
How fast can a $5,436/mo Azure SQL DB Hyperscale load data?
A client asked, “How quickly could we spin up a full copy of our database in the new Azure SQL DB Hyperscale?” Their database size wasn’t too far off from the 340GB Stack Overflow database, so I decided to migrate that to Hyperscale to see how the experience went.
Hyperscale is Microsoft’s intriguing competitor to Amazon Aurora. Hyperscale gives you most of the SQL Server compatibility that you’re used to, but a wild new architecture under the hood. Let’s see how that new design affects ingestion rates.
Setting up Azure SQL DB Hyperscale
Hyperscale’s setup in the Azure portal is a little easier since it’s a new product: you just pick how many cores you want and how many replicas, and that’s it. You don’t have to define the database size ahead of time because, uh, this isn’t 2005. (Seriously, can we just talk for a minute about how archaic it is that Azure SQL DB makes you pick a maximum size, yet it doesn’t affect the pricing? They’re just handing you an uncooked chicken breast with their bare hands. You just know that’s going to come back to haunt you later.)
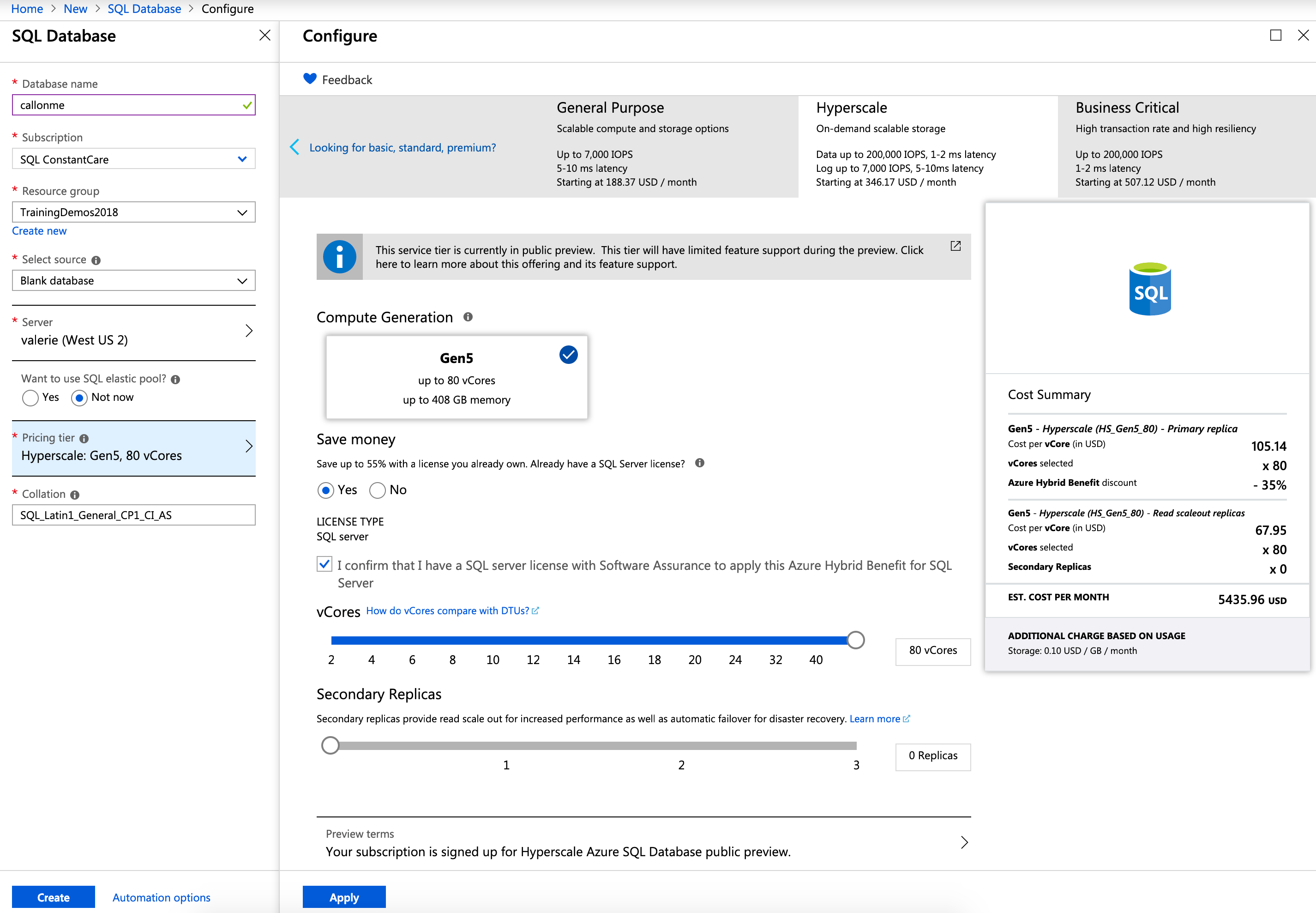
I maxed out my core count for the database migration – I can always downsize it later after the ingestion finishes. About pricing – Hyperscale is in preview right now, and I wanna say preview prices are half of general availability prices, but don’t quote me on that.
Attempt #1: firing up the Data Migration Assistant
(but in an AWS VM)
You can’t just hand Microsoft a database backup and restore it into Hyperscale. (Azure SQL DB suffers from this same limitation, but Managed Instances do not.) If you wanna move a SQL Server database into Hyperscale, you have the same options that you have with Azure SQL DB:
- Offline: use the Data Migration Assistant (also, useful white paper)
- Offline: generate a BACPAC, and then import the BACPAC in Azure SQL DB
- Online: set up transactional replication to keep the two in sync, and then cut over
