
How Azure SQL DB Hyperscale Works
Microsoft is starting to talk about the internals for Azure SQL DB Hyperscale, their competitor to Amazon Aurora. Aurora took the open source MySQL and PostgreSQL front ends and hooked them up to much more powerful cloud-first storage engines on the back end. Here’s a quick primer on how Microsoft is doing something similar – taking the front end of SQL Server (the query optimizer and query processor), and hooking them up to a new back end.
When your database server runs on physical hardware, it looks like this:

- CPU: an Intel or AMD processor where the database engine’s code runs
- Memory: caching layer
- Data file: a file on local storage where your data lives, the main source of truth for your database
- Log file: a file on local storage where the database server writes what it’s about to do to the data file. Useful if your database server crashes unexpectedly, leaving the data file in a questionable state.
- RAID card: a processor that stores data on a Redundant Array of Independent Drives.
(I’m making some assumptions here, like enterprise-grade hardware with redundancy, because that’s the kind of gear I usually see backing SQL Server. You, dear reader, might be a rebel running it on an old Raspberry Pi. Whatever.)
Traditional database server high availability
Usually when DBAs sketch out a failover architecture, the drawing involves duplicating this diagram across several independent servers. Data is kept in sync by the database server (SQL Server, Postgres, MySQL, Oracle, etc) by having the database server replicate logged commands over to other replicas:

That works.
