
For Technical Interviews, Don’t Ask Questions. Show Screenshots.
When you’re hiring a DBA, sysadmin, or developer, you’re not paying them to answer Trivial Pursuit questions all day long.
You’re hiring them to look at a screen, connect a few dots, and interpret what’s happening.
So for a position, I build a PowerPoint deck with a bunch of screenshots from the actual environment they’ll be working in. I start the deck by explaining that there’s no right or wrong answers – I just want to hear them think out loud about what they’re seeing.
For example, I’ll show a database administrator or developer this:

Typical reactions include things like:
- “Oh, that’s a fact table.” – What does that mean? Where have you seen a fact table before? How do you handle them differently than other kinds of tables?
- “It seems really wide.” – What does that mean? Are there strengths or challenges with wide tables? How many columns should a table have?
- “The fields are mostly nullable.” – Is that the default? How do fields end up that way? What would you recommend changing? How might it break things, and how would you check to see if they were going to break? Would end users notice the impact of your changes?
- “It isn’t normalized – it has both IDs and names.” – What kinds of tables might have that design pattern? What would be the performance impact of this design?
Whenever they say anything out loud, follow the thought. Don’t assume that they believe the same thing you do – ask open-ended questions to get them to explain what they know.
Let them talk until they’re silent for several seconds, and that’s their normal knowledge base. Resist the temptation to make suggestions like, “Did you notice how there doesn’t seem to be a clustered index?” If they don’t notice it, they don’t notice it – that’s your sign.
Another example – I’ll say, “Someone brought this query to you and complained that it’s slow. Where might you look for improvements?”
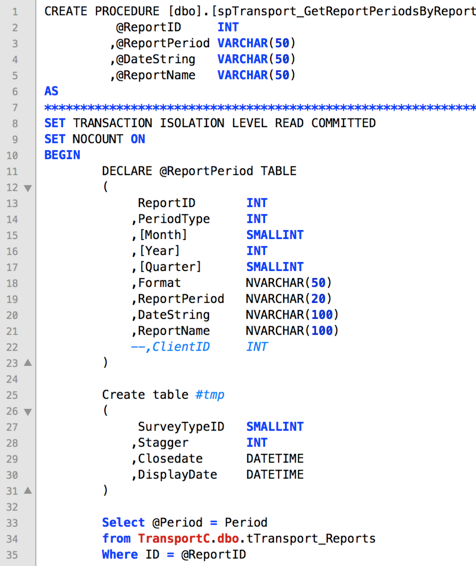
The query is abridged, but even just in that first screenshot, I want to hear their thought process around where they look, how they might run the query to check its effects, how to measure their work.
In your own interviewing, try to use real screenshots from your own environment. Show them the kinds of screens that they’re going to have to look at independently in their day-to-day work, and just let them brain dump about what they’re seeing.
Hearing their thought process is way more valuable than playing Trivial Pursuit.

64 Comments. Leave new
This is very nice. Writing code in interviews can take a lot of time. Reviewing flawed or suspicious code can show a lot of experiences in a short amount of time.
Is there something to be found in the second screenshot? I did not find anything major.
Tobi – indeed there is. But we’ll go ahead and move on to the next slide. 😉
My thoughts in order on the second screenshot.
1. Where’s the definition for the table in the select?
2. It’s not there, must not be important.
3. Eww, table valued parameter. I’ve had bad performance with those in the past.
4. No, wait, that’s a table variable not a table valued parameter, I can’t imagine it would be much better
5 Why are they mixing table variables and temp tables?
6. Wait, there’s a parameter named @ReportPeriod and a local variable named @ReportPeriod, with different datatypes. That’s even valid?
Interesting, now you’re starting to get somewhere. 😀
I don’t think the query would compile because @Period isn’t defined. Doesn’t explain why it would be slow, but it wouldn’t work.
I did notice the @ReportPeriod there twice too. I now need to go find out what that does
Forgot to mention the cross database query would also be worth investigating
Greg – is there a performance overhead to having cross-database queries?
I don’t think there is on cross-database (I’ll go look it up now). I know linked servers could, but that’s not the query you have.