- Offline (for a SQL Server source): Azure Database Migration Service
I didn’t want to hassle with transactional replication just to get a development database up to the cloud, and I didn’t care about downtime, so I went with the first method, and followed the instructions to maximize performance during my move (except for one thing that I’ll mention at the end, and why it didn’t seem to matter.) If this was a production migration scenario, I’d probably spend a lot more time digging into the last option, but my eyes started glazing over in the documentation once I learned I had to set up custom VNets, and I had limited time to pull this project off.
I ran the Data Migration Assistant, and dear reader, let’s pause for a moment to give Microsoft a round of applause for that app. It’s delightfully easy to use, full stop. Connect to the source server, connect to the target, pick the stuff you wanna move, it warns you about problems, and we’re off to the races. It’s just powerful enough to get the job done, but easy enough that I can see a lot of just-barely-technical admins stepping through it. Nicely done.

And off we went.
However, the load speeds were…not what I was hoping. 20 minutes into it, I realized the database was going to take several hours, and I didn’t really wanna leave a $5,436 per month server running for a day. Plus, if anything broke about the migration, and I had to start over, I would be one angry fella. The DMA doesn’t have a resumable way to keep going if something goes wrong midway through loading a big table, although at least I can pick which tables I want to migrate. (That’s where the Azure Database Migration Service makes so much more sense for production workloads, and I’m gonna be honest: after the ease of use of the Data Migration Assistant, I’m really tempted to spend some time with the Database Migration Service just to see if it’s as elegantly simple.)
Good news: no artificial log write throttling!
