Can deleting rows make a table…bigger?
21 Comments
Michael J. Swart posted an interesting question: he had a large table with 7.5 billion rows and 5 indexes. When he deleted 10 million rows, he noticed that the indexes were getting larger, not smaller.
Here’s one way that deletes can cause a table to grow:
- The rows were originally written when the database didn’t have Read Committed Snapshot (RCSI), Snapshot Isolation (SI), or Availability Groups (AGs) enabled
- RCSI or SI was enabled, or the database was added into an Availability Group
- During the deletions, a 14-byte timestamp was added to each deleted row to support RCSI/SI/AG reads
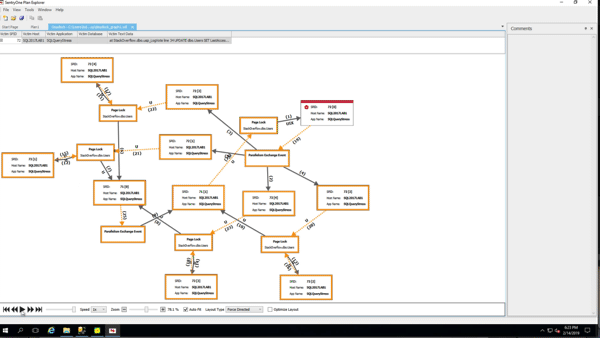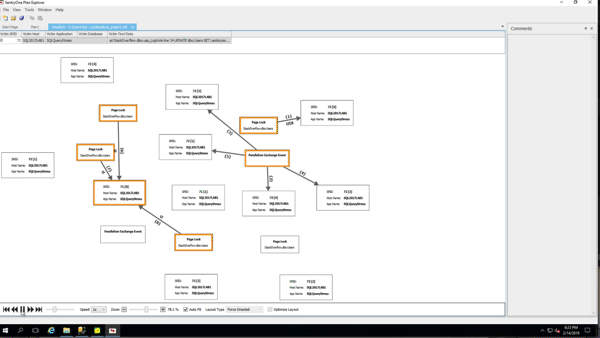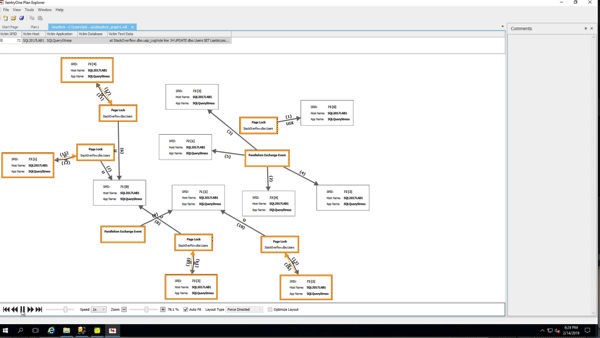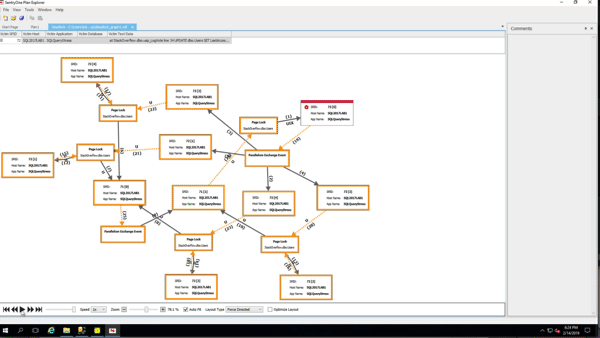
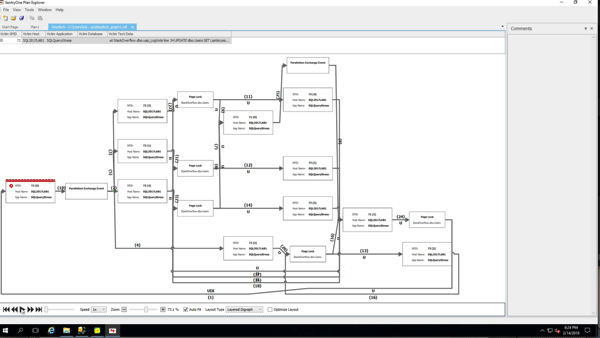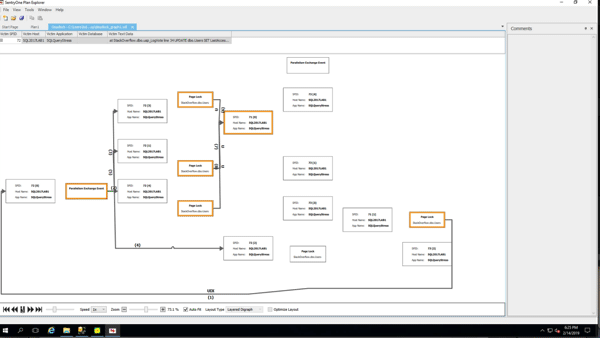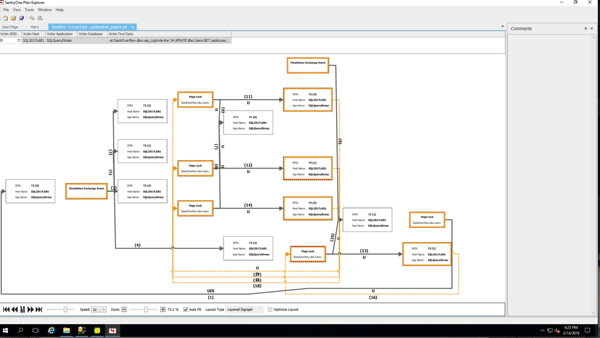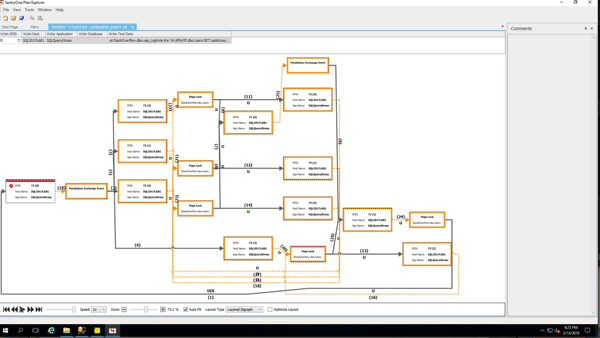
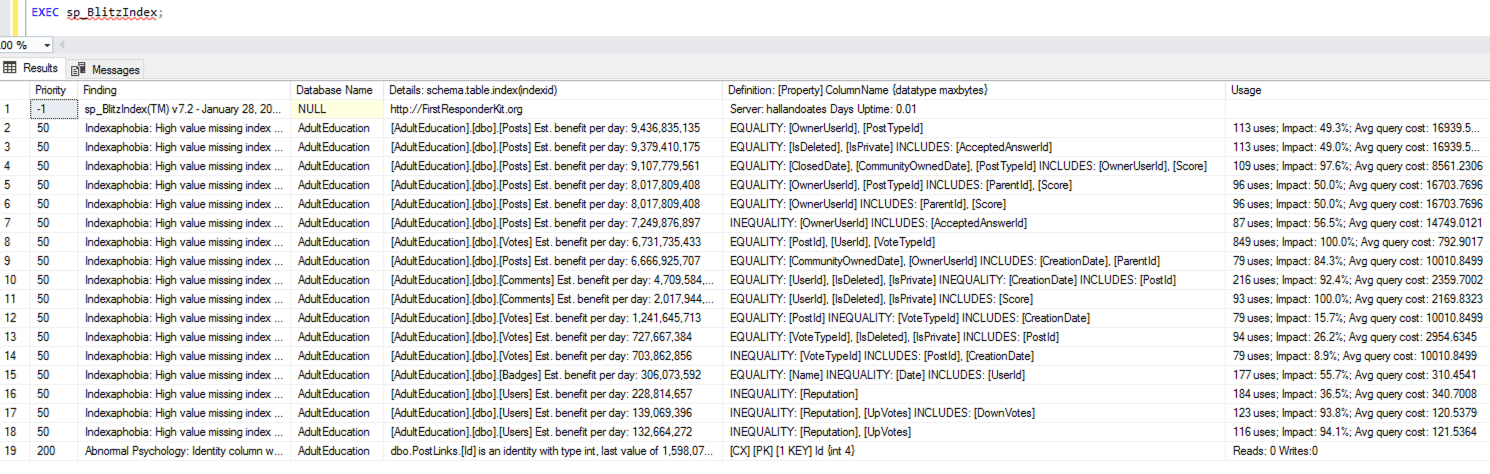
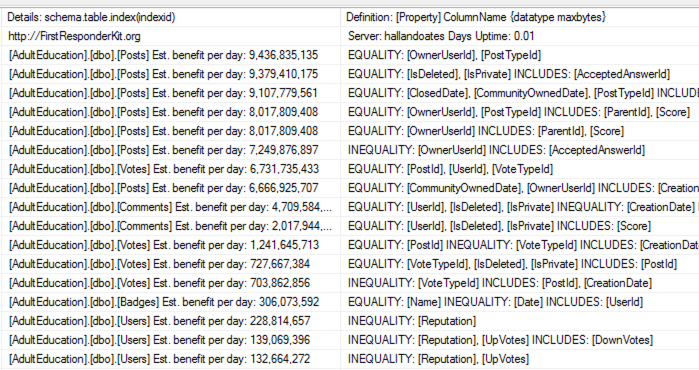
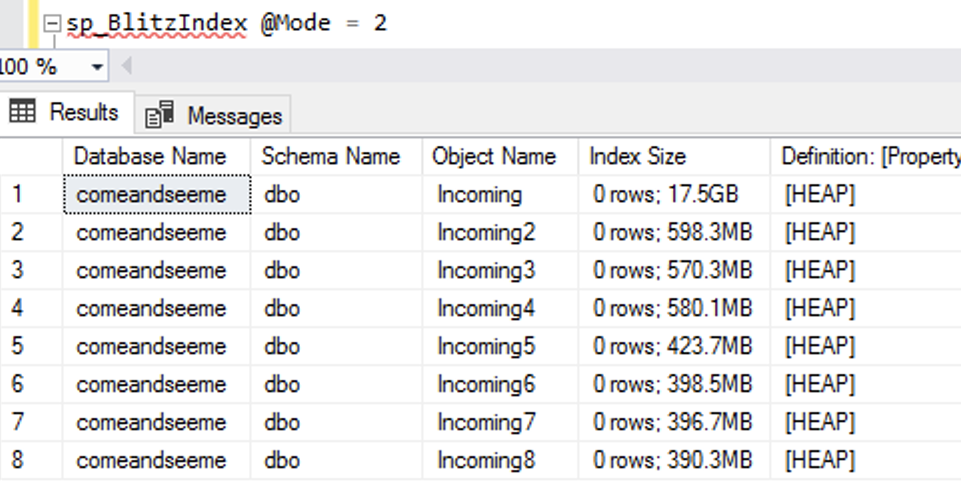
To demonstrate the growth, I took the Stack Overflow database (which doesn’t have RCSI enabled) and created a bunch of indexes on the Posts table. I checked index sizes