A way less popular method (but still technically possible) involves separating out the database server from its file storage. You can put your databases on a file server, accessible via a UNC path.
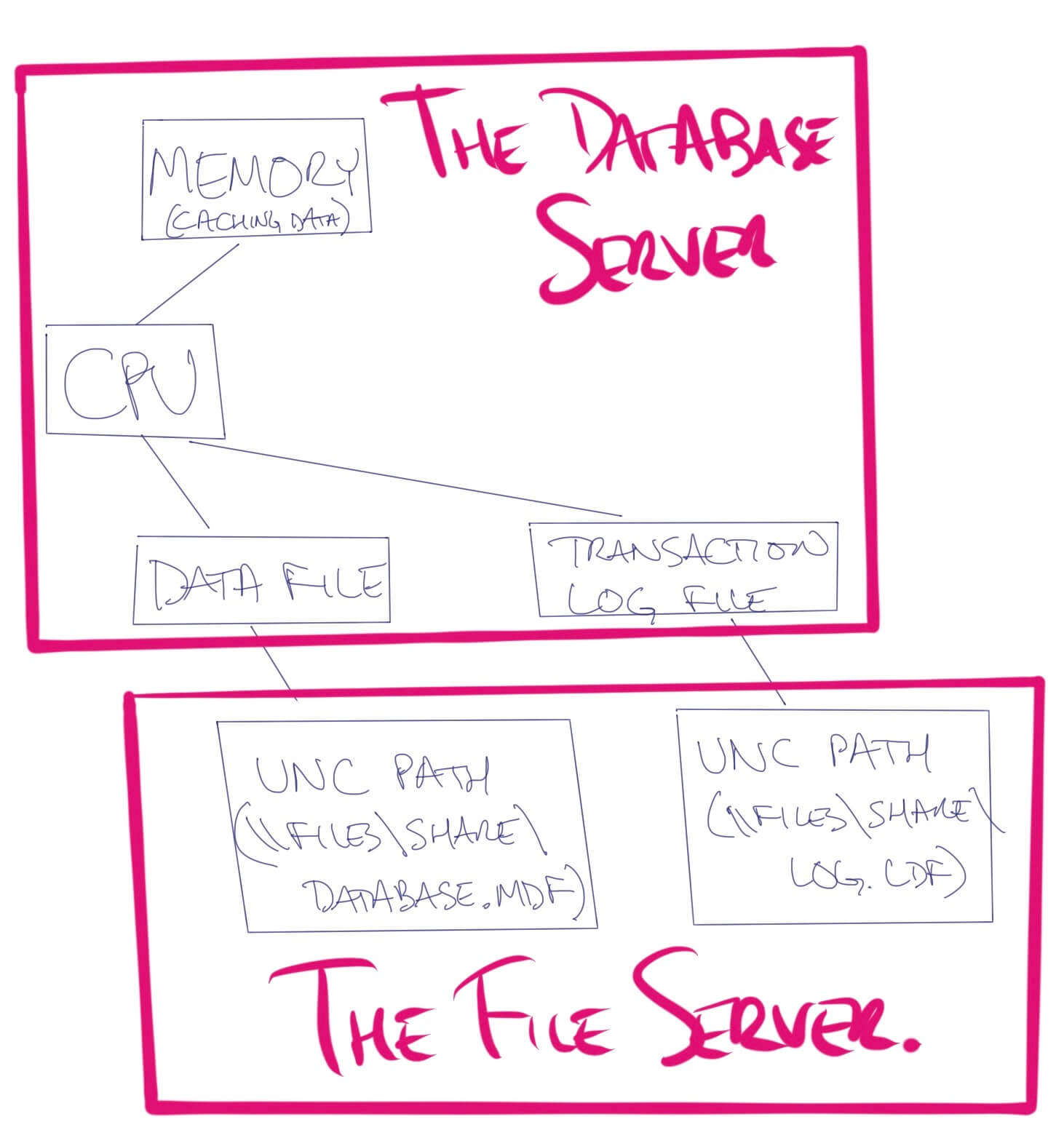
That way, if the database server blows chunks, you could spin up another database server, attach the data & log files, and keep right on truckin’. This is a fairly unusual approach these days, though, due to challenges with networking, slow time to spin up another database server, etc.
But what if you were going to redo this for the cloud?
Conceptually, separate out the storage.
The RAID card’s responsibilities are:
- Accept incoming writes, and temporarily store them in a limited amount of very fast cache (think near memory speed, but safe in the event of a crash or power loss)
- Later, dispatch those writes off to persistent storage (hard drives or solid state)
- When asked to read data, figure out which drives hold the data
- Try to cache data in fast storage (like if it notices a pattern of you asking for a lot of data in a row)
- Monitor the health of the underlying persistent storage, and when a drive fails, put a hot spare drive into action automatically
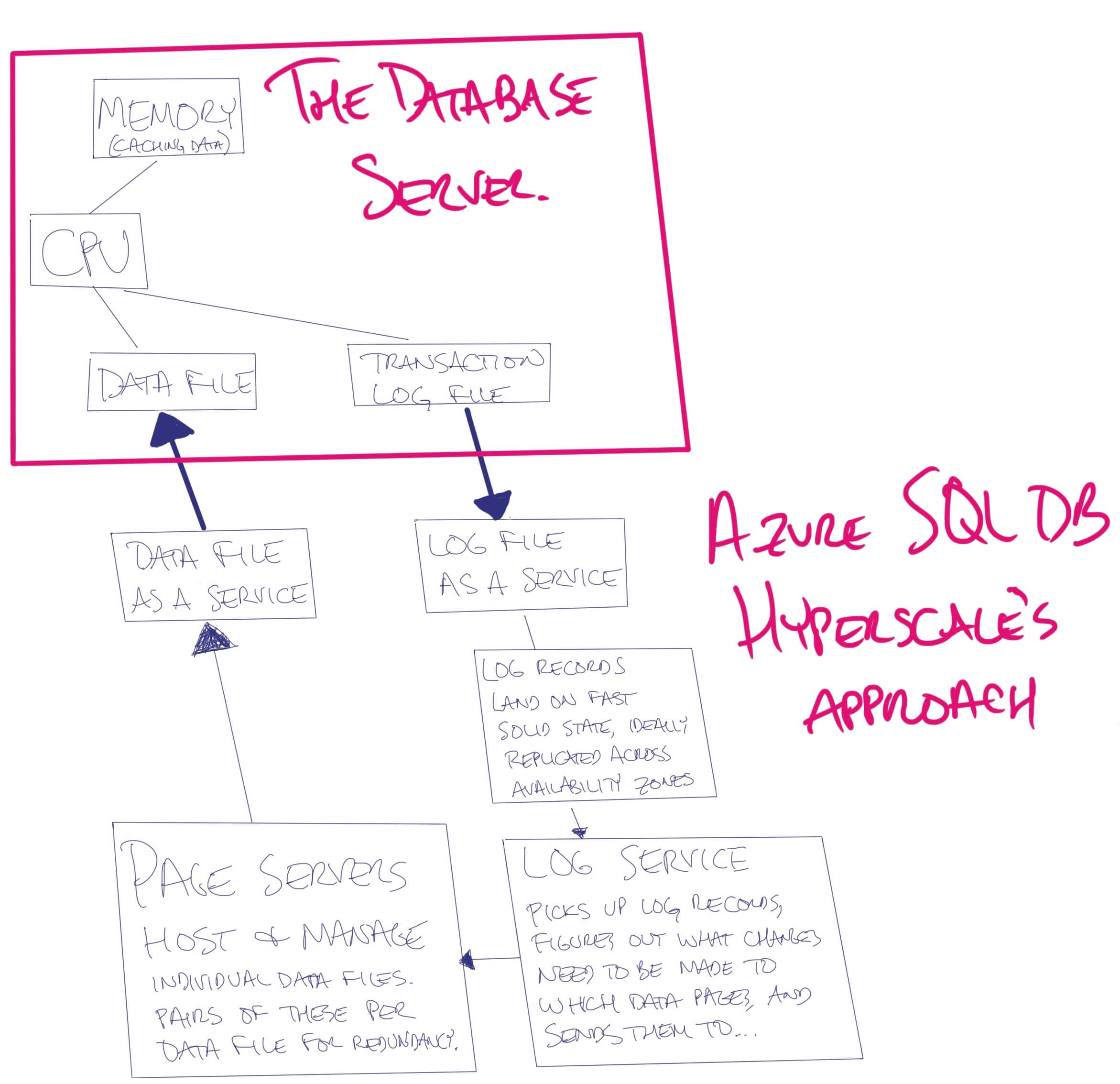
In our new cloud design, we’re going to build up a beefier storage subsystem. We’re going to replace the RAID card with a bigger design, and in this bigger design, we’re going to give the storage some more job duties than it had before (moving up the stack into the database server’s job duties.) We’re going to:
- Break this data up into a few network services (which, honestly, are probably going to be a little slower than the absolutely best-configured local flash storage, but faster than poorly configured shared storage)
- Replicate the database across multiple data centers (without getting the database server involved)
- Make the storage responsible for applying the transaction log changes to the data file
Here’s how the architecture would look:

- CPU: (an Intel or AMD processor) a virtual machine where the database engine’s code runs
- Memory: local solid state caching layer
- Data file: a file on local storage a service where your data lives, the main source of truth for your database
- Log file: a file on local storage a service where the database server writes what it’s about to do to the data file. Useful if your database server crashes unexpectedly, leaving the data file in a questionable state.
- RAID card: a processor service that stores data on a Redundant Array of Independent Drives.
When you do an insert, conceptually:
- The database engine’s query processor tells the log service, “I want to add a row on data file #1, page #300.”
- The insert is considered done as soon as that command is written to the log service.
- The log service reads the list of work to be done, opens up data file #1, page #300, and adds the relevant row.
This comes with some interesting advantages:
- The primary replica needs less storage throughput since it’s not writing changes to the data file.
- The log service can make the necessary data file changes in multiple copies of the data file, even in multiple data centers or even continents.
- You can add more databases and more replicas of each database with zero additional overhead on the query processor. If you’ve ever dealt with worker thread exhaustion on Availability Groups, or sync commit latency due to an overloaded replica, you’ll know how cool this is.
