Don’t Use Scalar Functions in Views.
3 Comments
The short story: if your view has a scalar user-defined function it it, any query that calls the view will go single-threaded, even if the query doesn’t reference the scalar function. Now for the long story.
Quite often people will inherit and rely on views written back in the dark ages, before people were aware of the deleterious effects that scalar valued functions can have on performance.
Of course, for some people, it’s still the dark ages.
Sorry, you people.
Questions and answers
So what are the side effects of relying on an old view that has scalar valued functions in it? Well, it depends a little bit on how the view is called.
We all know that scalar valued functions are executed once per row, because we all read my blog posts. Well, maybe. I think the CIA uses them instead of waterboarding. Not sure how much they make it out to people not classified as enemy combatants.
But what about if you call the view without referencing the function?
It turns out, it’s a lot like when you use a scalar valued function in a computed column. Let’s look at how.
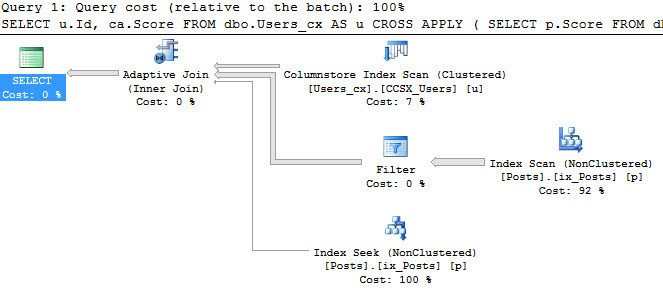
We’re gonna need a function
|
1 2 3 4 5 6 7 |
CREATE FUNCTION dbo.ScalarID ( @Id INT ) RETURNS INT WITH RETURNS NULL ON NULL INPUT, SCHEMABINDING AS BEGIN RETURN 2147483647 END; |
Let’s stick it in a view, and watch what happens next.
|
1 2 3 4 5 |
CREATE VIEW dbo.FunctionView AS SELECT TOP 1000 *, dbo.ScalarID(u.Id) AS [DumbFunction] FROM dbo.Users AS u |