The scenario you posed was “someone complained it was slow, what would you look at”?
I’d have a look at the the cross database join. More importantly I’d have a look at the table structure and see how big it is and if ID has an index. The query plan could tell me that
OK, so if someone said the query was slow, you would look at the thing that doesn’t have a performance impact. Interesting. We’ll go on to the next slide. 😉
Should have been clearer. I’d look at the structure of transportC.dbo.tTransport_Reports and see what data type ID was (compared to @reportID) and see if it had a useful index, if it had a significant number of rows.
Based on the snippet you have sent through, the only performance problem should be in that last statement – the create #temp table shouldn’t take long (if it does the TempDB contention is your problem) and the table variable should create instantly (if not then there’s a huge memory issue).
The only other thing (From the snippet) worth checking is the query plan – has SQL cached a crap plan.
Actually, other thing I just noticed is the transaction isolation level being read committed. Could be a locking issue on transportC.dbo.tTransport_Reports. Check if TransportC database has that option turned on (I forget what it’s called)
I hope you’re going to give your answer to this question in the coming days. I’m keen to learn what you’d look for when a client asks you.
Greg – I am now! I got more and more excited as more people commented their answers – it’s so much fun to see how people think. I’m joking around with the “next slide” comments, but there’s all good answers in here.
I thought I’d just post this one post and be done with it, but there’s enough interest that I’m either going to make it a weekly Monday series, or do a week straight of several posts with screenshots. It’ll start next week either way, and I’ll put a big long comment in here with my thoughts on these screenshots later this week after more folks have time to post their thoughts.
Brent, are you still planning to come back and leave your answer? I’m still keen to hear what you’d look at
Greg – no, I ended up starting another series where I post screenshots and talk in the comments. Check out today’s post, for example.
Brent – by going back on your promise of telling us what you’d look for, you’ve become… a looktease. 😉
There are tons of things I notice in this… Not sure if anyone mentioned this, but nvarchar(100) is way too much for a report name.
Table variables are fine but they get slow when you try to insert a decent amount more than 1 row in them as most query plans I’ve seen seem to expect 1 row from them. They cant have primary keys or any type of index either :c
Mark – hmm, table variables can’t have any indexes you say? That’s interesting. We’ll go on to the next slide.
I know right, apparently we are only allowed 1 index per database. Hard life. I wish There is SQL 2018 so we can get multiple indexes per table.
I love the 2nd slide bit by the way.
Also, It made me cringe – there is no performance penalty for cross db queries, can you guys please drop that, capish?
we don’t actually know if that is the entire code for the stored procedure.
but
– @Period is not defined, how can that proc even exist or be slow?
– read committed would cause locking (aka slowness in customer’s eyes). Do they have RCSI or RC?
I see you’re not a fan of the “can you guess the exact solution I am thinking of” style of questioning 🙂
I’ve went for a contract where I was called back for round after round of in-depth exhaustive trivial pursuit type probing before.
Then on my first day I found that source control contained ten different repos of the same massive solution, with executables, compiler intermediate files, temp files, all checked in as well. Nobody can tell you which one is the ‘correct’ one. You clone a repo locally and try to build, and discover there are a load of dependencies not in source control. Your first couple of weeks is spent getting hold of the right versions of them, which in some cases requires getting a license, which requires calling remote people who only pick up the phone for 3 hours on Tuesday morning.
After a couple of weeks, get a call from my boss saying the client complains I am not making enough progress.
But wait, there’s more. The app was initially written by another consulting firm that were hired a year before the spec was complete. They spent that year building a set of their own custom controls like text boxes in .NET. Their ContosoTextBox for example was just like a real text box except vastly slower and it contained lots of business logic.
When the spec was delivered they created forms populated with dozens of tabs each with hundreds of these ContosoControls. They did not bother to give them a name, just keeping the default ContosoTextBox98, etc. Now Visual Studio Winforms designer can’t cope with forms that have several thousand controls, so to add a control or move one, required first wading though a hundred thousand line .designer.cs file and figuring out where to put it.