- We can scale data file storage linearly with servers using cheap local solid state storage.
Here’s how Azure SQL DB Hyperscale does it.
In a conventional SQL Server, for large databases, you might create multiple data files, and put each data file on a separate volume.
In Hyperscale, Microsoft does this for you automatically, but in a spiffy way: when you see a data file, that’s actually a different page server. When the last page server is ~80% full, they’re adding another page server for you, and it appears as a new data file in your database. (Technically, it’s two page servers for redundancy.)
Challenges for both Aurora and Hyperscale (I hesitate to call these drawbacks, because they’re fixable):
- If we’re running our database today on a physical server with a perfectly tuned IO subsystem, we could get sub-millisecond latency on writes. Let’s be honest, though: most of us don’t have that luxury. For Azure SQL DB Hyperscale, Microsoft’s goal is <2.5 milliseconds for log writes, and as they roll out Azure Ultra SSD, the goal is dropping to <0.5ms.
- We’ll lose some database engine features that relied on directly working in the data file – for example, right now Hyperscale doesn’t offer Transparent Data Encryption or bulk logged recovery model.
- Caching is going to be just a little bit trickier. The primary replica may still need to make its own changes to the in-memory cached data pages because people are going to want to insert a row, then immediately turn around and query that same row, without waiting for the log service to make changes to the data pages, plus have the primary fetch the newly updated copies of the data pages from cache.
- We’ll have a lot more complexity. There are a lot of new moving parts in this diagram, and if we want them to be reliable, we’re likely going to run them in pairs at a minimum. All of these moving parts will need controls, diagnostics, and patching. (This just doesn’t make sense to run on-premises for the next several years unless it’s a sealed appliance like Azure Stack or Amazon Outpost.)
- We’re going to spend more money in the short term. I bet some of you are reading this diagram and going, “Holy Licensing, Batman, this is going to be a lot more expensive (and somewhat slower) than my 2-node Availability Group running SQL Server Standard Edition on $1,000 Intel PCIe cards.” And you’re right. It’s not a good fit to replace that. There’s a reason Microsoft calls it “Hyperscale.” Stick with me here.
Both AWS Aurora and Microsoft Azure SQL DB Hyperscale take the same approach here, offloading deletes/updates/inserts to a log service, and then letting the log service change the data file directly.
The next level: scaling out the compute
A few paragraphs ago, I said that the log service could add more databases and more replicas of each database with zero additional overhead on the query processor. Well, why not take advantage of that?
In Azure SQL DB Hyperscale, this is done with an Always On Availability Group listener. When application wants to query a readable replica, the app specifies ApplicationIntent=ReadOnly during their connection, and they’re automatically redirected to one of the readable replicas.
Similarly, in AWS Aurora, applications connect to a different DNS name for read-only connections. AWS has an interesting feature: for some kinds of queries, Aurora will parallelize your query across multiple readable replicas. The DBA in me loves that, but at the same time, if your queries are so rough that you need multiple replicas to accomplish ‘em, you’re already sitting on a ticking time bomb: you’re not going to be able to run a lot of those simultaneously, and AWS charges you for each IO you perform. This is throwing money at bad queries – but hey, sometimes that makes sense.
Caching is of course a little trickier here. With traditional SQL Server Availability Groups, the database engine is receiving each log change, so it knows which pages need to be changed, and there’s no danger of it serving stale data from cache. Now, with the data pages being changed by the log service, there’s a risk that the replica could serve stale data. Me personally, I’m not too worried about that because that was always a possibility with Availability Groups, too. (Async replication traffic can get delayed (or even suspended), and the replica can get behind in applying changes.)
This design has a huge advantage: the replicas don’t need to talk to each other, nor do they need to be physically nearby. As far as they’re concerned, they’re just reading from data and log files. They don’t need to know anything about the magical Internet beans that are refreshing the data and log files right underneath them.
Who should consider Hyperscale and Aurora?
