
Why Archive Data?
Meet Margot. Margot is an application developer who works for a small company. Margot’s application collects and generates a lot of data from users including their interactions with the site, emails and texts that they send, and user submitted forms. Data is never deleted from the database, but only a few administrative users need to query historical data.
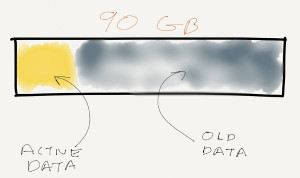
The database has grown considerably because of this historical data – the production database is around 90GB but only 12GB or so is actively queried. The remaining data is a record of user activity, emails, text messages, and previous versions of user data.
Margot is faced with an important decision – How should she deal with this increase in data? Data can’t be deleted, there isn’t budget to upgrade to SQL Server Enterprise Edition and use table partitioning, and there’s a push to move to a cloud service to eliminate some operational difficulties.
Using Partitioned Views to Archive Data
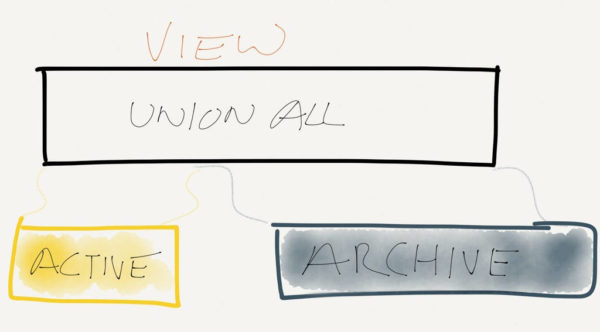
One option that Margot has read about is “partitioned views” – this is a method where data is split into two or more tables with a view over the top. The view is used to provide easy access to all of the information in the database. Storing data across many tables means DBAs can store data in many different ways – e.g. compressed tables or filegroups and tiered storage.
There’s a downside to this approach – all of the data is still in one database. Any HA solutions applied to the live portion of the data set will have to be applied to the entire data set. This could lead to a significant cost increase in a hosted/cloud scenario.
Archiving Data with a Historical Database

The second thing that sprang to mind was creating a separate archival database. Old data is copied into the archival database by scheduled jobs. When users need to run historical reports, the queries hit the archival database. When users need to run current reports, queries are directed to the current application database.
Margot immediately noticed one problem – what happens when a user needs to query a combination of historical and current data? She’s not sure if the users are willing to accept limited reporting functionality.
Archiving Data with Separate Data Stores

A third option that Margot considered was creating a separate database for the data that needed to be kept forever. Current data would be written to both the live database and the historical database. Any data that didn’t need to be ever be in the current database (email or SMS history) would only be written to the historical database.
Although this made some aspects of querying more complex – how could row-level security from the primary database be applied to the historical database – Margot is confident that this solves the majority of problems that they were facing.
This solution would require application changes to make querying work, but Margot and her team thought it was the most flexible solution for their current efforts: both databases can be managed and tuned separately, plus the primary database remains small.
Other Ideas?
Not every database needs to scale in the same way. What ideas do you have to solve this problem?

12 Comments. Leave new
Filtered Indexes may help, if they’re applied to whatever distinguishes the active 12GB from the inactive 78GB. It would warrant some further analysis to determine any possible benefit.
That is a good idea. As long as you can find a way to identify filtering criteria and automate filtered index creation, you’ve got a plan. If only SQL Server would reliably pick up filtered indexes.
I like your thinking.
What about a separate table on a read only filegroup? It would still require modifications to the application if you need to provide access to the data but you can segregate the maintenance plans and keep the primary filegroup small.
Cunning. This certainly requires less work than partitioning and may be a good way to make life more pleasant in the long run.
A thought I had reading this post was a hybrid of partitioned views and separate data stores. Create synonyms pointing the archive database, and then write a view similar to the partitioned view description.
I like that idea. Using the partitioned views and synonyms gives you a lot of flexibility for bouncing things around between different storage options. It does increase the maintenance overhead, but hey, that’s the price of convenience, right?
You could still get into trouble if a pesky user queries all of the data, but at least you can get better insight into what’s going on.
I would probably go with a combination of the archival octopus and dynamic SQL. Have one logical database that has synonyms/views to different databases. One per time cycle (Maybe per year or quarter). Create a new DB for each year (In a job with dynamic SQL that also updates the partitioned views you’ll need) and have a partitioned view over all of the synonyms in the logical DB. You reference a single DB but get to query all of the physical DBs. I admit that there are serious issues if you have too many DBs but by the time that you’ve got a couple of hundred you’ve been in business for 200 years and I think your issues would extend well beyond this topic. Overall I would most likely choose a hybrid in the end.
Also it means that you can more easily archive (Backup restore) old data and just remove it from the primary server in future. Reasonably flexible and keeps a tighter leash on the data.
I like it! You’re the first person to mention dynamic SQL and that wins you a place in my heart.
Distributed partitioned views are going to potentially cause some significant performance problems, but with dynamic SQL you can at least control how you query the data and potentially can avoid the hit of join remoting.
Transactional Replication:– )
Given the need of reporting based on all the historical and current data, if I had been assigned this project, I would set up a one way transactional replication between OLTP and Reporting database.
Internally it will propagate inserts, updates and deletes by some system written procedures.
I would tweak the delete procedure and make it not delete anything in ReportingDB. (Just replace the code with select 1). This was all the new inserts and updates will go to the ReportingDB but the deletes that I am going to issue to remove some historical data is not going to delete it in ReportingDB.
This way you can have all your data in one place and you can have new set of indexes specifically for reporting purpose(change the default clustered index which comes with replication), have more of indexes(again) to support some nasty aggregate operations.
This is just an idea from me and I have not had a chance to implement this in production yet.:-)
PS: I don’t like views much as if you have nested multiple views(which we do over the time), it screws the execution plan badly( as I witnessed).
Regards
Chandan Jha
If disk space is not a problem, you could have two databases. One live, with only current data, and the ENTIRE database archived. Direct queries to the appropriate one – live for normal activity, archive for managers that need historical data. Copies of changes could be batched to the archive as an offline job at night, so that live response would be good, and the archive would be out of date by today’s activity at the most. 12GB of duplicated data is not much, given today’s drive capacities, and seems to me would offer the least amount of upgrade work – NO existing queries would have to be recoded, nor would any data structures need changing. Simply redirect the archive queries to the archive database, and add ONE nightly offline job to keep the versions consistent.
Yes. I would go with Pete’s recommendation as well. Looks like you have an OLTP and Reporting system requirements.
Hi Jeremiah,
Will the 2nd option from this article + adding link server(if on different db)/union queries to combine historical and current data inquiries.
Thank you,
Lester