with sp_BlitzIndex @Mode = 2 (copy/pasted into a spreadsheet, and cleaned up a little to maximize info density):
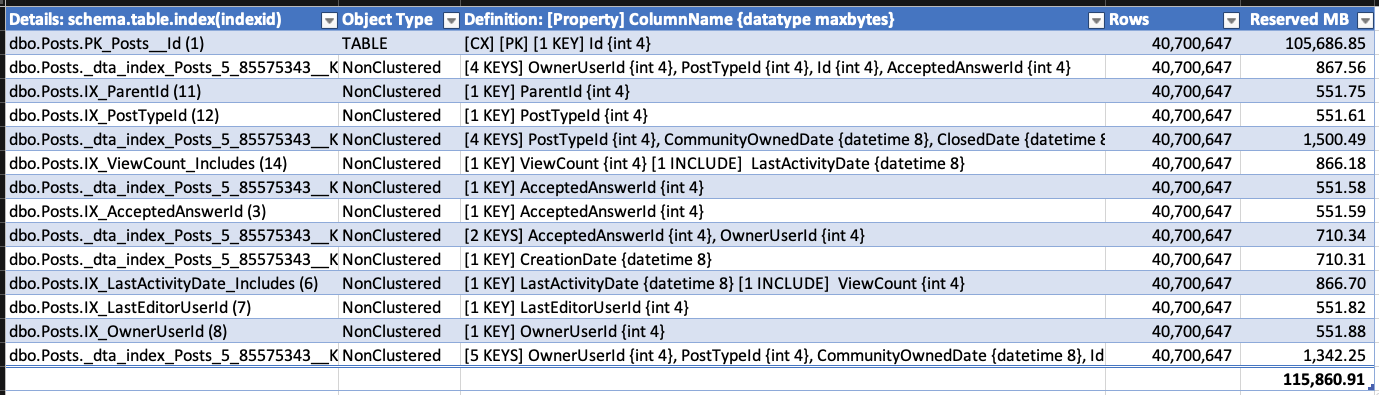
I then deleted about half of the rows:
|
1 2 3 |
BEGIN TRAN; DELETE dbo.Posts WHERE Id % 2 = 0; GO |
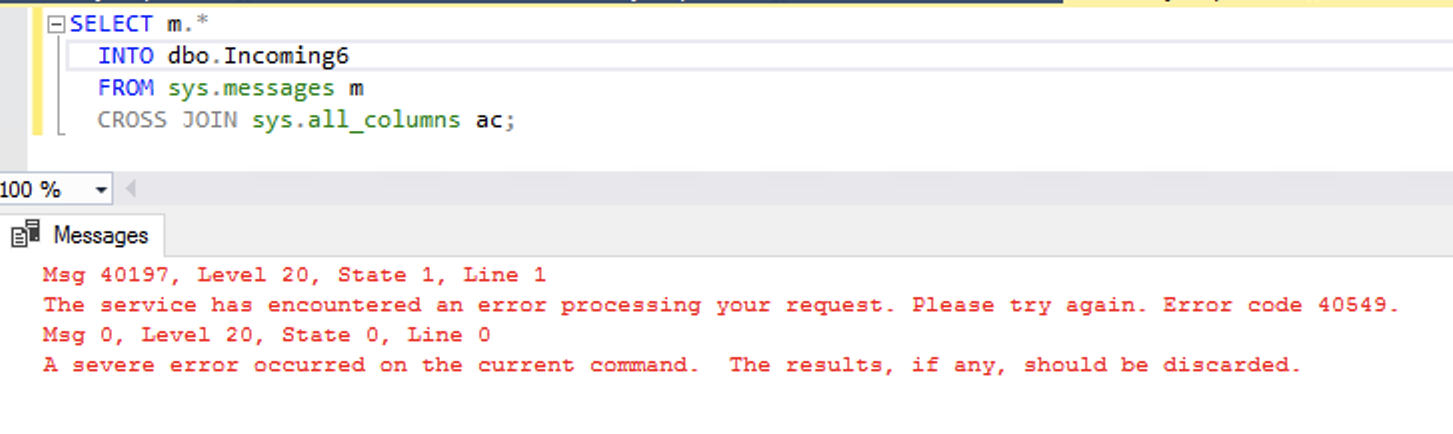
Amusingly, while the deletes were happening, the data file was growing to accommodate the timestamps, too! The SSMS Disk Usage Report shows the growth events – here’s just the top to illustrate:
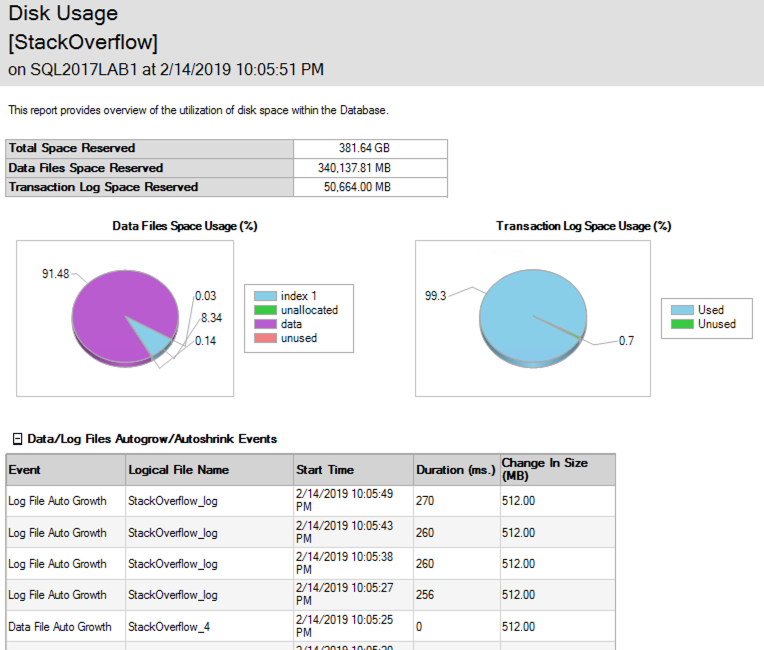
(Gotta love a demo where deletes make the database grow.) While the delete was running, I ran sp_BlitzIndex