLFs), it can impact the the speed of transaction log backups and database recovery. I once had a database with 75,000 VLFs. I didn’t even know what a VLF was at the time (hence having so many). After rebooting the server, a mission critical database with extremely high SLAs took 45 minutes to complete recovery. We were in the process of opening a support case with Microsoft when the database finally came online. The next day, I contacted a Microsoft engineer and learned about VLFs.
For more information about VLFs and how to fix them, go here.
BACKUP TABLES
During a production problem, you might be saving data to a backup table to later review or possibly restore from. But are you remembering to drop these objects at a later time? Search for key words such as “backup”, “bkp”, “bak”, “temp”, or even your name or your initials.
SP_WHOISACTIVE
Hopefully you’re saving sp_WhoIsActive data to a table regularly, such as every 30-60 seconds. You may be using this data to help you find blocking, slow-performing queries, bad execution plans, or tempdb contention. But you probably are looking at the data when there is a current production problem. It might make sense to review the data periodically even if there isn’t a production problem. You might be able to spot a problem or a trend before it becomes a larger problem.
If you aren’t saving sp_WhoIsActive data, check this out for one method.
SP_BLITZCACHE
For sp_BlitzCache, I would take a peek to see if anything stands out. Capture the output of sp_BlitzCache into a table so that you can compare it to previous checks. Is there a stored procedure that’s running slower than it did previously? Is there anything surprising in there, such as a stored procedure that executing several times per second? I once supported a system that had a stored procedure running several hundred times per second. This isn’t necessarily a problem, but I wasn’t sure if it should be running this often. After speaking with the developer, I learned that it was an application bug. The developer fixed the bug in the next release, and I verified it by checking how often it was executing.
For more information about sp_BlitzCache, go here.
WRAPPING IT UP
Wouldn’t it be great to automate collecting all of this data? I leave that exercise up to the reader, but I think it’s important to also do manual checks of your SQL Servers. Set aside some time to proactively fix problems.
How often do you “Spring Clean” your SQL Servers and databases?
What else would you add to this list?
Brent says: as a DBA, it’s so easy to become completely reactive, putting out fires. There’s always gonna be a fire to distract you – you just have to buckle down and set aside time to get proactive.