It gets better. Corporate mandated that the development server had the same security mandates as production with mandatory password changes every week and an account lockout after three unsuccessful attempts. With 50 developers in 3 countries you’d better believe we spent a LOT of time on the phone to support getting password resets. Now, can we get in and do some work, before someone locks us out again?
Even better, the development and production servers were on the same box. If production got slow, operations would divert resources from development, which would prevent us doing any work because the app would time out requesting the server.
Best of all, the app was so bloated, it would take sometimes 10 minutes to start up. That’s the point at which you discover if the server is responding or the password has been changed again.
TL;DR If the interview process is painful, the work experience likely will be too!
My takeaway would be that maybe we should be giving our candidate bosses technical interviews too!
Agreed. An interview should be a two way street with the job candidate interviewing the company/manager/co-workers just as much as the candidate being interviewed.
Slide 1 reaction: Where are the keys at?!?! Assuming that’s all the columns, I see no primary key defined and no foreign key relationships defined (call me old fashioned but I still want them in my data warehouses)… And the known universe can have null marks. *sadface*
Hi Brent, thanks for this very interesting post.
Is it common that a client will ask *you guys* to go through this same kind of exercise using their production or in-development schemas? I see that you offer “Critical Care”, but what about more simple “Critical Eye” design / code reviews?
Thanks in advance for any reply.
Brad – great question. Typically no, because database designs are so sprawling. We focus on the fastest way to get you performance relief – just taking a look-see at database designs can get pretty expensive fast.
In the second screenshot, here are some of my initial observations:
– You’re taking the date in as a string parameter. If the type in the target table is a date it’s likely SQL Server is doing a conversion on each row comparison and that can be very CPU intensive. The ReportPeriod argument also has the same issue potentially, especially since I have a hint below that ReportPeriod is really an int.
– Interesting that it is a cross database query. I’ve never had performance problems but I’d probably do some googling on whether that’s a potential factor.
– The temp table and the table variable both don’t have primary keys or indexes yet.
Paul – interesting, so if you pass in a date parameter as a string, but the datatype in the table is a date, you’ll have an implicit conversion that happens on each row, and it’s CPU-intensive? Tell me more about that.
Hmm – were you ever frightened by a string as a child?
It’s a code smell, but it’s not necessarily the reason that performance is slow. SQL Server is smart enough to only do the conversion once unless specifically ordered to do otherwise. But if someone is specifying the parameter as a string, there’s a chance they are doing something later on to make a query non-sargable.
The other thing I’m noticing other than what has already been said is the differences between the datatypes of the parameters coming in and the table variable. Not only are they varchar in one location, and nvarchar in another, they also have different lengths that could potentially also lead to data loss. And while the variables themselves never touch, they appear to touch similar data.
Then again I have had a case where fixing a varchar to nvarchar conversion actually slowed down a query…
There will be implicit conversion on the columns ReportPeriod, DateString, Report Name as the parameter is getting passed is VARCHAR and the table has NVARCHAR, it does not matter if you have Index on these columns, still it will do full scan on the index. Query performance will suck as every query needs to scan whole table or full scan on the index, specially when there is large table.
oh yeah, i had to argue that fact to a vendor for a while. they expanded ASPSTATE functionality, but used a NVARCHAR in their code against a VARCHAR from Microsoft.
Screenshot 1 –
There appears to be no indexes on the fact table. A true fact table always has an index
The Fact table shouldn’t contain any of the name fields.
The Fact Tables *usually* contain numerical information (or facts) that can be used to summarise information
Screenshot 2 –
ReportPeriod has varying length. 50 in the param, 20 in the ReportPeriod Table. Also, not sure you could declare the @ReportPeriod table var with that name, as the parameter uses it.
Again, the lengths of the DateString and ReportName fields/params vary. But for these two, it’s the other way round.
Also, the three of these are VARCHARS in params, and NVARCHARS in the table object
Month and Quarter in the @ReportPeriod object could easily be TINYINT, Year could be a SMALLINT, unless this is SQL v32768
Can’t really judge the cross db call just now, but with Read Committed set, depends on the use of the tTransport_Reports table and how often it is accessed.