If all of these match, talk to your doctor about AWS Aurora or Azure SQL DB Hyperscale:
- You have an existing app with a MySQL, Postgres, or SQL Server back end
- The workload of your read-only queries is high enough that it mandates spreading the load across multiple servers (either to make the read-only queries faster, or to free up the primary server to make the writes faster)
- Your read-only queries can live with data that’s seconds behind
- You can’t implement caching quickly enough or cost effectively enough
- Your primary bottleneck isn’t writing to the transaction log (or if it is, your log writes are currently 2ms or longer)
- You’re willing to gamble on the vendor’s support (because you ain’t doing any fixing on these technologies – either they work, or you’re filing a support ticket, but there’s nothing in between)
I’m a huge fan of this architecture. We picked AWS Aurora when we built SQL ConstantCare a few years back, but only because there wasn’t anything like Azure SQL DB Hyperscale at the time. Today, I’d have a much tougher time making that decision.
For the record, I’m writing this as an interested database geek, not as a sales or marketing pitch. We don’t specialize in Aurora, MySQL, Postgres, or Azure SQL DB Hyperscale – I’m just sharing it because I find the products really interesting. If you want to learn more about this stuff, here’s where to go next:
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases (PDF) – detailed white paper explaining the problems with current database storage, and how they ended up with Aurora’s solutions. The solutions are similar enough to Hyperscale that Microsoft DBAs will still find it a useful resource.
- Azure SQL DB Hyperscale documentation – I know, I hate linking you to the manual, but this thing is so honkin’ new that there’s hardly any public documentation on it. The Hyperscale product manager, Kevin Farlee (@kfarleee), had a phenomenal slide deck on it at SQL Intersections in Vegas, but it’s not public yet. (Hey, that’s why you go to conferences!)
- AWS re:Invent videos: Deep Dive on Aurora MySQL and on Aurora Postgres
Oh, and the diagrams – Apple Pencil, iPad Pro, and the Procreate app. Highly recommended. I can’t promise that my art quality will get any better, but I’ll do more of these to illustrate concepts. It’s fun!

12 Comments. Leave new
Just a warning that converting a database to hyperscale is currently a one-way conversion (from https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale) :
Migration to Hyperscale is currently a one-way operation Once a database is migrated to Hyperscale, it cannot be migrated directly to a non-Hyperscale service tier. At present, the only way to migrate a database from Hyperscale to non-Hyperscale is to export/import using a BACPAC file.
Even though TDE is currently available, would the underlying storage be encrypted?
Mike – that would be a question for Microsoft.
I asked and this was their response. “Yes. Both data files/page servers and transactional log are encrypted.”
By default, data at rest, on Azure Blob, is encrypted.
I have 1 “large” db, about 6TB and and 48 other databases that communicate with this 6 TB database.
what might be a best solution for using HyperScale and Azure Databases.
That’s exactly the kind of design I do in consulting. Feel free to click Consulting at the top of the site to learn more.
Excellent blob Brent .. APPRECIATE THE comparison with AWS aurora
Hi, It is indeed a very helpful article. I wold really appreciate your help to understand my issue.
1. We have implemented Azure Hyperscale.
2. Application is able to access the DB successfully.
Problem: We are unable to connect to the DB from a SQL Management studio like DBeaver.
Error: The TCP/IP connection to the host XXX.worker.database.windows.net, port ** has failed. Error: “connect timed out. Verify the connection properties. Make sure that an instance of SQL Server is running on the host and accepting TCP/IP connections at the port. Make sure that TCP connections to the port are not blocked by a firewall.”.
Do we already know any issues connecting to the Hyperscale from the sql tools?
Nikhil – for support questions, go ahead and check with a Q&A site like https://dba.stackexchange.com or contact Microsoft.
Trying to follow the diagrams, but I don’t see the unicorns.
Sorry…..
This seems more of a catch up with Snowflake’s architecture than it does for Aurora, although they are all taking a similar approach to cloud-first database scaling.