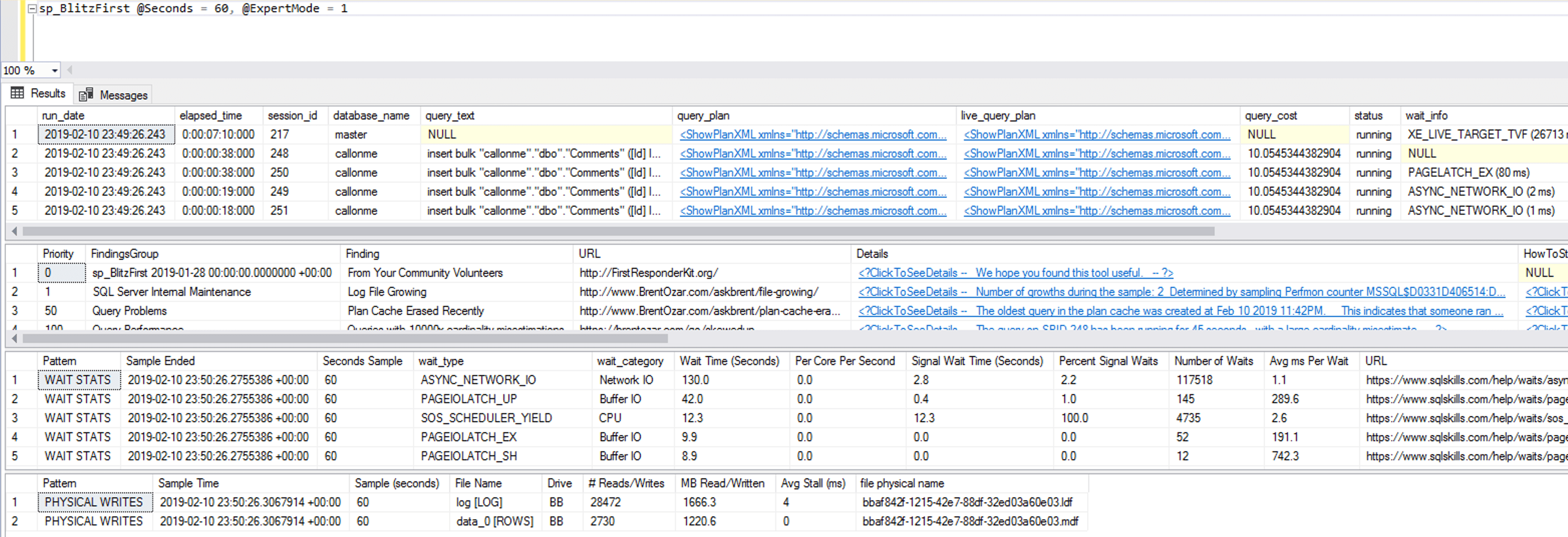
I monitored performance with sp_BlitzFirst on both the SQL Server source and the Hyperscale target. The SQL Server source was all local solid state NVMe storage, so it wasn’t a read performance bottleneck. The Hyperscale wait stats were interesting though:

Before you read too much into this – note that wait stats changed dramatically during the loads. Having said that, annotated notes:
- At the time of this screenshot, queries are waiting on PAGEIOLATCH waits, reading data pages from data files, but you can’t rely on point-in-time checks of individual queries. Those 200-300 millisecond delays are a bit of a bad foreboding of what’s to come, though.
- A log file is growing – that’s something I saw repeatedly during my tests, and that makes perfect sense given that I’m ingesting ~340GB of data.
- Top wait type is ASYNC_NETWORK_IO, which makes sense given that we’re moving data across networks. This is a case where I wish the Data Migration Assistant pushed data across even more threads because I don’t think we’re bottlenecked on the target write side. However, the storage waits – PAGEIOLATCH – are kinda concerning, especially with the THREE TO FOUR HUNDRED MILLISECOND delays. Those are not small numbers.
- In a 60-second sample, we only managed to write 1GB to the data file and 1.5GB to the log. Even combined, that’s only 41.5 MB/sec – that’s USB thumb drive territory. Log file latency at 4ms is great given Hyperscale’s storage architecture, though.