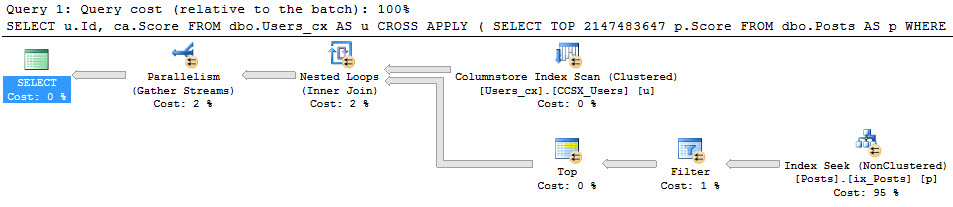
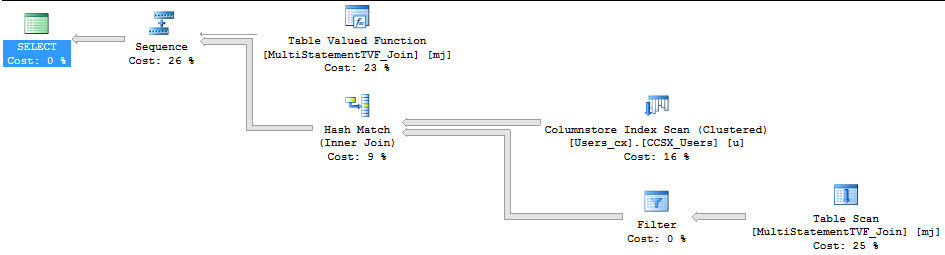
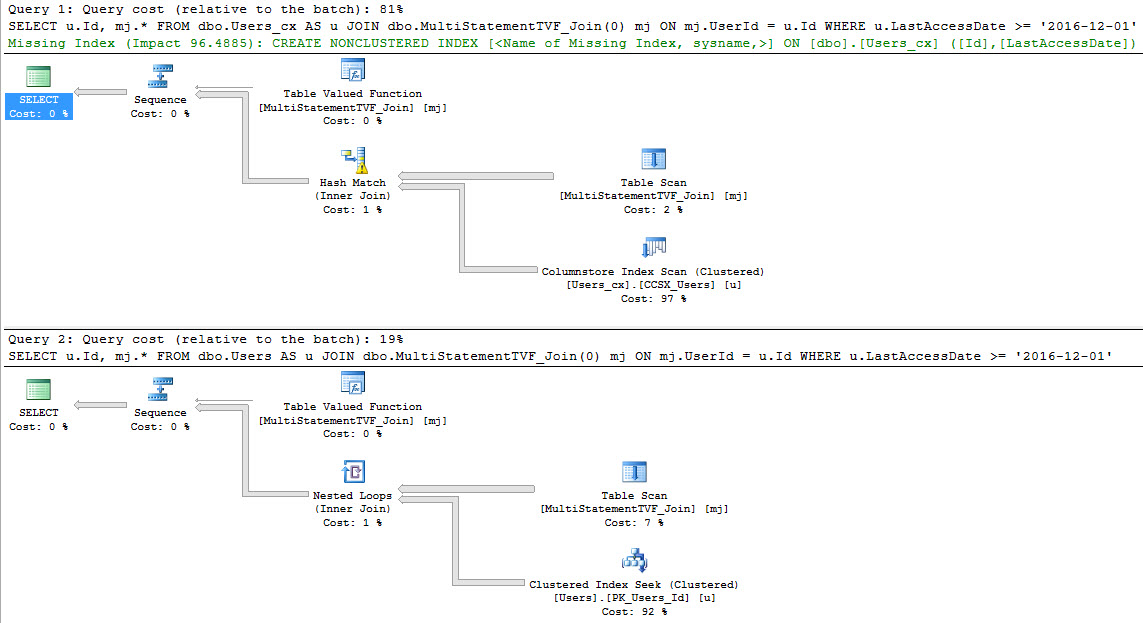
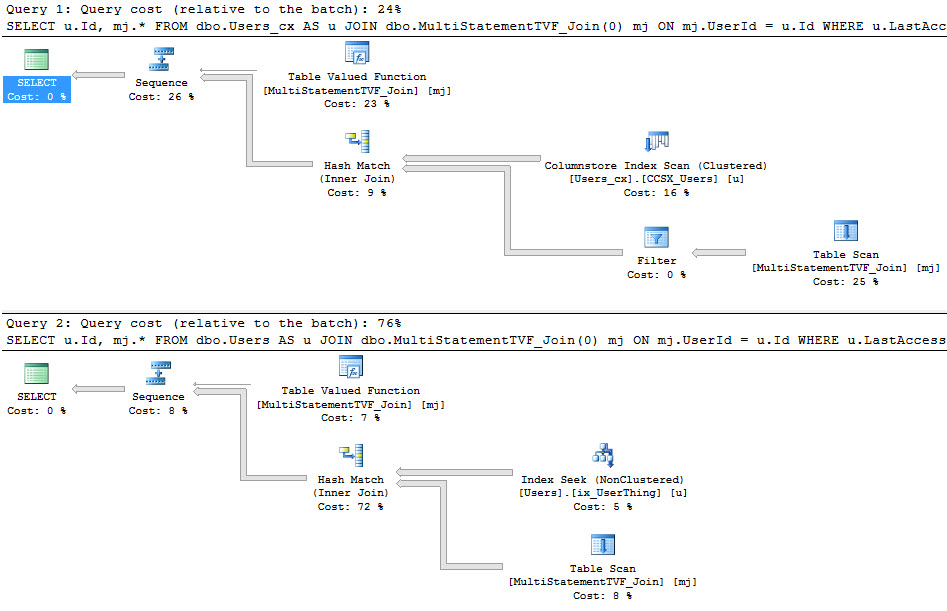
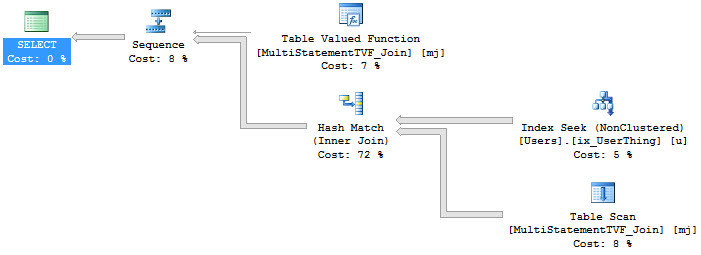
There’s a difference when we avoid selecting the column that references the scalar valued function.
|
1 2 3 4 5 6 7 |
SELECT fv.Id --No function reference FROM dbo.FunctionView AS fv SELECT fv.Id, fv.DumbFunction --Function reference FROM dbo.FunctionView AS fv EXEC master.dbo.sp_BlitzCache @DatabaseName = 'StackOverflow' --A Blitz of Caches |
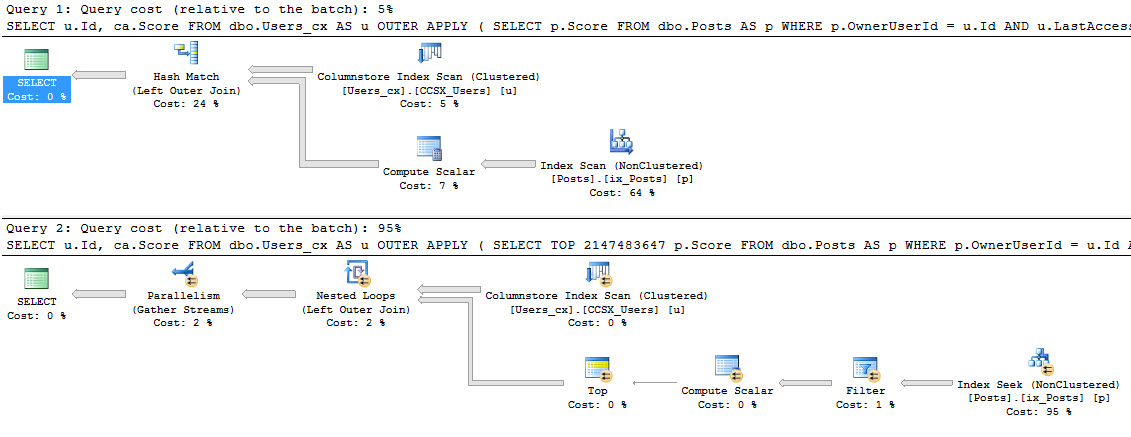
So what’s the difference?

Well, both queries are forced to run serially because of the scalar valued function. That warning is surfaced in sp_BlizCache in not-decade-old versions of SQL Server.
But only the query that referenced the scalar valued function directly picked up the overhead of the row-by-row execution of the function. This is proven out in the ‘# Executions’ column.
The function was called 1000 times, not 2000 times. Our TOP 1000 view ran twice, so if the function had run for both, it would show 2000 executions.
There’s still a problem here
Both queries are forced to run serially. If you have a big bad view that does a lot of work, and performance is important to you, you probably won’t want it to run single-threaded because of a silly function.
This doesn’t give scalar valued functions (in general, or in views) a pass, but you can avoid some of the overhead by not referencing them when you don’t need to.
Thanks for reading!