
Builder Day: Doing a Point-in-Time Restore in Azure SQL DB
We’re trying something new at the company: Builder Day. We define a slightly-out-of-the-norm task, and then the team splits up and tackles the task on different cloud platforms, writing it up as we go. These posts aren’t going to make you an expert on the topic – they’re just meant to let you skim through technologies you might not otherwise get the chance to play with. The cloud changes fast, so some of this is just about seeing what providers are up to these days.
This week, our task is doing a point-in-time restore:
- Create an empty database
- Set up point-in-time backups
- Create a table with some stuff in it
- Make sure backups are happening
- Do a point-in-time restore
I’m up first with Azure SQL DB. Tomorrow, Tara will cover Amazon RDS SQL Server, and Erik’s on SAP HANA for Thursday.
1. Create an empty database in Azure SQL DB.
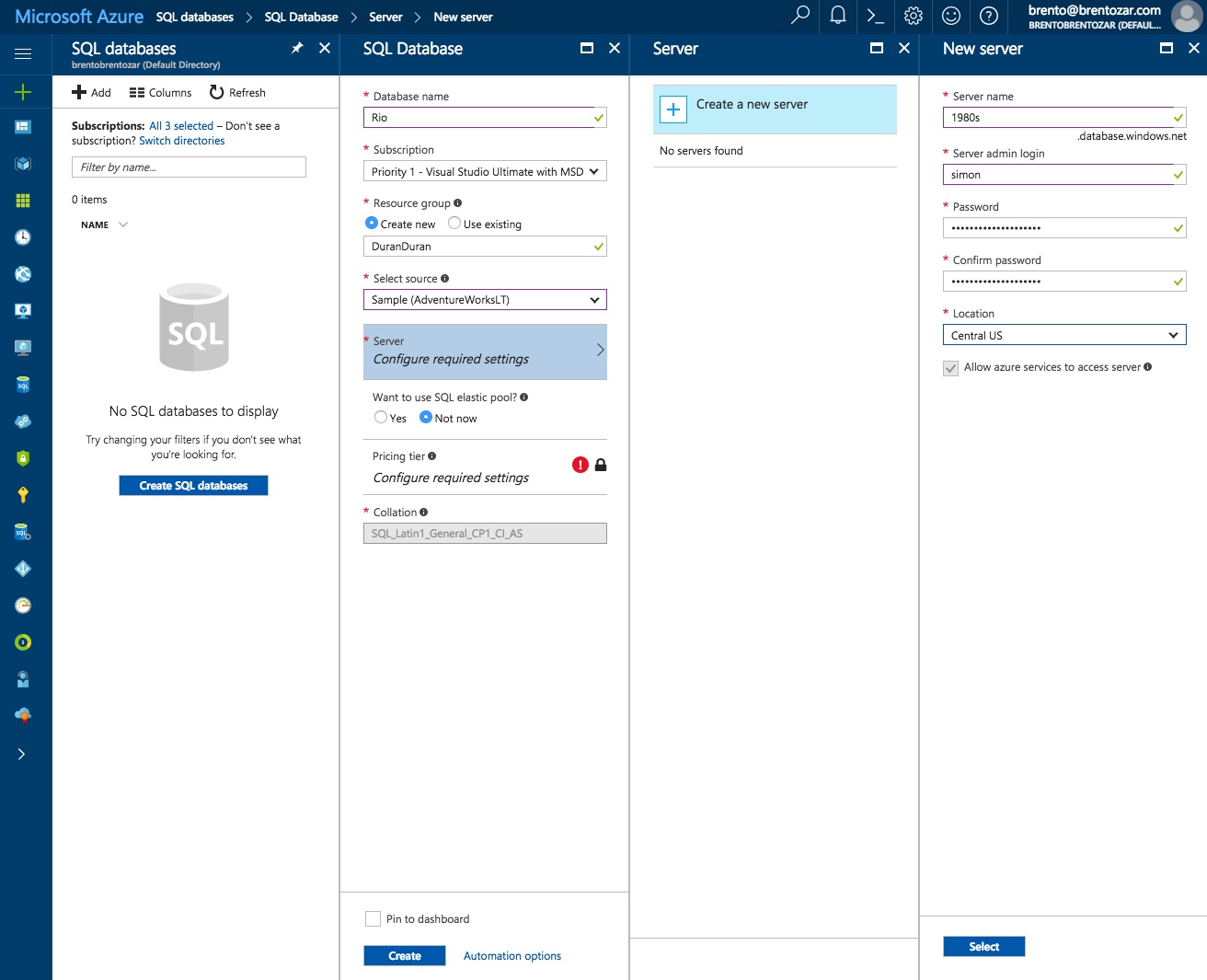
In the Azure portal, go into SQL databases, and click Create database. Since it’s my first database in this subscription, I’ll also have to create a server. (You might think pricing/sizing would be tied to the server, but it’s not – it’s actually tied to the database.)
In this screenshot, I’m in the midst of creating my new database, but I have to create the new server first. The Azure portal has this weird left-to-right navigation where modal dialog boxes appear on the right. Even though you can still edit stuff on the left, like the database, you have to finish creating the stuff on the right before you can move on:
After configuring my server, I’m asked how fast I want it to go:
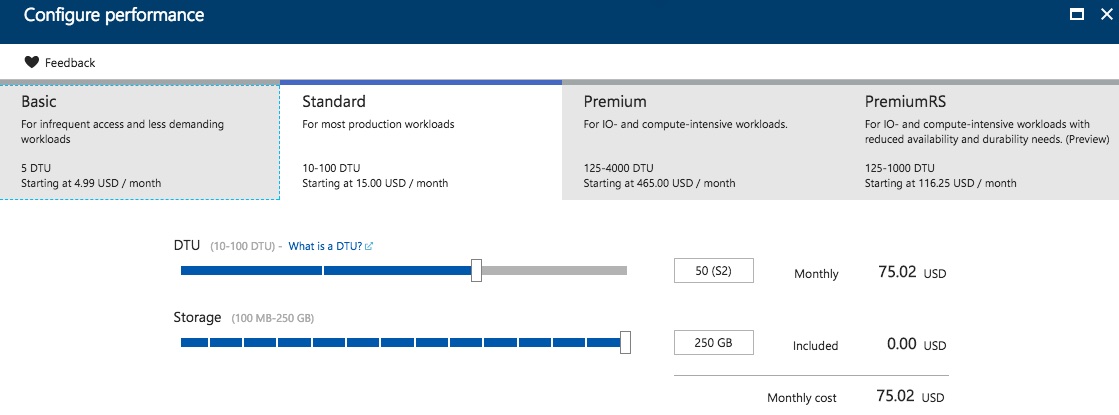
Performance sizing isn’t the point of this post – we’re talking about point in time backups and restores – but the performance tiers can affect your backup/restore choices:

I love how Azure SQL DB has the same backup retention across the upper tiers, kinda like how they make the same security options available across the board. They’re not trying to Enterprise-Edition you up into higher tiers by restricting basic features from Standard.
One drawback: if you want more than 35 days of backup history, you’re about to meet my friend from Spain, Mañuel Labor. You’ll need to export the data, restore it to another server, etc.
I’ll go with the defaults here of a Standard S2 with 50 DTU, 250GB data, since I’m not worried about performance.
After I click Create, the server and database takes a few minutes to deploy.

While that happens, I’d like to point out what the wizard didn’t mention:
- Backup schedules & frequencies
- Backup destination & redundancy
- Corruption checking schedules
- Security & firewalls (more on that in a minute)
2. Set up point-in-time backups.
Well, dear reader, this step is going to be a bit of a letdown in Azure SQL DB.
After the deployment finishes, if you go into database properties, there’s nothing about backups:

Even if you use the search for backup:
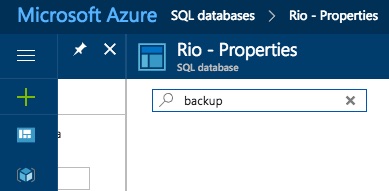
This is one of the things I love about Platform as a Service (PaaS): it’s a new religion. The worst piece of drudgery about database administration, the thing you hate the most – protecting them – is simply not your problem anymore. It’s Microsoft’s problem.
Even encryption is just taken care of by default. Click on Transparent Data Encryption, and:
TDE doesn’t even merit capital letters anymore. It’s just plain transparent data encryption.
3. Create a table with some stuff in it
Because it’s our Builder Day, and I feel like learning things, I’m going to:
- Install Microsoft’s free open source Visual Studio Code on my Mac
- Install the SQL Server extension (control-shift-P or F1, then Install Extension, and type mssql, then restart VSC)
- For more details, follow these instructions to get started connecting to SQL Server
After installing the extension, I can hit F1 and type in SQL, and get options:

I thought I wanted to Connect, but hold back the rain – that user experience is actually painful. Then I tried with Manage Connection Profiles, and things got – well, the best way is to show you:
It turns out that to connect to SQL Server, you also have to install openssl, then .NET Core, then restart Visual Studio Code.
Next, you’ll get an error about not having the firewall open:

Unless you have the world’s largest monitor, you can’t see the entire alert, but the short story is that you have to go into the Azure Portal, hamburger menu, SQL Servers, click on your server, click Firewalls, and add your IP to allow remote access.
A brief word about security
“Wait a minute,” you might be saying to yourself, “can’t I VPN into Azure or something to access Azure SQL DB? Am I really about to open up access to the outside world?”
Your request is important to us, please hold:
For now, I’ll just open up my Azure SQL DB to my home IP address.
Back to creating a table with some data in it
I used to use a char(8000) field to stuff a lot of data in fast, but ever since I saw Erik using sys.messages to create a lot of junk fast, I’ve been a convert:
|
1 2 3 4 5 6 7 8 9 |
WHILE 1 = 1 BEGIN SELECT * INTO dbo.ABillionStars FROM sys.messages; DROP TABLE dbo.ABillionStars; END GO |
I’m just dumping a bunch of data into a new table then dropping it, over and over. This database isn’t going to grow after the first insert, but the change rate is going to mean that I should see backups happening on a pretty regular basis.
Here’s what it looks like in Visual Studio Code:

While it runs, I’ll check the server’s wait stats with sp_BlitzFirst @ExpertMode = 1:

And Eureka! We have a poison wait detected, which means our SQL Server is going to feel like it’s locked up or slowed down across the board. In on-premises boxes, common examples are RESOURCE_SEMAPHORE or THREADPOOL, but here it’s LOG_RATE_GOVERNOR. Azure is limiting our queries because we’re using too many resources.
(Frankly, that’s fair, right? What kind of moron has two thumbs and dumps sys.messages into a table over and over? This guy!)
When I go into the Azure portal to see what’s up, Microsoft politely points out that my DTU usage is rather high:

If I drill into details, I get a Query-Store-driven dashboard of my top queries, and you can guess which query it is – but I digress.
4. Make sure backups are happening.
I don’t get to see a list of backups in Azure SQL DB, but I’m a little paranoid. I wanna check via wait stats to see if SQL Server’s spent any time waiting on backups. Even with super-fast storage, backups usually pop up in wait stats.
To see, I’ll run sp_BlitzFirst @SinceStartup = 1, which works fine in Azure SQL DB and gives me wait stats since, uh, startup:
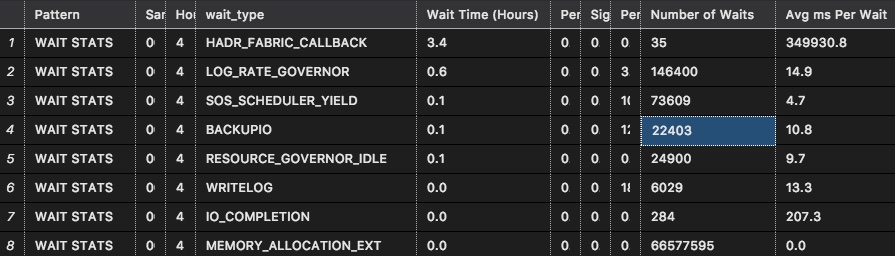
The HADR_FABRIC_CALLBACK wait is undocumented (listed as “TBD”), but given that Always On waits typically start with HADR, it’s gotta have something to do with data protection. I’m not gonna call that one backup, though.
LOG_RATE_GOVERNOR is SQL Server giving us the hand, telling us to slow down our writes.
SOS_SCHEDULER_YIELD indicates CPU issues, so I’ll set that aside.
Coming in at #4, we finally have BACKUPIO. There have been 22,403 times where SQL Server has waited on backups, albeit only 10.8ms, which is pretty doggone quick. I’m just happy to see any backup waits at all, which means my data’s probably going to be protected. I’m a trusting guy.
5. Do a point-in-time restore.
My little load query has been running for about half an hour straight, so I’m going to click on Restore at the top of the window, and the fun starts:

Here’s where things start to get a little different: restores are a new database.
First, you don’t restore over the top of an existing database on the same server. If you want the same database name, you’ll need to drop the old database first, or restore to a different server.
Second, this also means that you’re paying for a new database – see the Pricing Tier option at the bottom? Your restore could be on a faster or slower tier. If you need to restore production databases into a dev/test server, this is really handy. (This can also be a bit of an eye-opener for folks who didn’t realize that there’s no such thing as a “free” Development Edition database in Azure SQL DB once you’re over your monthly free credits. That’s totally fair, too – cloud hardware still costs money.)
The restore point is also a little confusing: the monitoring graphs are in local time, the oldest restore time is in 24H UTC, and the restore point time entry form is in 12H UTC. Just type in the recovery point time you want – any point of seconds is available. You’re not restricted to 15-minute-increments or anything like that.
Next, the Azure portal shows a little popup with status:
My database restore is off and running. (And when the restore finishes, that new database will have automatic backups too, all without me lifting a finger.)
After 9 minutes, my newly restored database was available for queries.
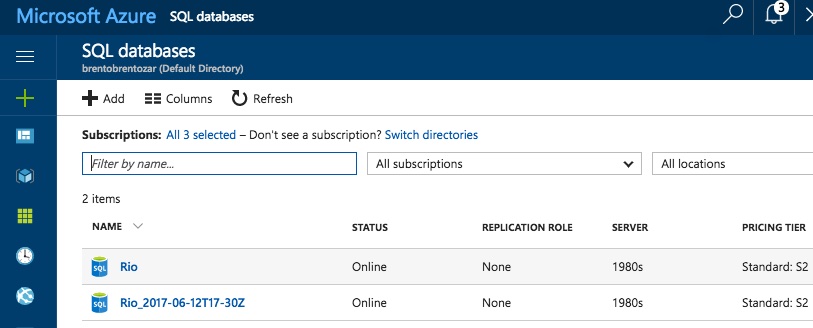
How long will your restore take?
In the documentation, Microsoft writes:

That’s completely fair, but here’s the thing: with Azure SQL DB, you don’t know most of that data. You’re not going to know how many logs, the amount of replay, the amount of network bandwidth, or the number of concurrent restore requests.
You don’t get a percentage completion in the portal, and you can’t check DMV tools like sp_WhoIsActive because the database isn’t available yet.
What I learned (or remembered) today
The Azure Portal is still fingernails-on-chalkboard. The billing, subscriptions, and permissions setup is a complete pain in the butt, but – how often do you actually do that? Almost never. (Except today, when I had to add Erik and Tara into my Azure account, and I flipped a table.)
Creating a database still has some awkwardness around creating a server first. The “server” concept feels artificial because it’s not useful for much – there’s no three-part-name cross-database queries allowed, and it’s not like you get Agent jobs.
But once the server & database are up, backups are a hassle-free dream. Love it. Two slight exceptions:
- Backup space is 2x your database size. If you have a high change rate (like my absurd demo query), you’ll need to buy more storage space or retain less backup history. See the FAQ for details.
- If you want >35 days of backups, you’ll need to export the database contents, like to a BACPAC. If you want transactional consistency in that copy, you’ll need to copy the database first, then export the copy. Small price to pay though.
Restores are super-easy, but not necessarily fast or measurable. But hey, that’s the cool part about the cloud – the restore speed is somebody else’s problem. If your boss is pissed about how slow the restore is going, you just conference them in with your Microsoft support rep while you do other stuff. (Is that how the cloud works? I think that’s how the cloud works.)
And hey, Visual Studio Code is making progress! Not quite a bird of paradise yet, and I think I’ll stick with SSMS in a VM, but it’s coming along.

14 Comments. Leave new
For completeness and as a comparison, would you consider also including a a wrap-up article which compared the cloud approaches to the unmanaged, native SQL approach? As an example, I would probably compare point in time restore to backup/restore using Full Recovery Mode. I admit that for many tasks, the unmanaged alternative will be trivial or unsupported.
Brian – that’s a great idea for you (or another blogger) to take on, actually! It’d be really cool for someone else to pick up and continue where we left off. We won’t be blogging the native approach though – we already know that one well, and it takes us about a day per blog post to knock these kinds of in-depth ones out.
Just a small detail to consider. This auto backup-restore feature doesn’t prevent and protect you from the database corruption. so you are still responsible for running DBCC CHECKDB and reacting to it’s results(according to MS documentation). And if corruption happens as I understand all backups will be also corrupted. So it is not clear how to maintain DR process in case of azure. Do you have any thoughts on this?
Denis – if Azure SQL DB corrupts your data, you’d want to open a support ticket with Microsoft. Right now, they don’t give you the ability to do things like page level restores.
Azure point in time backups know they’re something special and they look like they’re the best.
Richard – nicely done, sir.
Is there a performance impact on the source db while the restore is taking place?
Jon – for Q&A, head on over to https://dba.stackexchange.com
Also if your primary db is georeplicated, and you are planning to rename the newly restored DB to old db name, then you have to stop replication first. Next rename the restored db to your old db name. And now when you want to restart the georeplication, you get another surprise. You cannot replicate to an existing db. So basically you have to drop the replicated db & start a new geo replication. So though the backup is taken care of, Restore is cumbersome. But then, there are no free lunches, right!
And am not even thinking of cases where you just need to update few rows & not entire db.
is there anything else we need to care about while doing Point in time restore?
For example, from an operations perspective, are there other tiers of the application that we need to “pause” to prevent them from generating errors when attempting to perform reads or writes while the database is being restored?
Ali – that’s really a question for your own team and application.
Thank You Brent Ozar.
So how do we tell if the point in time “time” is our standard local time or Greenwich time? When I first open the restore database page, it defaults the time to 8 hours ahead. I’m on PST Pacific standard and so 8 hours ahead would be Greenwich. If I manually enter in my local point-in-time, will Azure recognize that as PST or Greenwich? Thanks.
Nevermind, I see UTC (Greenwich) is referenced on the azure database restore page.