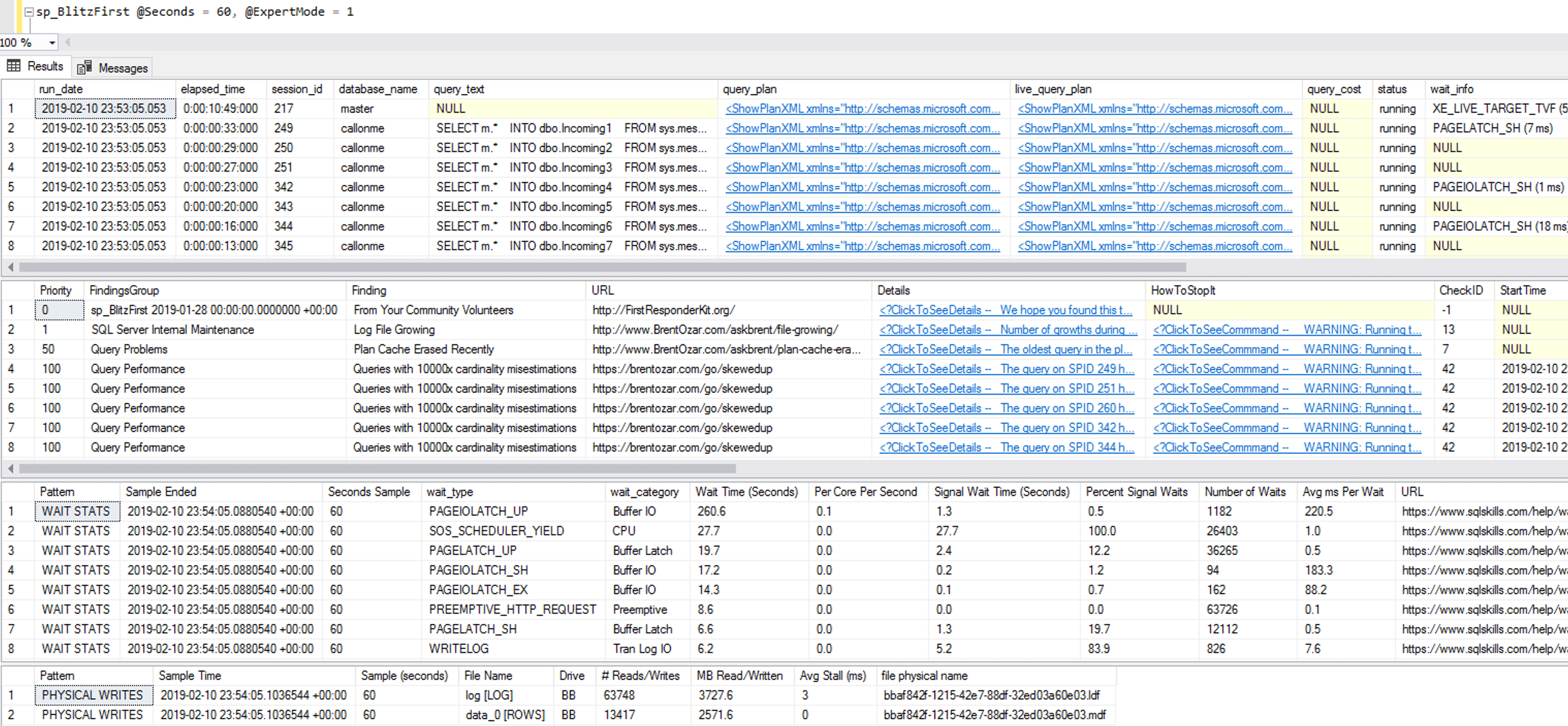
Here’s another screenshot from a different point in the loads – note that this time around, we have similar storage throughput (2.7GB written in total in 60 seconds) yet near zero storage waits:

Note what’s not in either screenshot: any governor waits. From the