again. Note that the clustered index has less rows, but its size has already grown by about 1.5GB. The nonclustered indexes on AcceptedAnswerId have grown dramatically – they’re indexes on a small value that’s mostly null, so their index sizes have nearly doubled!
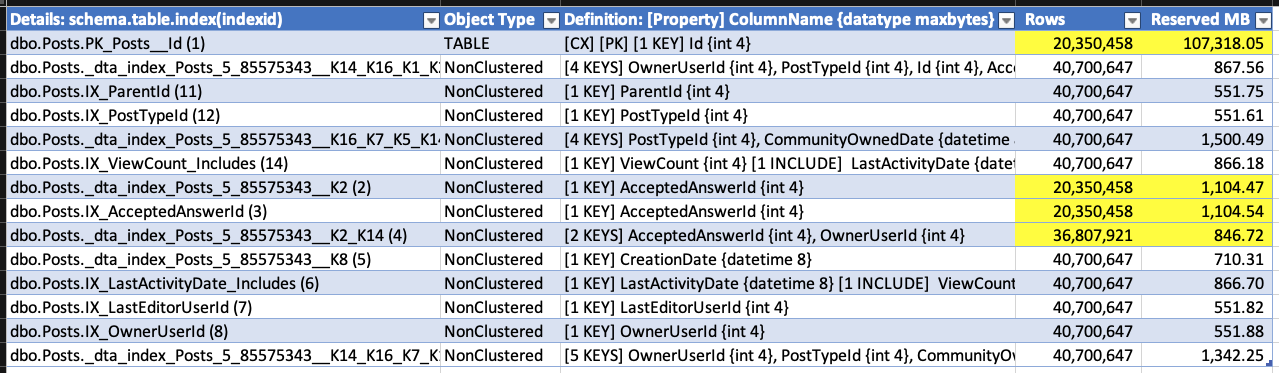
I don’t have to wait for the deletion to finish to prove that out, so I’ll stop the demo there. Point being: when you do big deletions on a table that was implemented before RCSI, SI, or AGs were enabled, the indexes (including the clustered) can actually grow to accommodate the addition of the version store timestamp.
