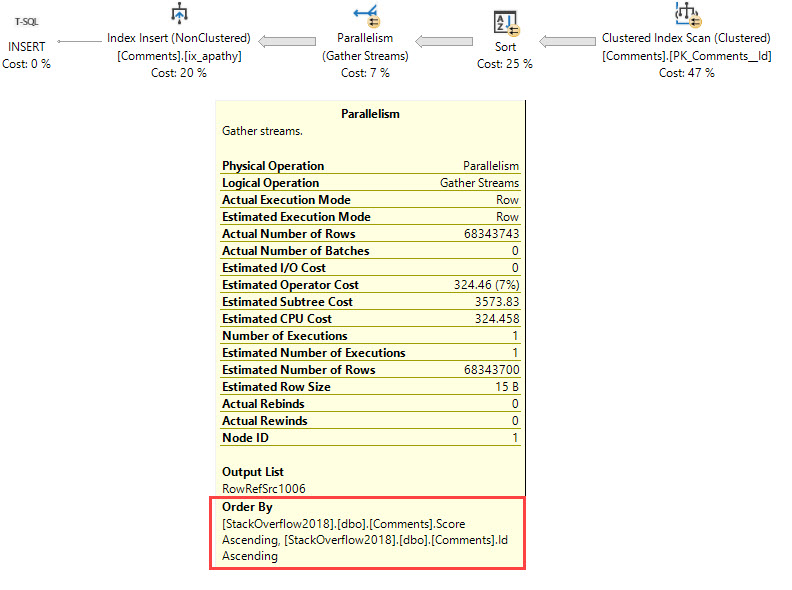
The 2019 Data Professional Salary Survey Results
11 Comments
How much do database administrators, analysts, architects, developers, and data scientists make? We asked, and 882 of you from 46 countries answered this year. Y’all make a total of $84,114,940 USD per year! Hot diggety. (And at first glance, it looks like on average, y’all got raises this year.)

Download the 2019, 2018, & 2017 results in Excel.
A few things to know about it:
- The data is public domain. The license tab makes it clear that you can use this data for any purpose, and you don’t have to credit or mention anyone.
- The spreadsheet includes the results for all 3 years. We’ve gradually asked more questions over time, so if a question wasn’t asked in a year, the answers are populated with Not Asked.
- The postal code field was totally optional, and may be wildly unreliable. Folks asked to be able to put in small portions of their zip code, like the leading numbers.
Hope this helps make your salary discussions with the boss a little bit more data-driven. Enjoy!