wait stats side at least, it didn’t look like we’re being throttled from writing more data. To drill deeper and examine sys.dm_db_resource_stats directly to see if we’re hitting the avg_log_write_percent limits:
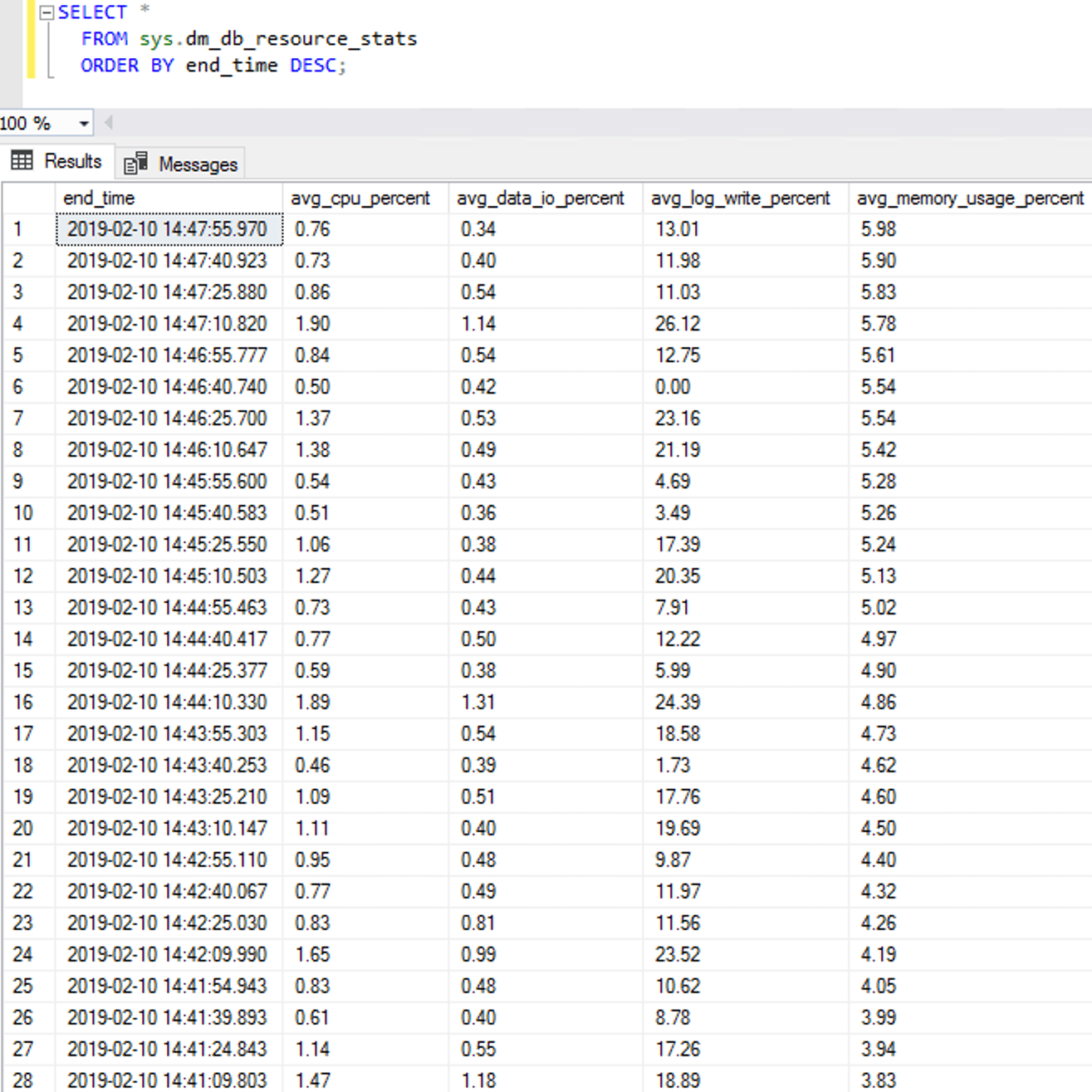
Not even close to being throttled. That’s fantastic!