It’s odd the use of table variables and temp tables, but without any insight as such on the use, can’t really judge it yet. It could be that #tmp is needed later if a child proc is called or something.
@Period isn’t declared in the select at the bottom.
@Period is not declared.
There’s probably more, but it’s what my eyes see at this moment..
Yay implicit conversions. I mean, who cares about those silly indexes…..they don’t really do anything do they?
I’d like to share an unusual but effective interviewing technique.
For each job spec, we listed the skills it needed. We rated the skill levels, on a scale of 1:10. 2 means “I have done simple stuff looking up everything”, 5 means enough for a core skill at junior level, 10 means world champion etc. This tackles one hiring issue – hiring someone who has great skills you respect which really aren’t needed for the job, yet doesn’t have some essentials.
We then worked out our expectations of skill levels from the CVs, useful for the firs level of screening.
At interview, we explained the rating system and asked them to estimate their levels. We created a ranked set of questions and used questions appropriate to the candidate’s claims. This could be quite revealing when our estimates, the candidates’ and their actual performance differed. If someone proved too boastful (or skilled), we’d ask them to re-estimate and adjust the questions.
Before doing this, we made a bad hire. We ended up hiring some people we’d have previously rejected at the CV level : all our choices turned out to be excellent hires. (We also saved money by not paying for skills we didn’t need)
Slide 2: hard to know why it’s slow without seeing what it does (let alone how it tries to do it). My immediate reaction is why don’t you show the rest, in what realistic scenario wouldn’t I just look at the rest of the query? Second reaction is, why do you call it a query when it’s a stored procedure? Maybe it’s slow because it should be written as a select?
What I meant was that it appears to be doing a transformation (period information from a single report into whatever report period*s* are supposed to be) in a procedural way, whereas if it could be expressed declaratively SQL might well run it faster – isn’t that something SQL is good at?
“Oh, that’s a fact table.”
I am amazed at how many people believe a table is a ‘Data Warehouse Fact Table’, just because the word Fact appears in the Name of the Table. The same goes with the word ‘Staged’.
While the name of the table is helpful to define what it stores, concatenated Nouns and Adjectives can have different meanings depending on the Context and each individual, and the result of stored data is not necessarily exactly as labeled on the container.
Ah but if you are in an interview, the fact (sorry) it is called fact_ segways you easily into talking about your knowledge in such an area.
After all, the post is a hypothetical interview. It could almost be *deliberately* called that for that very reason….
Screenshot 1:
– There is no key structure on the table. Even if you intended for this to be a heap table for fast writes, there is nothing preventing accidental (or intentional) duplication of data.
– There are no indexes on the table. The screenshot is cut off at the bottom but a missing + / – in the tree structure means it is not collapsed or expanded. The + was clicked and nothing was found. If indexes existed and off the screenshot a – would be shown in the tree view.
– There are a lot of NULL columns on what appears to be a heavily denormalized reporting table. Perhaps this is a staging table with intent to push this data elsewhere, but why denormalize the data at this point? If it is not staging but intended for reporting use, why are there no indexes? Do you really expect this much of the data to be missing?
– Rep information is required but company information is not. Do you have sales reps that are not related to organizations tracked in these tables? That seems out of place.
– At the time this data is written, is there the potential that you want to track that you don’t know if surveys have been sent or received? If you don’t know, why are you writing the data? Surveys have either been not been sent and this should be a zero (perhaps there is a default value of zero but why is the field nullable), or surveys have been sent and again the field shouldn’t be nullable. The same applies for surveys received/answered. You know when and who, but what value does the data provide if nothing else is known?
Screenshot 2:
– I know this is an abridged version, but this shouldn’t even compile. So when someone asks why it is slow, I’ll have to start with it not working at all. @Period is not defined either.
Those issues aside…
– The name of the proc tells me this is likely intended to return report periods for a specific report. If this I’m correct, I’m curious why you would need or use the 2nd, 3rd, and 4th input parameters. I’m also curious what the purpose of the #tmp table would be and why you would need to put the report data into a table variable before returning.