Things you might take away from this:
- RCSI, SI, and AGs have cost overheads you might not initially consider
- After enabling RCSI, SI, or an AG, rebuild your indexes – not that it’s going to make your life better, it’s just that you can control when the page splits, object growth, fragmentation, and logged activity happens instead of waiting around for it to hit when you’re in a rush to do something
- Offline index rebuilds seems to have a related effect too – Swart noted in a comment that when he tested them, they were rebuilt without the 14-byte version stamp, meaning that subsequent updates and deletes incurred the page splits and object growth
- I have really strange hobbies
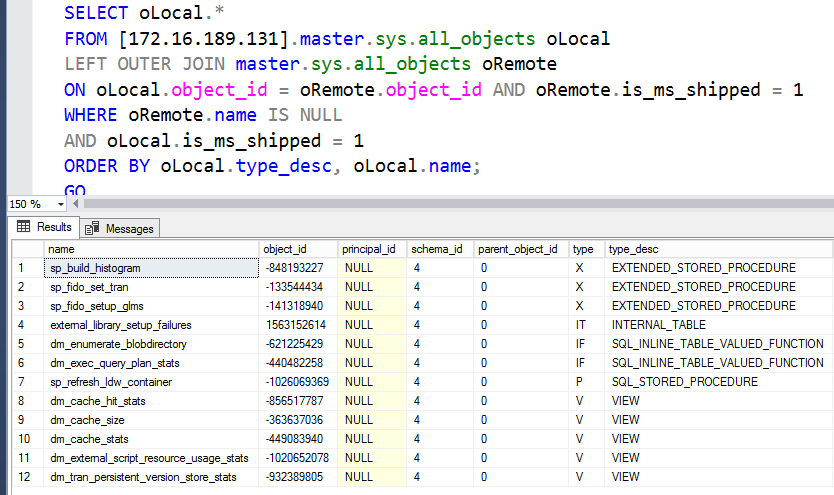






















 j
j
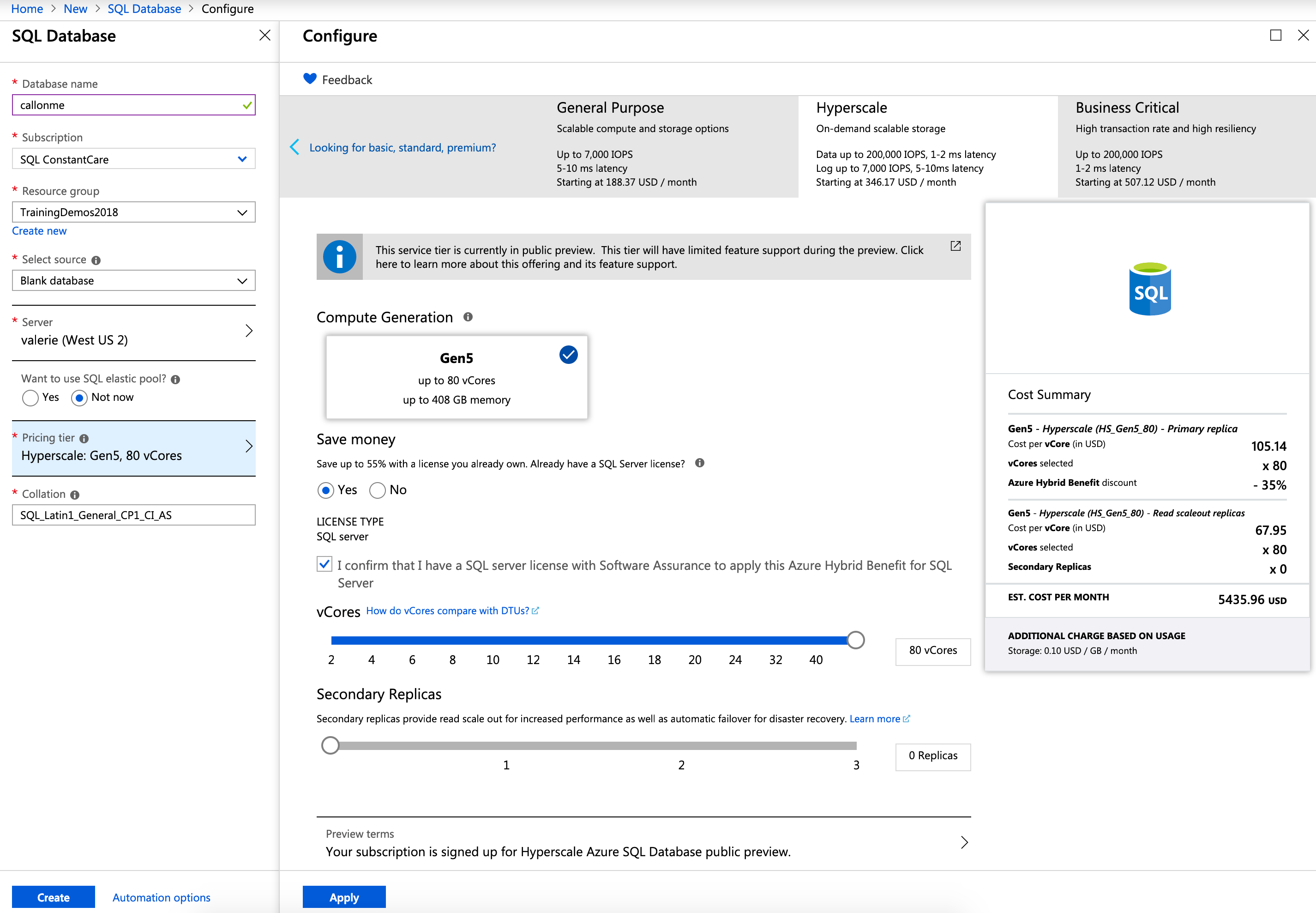