So was attempt #1 faster? No, but…
The Hyperscale FAQ notes that:
The transaction log with Hyperscale is practically infinite. You do not need to worry about running out of log space on a system that has a high log throughput. However, the log generation rate might be throttled for continuous aggressive workloads. The peak and average log generation rate is not yet known (still in preview).
I love that wording – it’s like they discovered a new species, not like they wrote the code themselves. My guess, and this is just a guess, is that the throttle limits are set artificially high right now while they figure out the best place to set the limits.
- The good news is that loads weren’t being artificially throttled
- The bad news is that they might implement throttling as we approach GA (but hey, live for today)
- The great news is that if I put work into performance tuning this migration, I’d likely be able to ingest data way faster
Well, I’m curious, and my client was curious, so let’s do this.
Attempt #2: nearby Azure L8 VM as source
My original source SQL Server was in Amazon because that’s where the client keeps their stuff today too, but given the lack of log write throttling in Azure SQL DB Hyperscale, I decided to try with an Azure VM source.
My Hyperscale target database was in West US 2, so I spun up an Azure VM in that same region. To give Hyperscale a faster/closer source, I used an L8s v2 VM – that’s 8 cores, 64GB RAM, and over 1TB of local (ephemeral) NVMe storage. Most production database workloads aren’t run on ephemeral storage since of course you can lose the database when the VM goes down, but you can mitigate that with a lot of defensive scripting and Availability Groups. That is left as an exercise for the reader. For today, YOLO.
I logged into the newly created VM, downloaded the 340GB Stack Overflow database via BitTorrent, deleted the former tables in Hyperscale, installed the Azure Data Migration Assistant, and started the migration again. Full disclosure: because the import had gotten maybe 10% finished on attempt #1, some of the log file growths were already out of the way. (I deleted the Hyperscale tables rather than deleting the entire database and starting over.)
And…Hyperscale still maxed out at about 1.6GB in any given 60-second sample:
And sys.dm_db_resource_stats still showed nowhere near the log_write_percent limits, whatever they’re set to:

Hmm. Disappointing. Well, as long as we’re here…
Attempt #3: synthetic local loads
Just in case there was a problem with something with my Hyperscale instance, I blew it away and started again from scratch. I also took the Data Migration Assistant and networking completely out of the equation. I created a new 80-core Hyperscale database, maxed out on storage, and loaded a table with junk contents from sys.messages – this way, I didn’t have to worry about any cross-server communication at all:
|
1 2 3 4 |
SELECT m.* INTO dbo.Incoming1 FROM sys.messages m CROSS JOIN sys.all_columns ac; |
I ran that same query across 8 sessions, but with different table names on each so they wouldn’t conflict. Log write volumes did about double, doing about 3.6GB of log file writes in 60 seconds:
And no, we weren’t anywhere near the limits:

But now I’m pretty sure the “limits” are set to an imaginary number just to let the hardware do as many writes as it can. I like that. I also like the Autobahn.
Attempt #4: letting it run overnight
 I spun up another 80-core monster – this time in East US – and again, can I just take a second to high-five Microsoft for completing an 80-core Hyperscale deployment in 3 minutes, 19 seconds? This is probably the biggest reason I get excited about the cloud: operational flexibility.
I spun up another 80-core monster – this time in East US – and again, can I just take a second to high-five Microsoft for completing an 80-core Hyperscale deployment in 3 minutes, 19 seconds? This is probably the biggest reason I get excited about the cloud: operational flexibility.
Then, I fired up the Data Migration Assistant and just let it run overnight, rackin’ up charges, moving the ~340GB Stack Overflow database (with no indexes) from an AWS East VM to my Hyperscale database. (Granted – not the best case scenario for Hyperscale – but in reality, most folks are probably looking at moving from on-premises, not Azure to Azure.) The deployment finished after 4 hours and 47 seconds:
~340GB in 4 hours is about 85GB per hour, or 1.4GB per minute. After the load finished, the Azure portal showed that my peak log consumption was 39.43% of the limits. Based on that, we can extrapolate that the limits are somewhere around 3-4GB per minute. (Actually achieving those limits is another matter, though, as I noted during the synthetic testing.)