– With this many indications that the name isn’t consistent with that purpose, I would begin to think this is more intended to return report data for a report given a report period. This would lead me to believe the table variable is intended to store the report period(s) that the caller desires. If this is the case, why the mismatch between report name and report period varchar lengths, and inconsistent usage of varchar and nvarchar?
– Following this path, why are the values stored in a table variable vs a list of parameters? I am thinking the table variable could then be used to join to the actual report period table in some fashion. This would likely result in a table scan to the variable but it shouldn’t have enough records to make a big difference.
– Continuing this path, #tmp would likely be intended to store the actual data that would be retrieved and manipulated before being returned. If this is true, there should be an index on #tmp consistent with the type of manipulation that would be performed later. I would expect to find a solid reason not to use temp tables though, very dependent on what was further down in this proc.
– I’m not concerned with the mix of table variable and temp table given the data that would likely be used in them.
– How would l go further into finding performance issues? 1) I would obviously need to see more of the proc and find out how it is called, 2) I would try to ensure the proc was being used correctly, 3) Estimated and actual execution plans would give me a good idea of what was happening under the covers, 4) SQL Profiler and query stats would help me to see what, if any, data is available to help indicate if the proc was being overly aggressive with computing/reading/writing resources.
Monday weekly series:
I REALLY hope you do this!! Reading through the write-up I was very excited with this type of “stories with holes” approach to problem solving. This type of critical thinking effort is a great way to learn and share knowledge. Have you considered doing some sort of private answer submission system and scoring or otherwise tracking our responses? I’m sure that would be more effort on your side than you could find side time for, but something a long those lines could be very beneficial to the community. Either way I can’t wait to see what you can make of it.
Thanks for this and any future challenges!!
It would be amazing if the interview process is this way! Either I get the job or I would learn something new that day! It’s a win-win! 🙂
About Stored procedure screenshot, without out knowing all the logic inside and other DB details (assuming all the specified details from all comments is not enough), WITH RECOMPILE and/or Parameter sniffing might help?
Thanks.
For the partial sproc and only what we can see in screenshot:
– There is a row of ******* which is NOT commented out. That’ll break stuff.
– there are two @ReportPeriod, a sproc variable and a table variable
– could [Month] be a TINYINT instead?
– could [Year] be a SMALLINT instead?
– could [Quarter] be a TINYINT instead?
– @ReportPeriod.ReportPeriod column is different type and shorter length than @ReportPeriod sproc variable.
– @ReportPeriod.DateString column is different type and length to @DateString sproc variable.
– @ReportPeriod.ReportName column is different type and length to @ReportPeriod sproc variable.
– SurveyTypeID column: why not TINYINT?
– Closedate and Displaydate columns: why not use DATETIME2 type?
– the SELECT at the end should be re-written as SET @Period = (SELECT… Why? So it errors if you end up having more than 1 Period returned per tTransport_Reports.ID value.
Oh, and for the actual question about where to look for performance:
– check the tTransport_Reports table isn’t a heap (of s**t)
– add a non-clustered index on ID, Period for speed’s sake!
When someone complains a query is slow the first thing you look at is the person.
#1 definitely looks like a data warehouse table that’s a flattened version of multiple tables from the source. It’s not normalized for better read performance. Not only isn’t there a clustered index (primary key), but it appears there aren’t any indexes at all (no + next to the Indexes folder). I also see mainly varchars, so probably not international data.
In addition to Shawn’s comment, since it’s in dbo I’d guess the table is destined for a one-off export to Excel, or for input to a data profiling tool as part of a migration effort. Probably (hopefully) not in a production database.
Great stuff Brent!
Really looking forward to the weekly Monday series. Will be a great way to but all the theory learnt into practice. A lot of things I learn are not used in our environment and stuff I learnt a while back fade with time. Will be nice to dust off the cobwebs of neglected knowledge.
A great way to learn how to detect and resolve issues returned by sp_BlitzCache.
Do the four fields in the parameter table have to be Unicode? We could save 270 bytes by changing the fields to VARCHAR and skinny up the table some and save space in the buffer pool and in TempDB. I’m a little scared by the use of a table variable vs a temp table; still we don’t know how many rows will be inserted there so have to make assumptions that it could be quite a few.