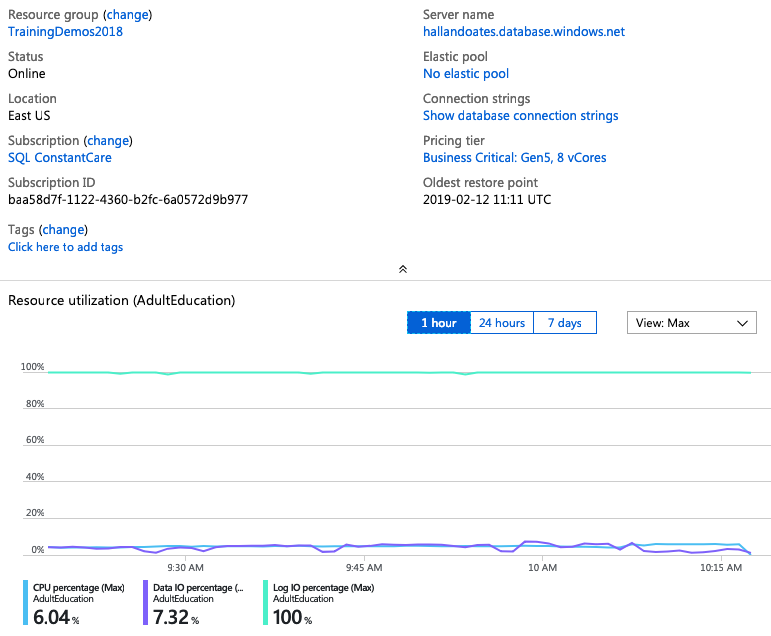
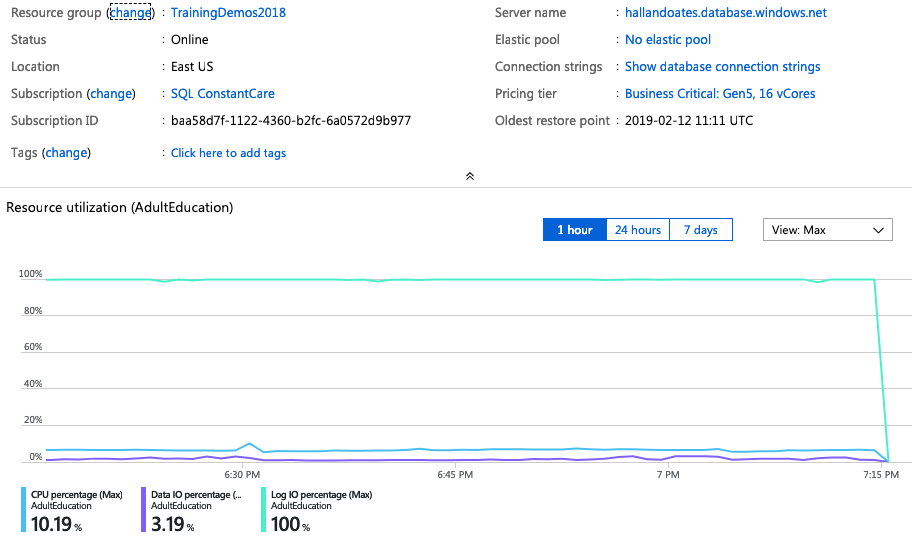
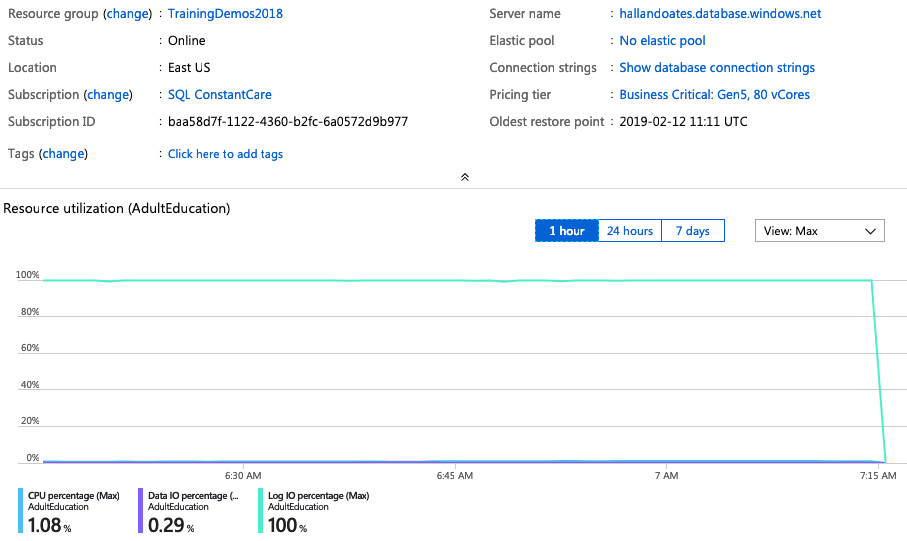
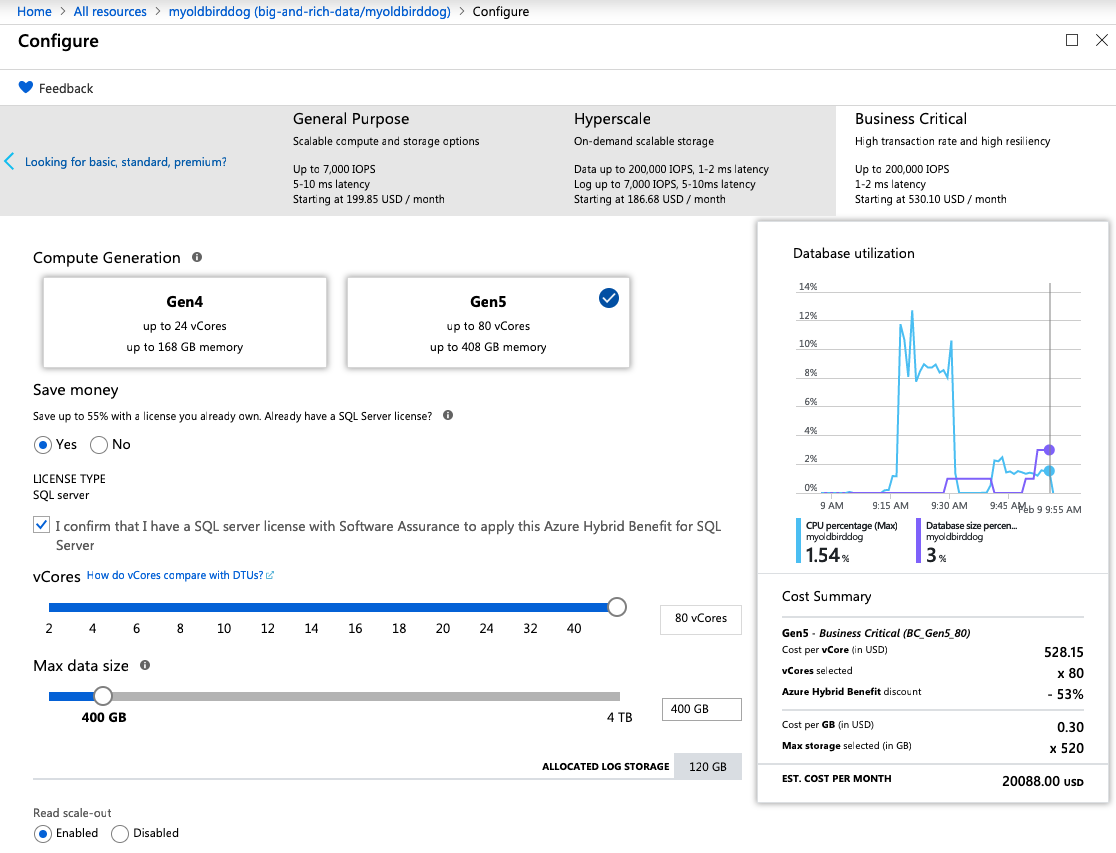
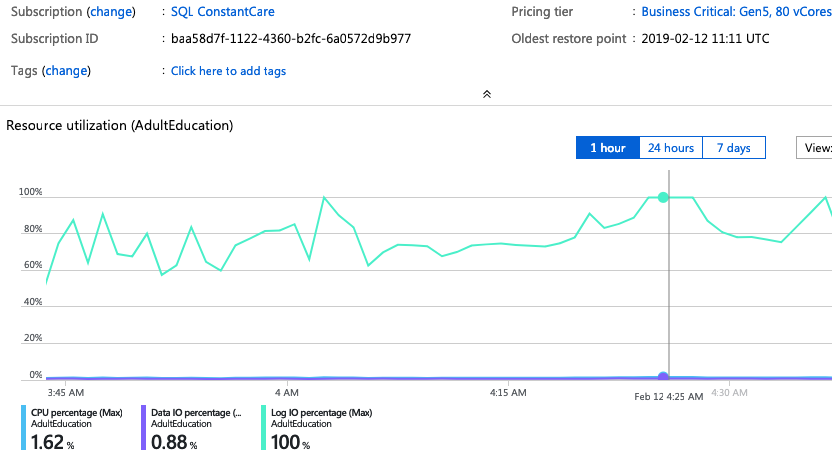
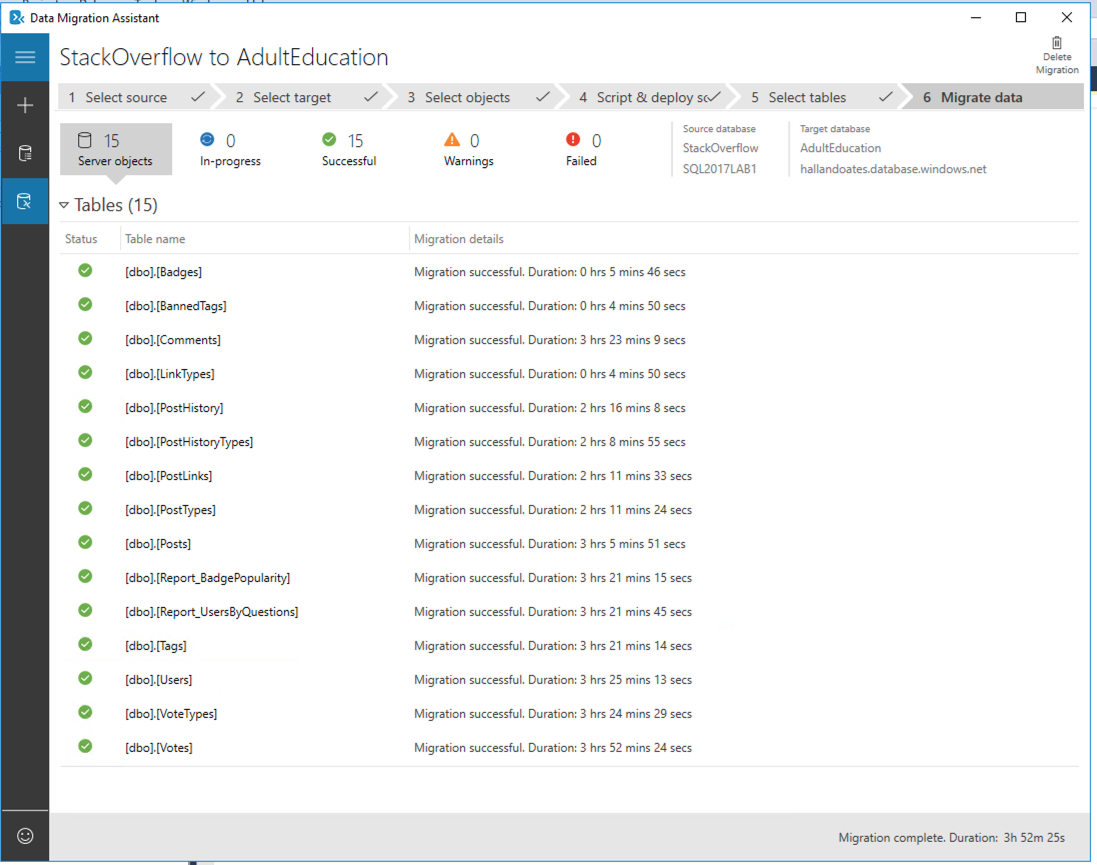
 I spun up another 80-core monster – this time in East US – and again, can I just take a second to high-five Microsoft for completing an 80-core Hyperscale deployment in 3 minutes, 19 seconds? This is probably the biggest reason I get excited about the cloud: operational flexibility.
I spun up another 80-core monster – this time in East US – and again, can I just take a second to high-five Microsoft for completing an 80-core Hyperscale deployment in 3 minutes, 19 seconds? This is probably the biggest reason I get excited about the cloud: operational flexibility.