Summary: not bad for this test scenario.
Hyperscale is a brand new product, and I wasn’t exactly giving it the best case scenario for ingesting data:
- I was importing across clouds
- I was using a non-performance-tuned app (Data Migration Assistant is easy, but it’s no SSIS)
But I think this represents a pretty good sampling of what customers are likely to try as they dip their toes into Hyperscale. In my next post, I’ll look at how an $21,468/mo Azure SQL DB fares under this same test.

16 Comments. Leave new
You should also try using the Data Factory copy data and for each copy data pipeline set your number of threads. At max, Hyperscale can handle 8000 concurrent threads so set accordingly to max it out but leave yourself a couple of threads for monitoring :). https://docs.microsoft.com/en-us/azure/sql-database/sql-database-vcore-resource-limits-single-databases#generation-5-compute-platform
I’m going to be gently tactful and ask, “Does that involve downloading a small app and stepping through a wizard in about 90 seconds, or is it more complicated than that?”
Lol, Create yourself an Azure Data Factory, login to it, step through a gui to specify source and target tables, then a few minutes editing destination connections to specify the concurrency. Pretty simple to set up.
Oh cool! No internet firewall hassles or VPN stuff to deal with, eh? That’s amazing! 😉
As long as it is in Azure. You could set up a data gateway to do from an on prem source but I think this article shows quite how easy it is, just specify a db as source rather than files https://www.red-gate.com/simple-talk/cloud/cloud-data/using-copy-wizard-azure-data-factory/
Right – it’s not.
I’m getting the feeling you didn’t read much of the post. May wanna slow down and give it another read, but just go a little slower this time and absorb the project constraints. Thanks!
Dont’t bother with Azure Data Factory. For some reason with type casting from blob to Azure SQL, but also Azure SQL Database as a source, the throughput is dramatic. From 6 MB/s to 13 MB/s on high service tiers for transferring 1 table, 5GB in total. That is beyond bad.
300gb over the cloud in five hours, is OK. But how fast is it on a minimum hyperscale instance?
Given the cloud constraints, I’ll guestimate, or at least hope, that it’s about the same speed for less money.
I wouldn’t expect it to be the same by any means – lower instance sizes mean less memory and less cores. You can’t expect a 2-core, 8GB RAM VM to be able to load data as fast as an 80-core, 408GB-RAM VM.
Depends where the bottlenecks are, and whether all those cores can keep from stepping on each other.
Right, if you have storage so crappy that 2 cores can keep it busy, you’re not doing bulk loads.
(Also, just to be clear: I think most businesses will be okay with upsizing temporarily when they need to do bulk loads of 300GB of data, or if they need to do that on a daily basis, even upsizing permanently.)
Regarding comment about Azure data factory and moving data from on-prem sql database to azure (either sql or azure blob, whatever).
You just need to install data gateway on your on prem machine and it will automatically figure out all network related stuff, you will see it as a possible connection in azure data factory -> specify sql server name and db name and off you go. When i was doing my tests it was very fast (probably limited by your on prem server and network obviously) with 5yo machine getting easily into 1GB/minute export into azure blob(havent tried those data volumes directly to hyperscale though).
Data factory is nice to try out but i think the true test would be to spin up a big cluster in azure databricks with database loaded there and run a parallel job directly to sql server. I did some tests but on small hyperscale db(4vcore) and achieved quite good performance (i was using CCI so cpu limited ingest rate).
I might come back here and post some more results.
[…] How fast can a $5,436/mo Azure SQL DB Hyperscale load data? “it’s like they discovered a new species, not like they wrote the code themselves” – Brent (T) said. […]
Hey cool, Brent Ozar called one of the SQL-related white paper’s I wrote back in the day ‘useful’. I feel proud.
Indeed it is! Nice work, sir!