Hi Brent,
Sorry, I humbly disagree.
If I have urgent need of a heart-surgeon should I choose one with a quick pop-quiz (verbal or graphic)?
Richard – sure, let’s explore that. What interview questions would you use for your heart surgeon?
And as you come up with your list, keep in mind that any bad surgeon will prep for your interview by Googling heart surgeon interview questions.
Brent – I would choose my heart surgeon with the most successes (the most experience, or peer review perhaps). If there was not a clear winner I guess I would look at qualifications.
My point is – I would not know enough to be able to tell good-from-bad using a quiz.
I think we should start by assuming the interviewer knows less about DBA than the candidate.
Richard – thanks for taking the time to answer. Successes, experience, and qualifications are only the first part in choosing someone – and that’s called a resume. The next thing you need to do is determine how the candidate actually delivers in real life, because it’s fairly easy to fake a resume.
Hope that helps!
Brent – Good point (fake cv’s). I guess I would take every CV as truthful, assuming everyone would exaggerate by about the same amount.
I would not presume to rank real life surgical achievements.
Also it occurs to me that we really should wrestle qualification-authority away from course runners like Microsoft.
The trouble is everybody lies a little sometimes, but some people are much, much, MUCH bigger liars than others. I’m going to be a little vague here because I don’t want to get sidetracked on a political debate, but one need only look at the example of politics to see that this is true.
I see the role of the technical interviewer as detecting imposters. It doesn’t have to take a very long time. Have someone with enough technical knowledge to tell the difference probe a few areas to make sure that you’re dealing with a standard CV exaggerator rather than a complete phony. Be especially wary of anyone who falls back on stereotypical used-car salesman tactics like bluster, flattery, or tugging at heartstrings to distract from weak technical answers.
If a hiring manager isn’t technical enough him- or herself to detect phonies, get help from someone who is. Hiring the wrong person is quite expensive and risky, and if a manager isn’t technical enough to catch on for a long time, it’s amazing how much damage can be done not only to the work itself, but to the morale of the rest of the team.
On reflection, and in summary, I would employ the person with the strongest CV and watch them closely for a probationary period.
Yeah, hopefully they won’t kill too many folks during that probationary period. 😉 Good luck with your hiring!
Brent, fantastic posts!
I have learned some great best practices with respects to technical interviews in general. My biggest take away is to keep it real. I charged our interview process to follow this mantra as well as your recommended format. Instead of presenting the candidate with a generic text book question, I now present them with a real life scenario which mimics what they will be doing in real life at our company. They get a first hand insight into their new job and expectations while I get to assess if they meet my expectations as a senior DBA in a normal real life situation.
The purpose of a technical interview should not be about how well an interviewee can regurgitate formal definitions and answers; rather it should be about assessing how they can apply their experience and knowledge.
BTW, Brent I am using your interview format and concepts presented within, bloody fantastic work, Thank you.
Thanks sir!
1. What do you tell the help desk?
I wouldn;t “tell” them anything but I would “ask” why they think there is something wrong? What symptoms are being reported by users? What time of day is this? It could be normal running.
2.What actions do you take next?
Depends on answer to 1
Huh, I had no idea that you could put
SETstatements before the procs BEGIN/END block like that.I fully did not expect that to work, but I tested it and it does.
I don’t know if this is considered bad form…but I kind of like the idea of putting those outside of the block, it’s nice having those “isolated” (pun not intended, but it’s a nice add).
I should have drank some coffee before leaving that comment. My brain was not parsing that code at the rate it should have been. lol. I now realize where my brain stopped working and the code now makes sense.
However, I do like that structure. I’ve never seen anyone write it that way. Usually it’s either…
CREATE PROC dbo.usp_FooBar
AS
BEGIN
SET ...
...
END
GO
Or…
CREATE PROC dbo.usp_FooBar
AS
SET ...
...
GO
I may have to consider taking up that style for my own procs….Placing
SETstatements and maybe other generic logging actions outside of the main BEGIN/END block.