Quiz: Are You the Next Brent Ozar Unlimited Consultant?
14 Comments
Hey SQL Server DBAs — we’re hiring!
Here’s a quick five question quiz. Give yourself one point for every ‘yes’:
- Have you been a database administrator for a few years?
- Does planning how to keep an application reliable and safe from disasters sound like fun?
- Do you love helping people make SQL Server go faster?
- Would you like to have a cartoon character of yourself?
- Can you see yourself dropping into our Office Hours sessions occasionally to help people for free?
If you got five points, you just might be the next Brent Ozar Unlimited employee!
Here’s what to do next:
Read more about the job here to find out what we’re looking for and what benefits we offer.
Then tell us about you!
We plan to accept applications through Friday, March 6, but don’t wait too long to submit — life moves fast sometimes.
Update March 7 – applications are closed, and we’re interviewing candidates. Thanks!





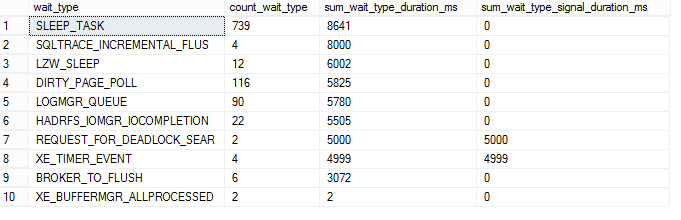
 There are many third party tools available for you to monitor SQL Server. The best way to approach selecting one is to write down a list of what you want to track, and make sure the software you pick has those features. Remember things like custom metrics, reports, and alerts! Most tools will offer a free trial; take advantage of that to make sure you’re making the right decision.
There are many third party tools available for you to monitor SQL Server. The best way to approach selecting one is to write down a list of what you want to track, and make sure the software you pick has those features. Remember things like custom metrics, reports, and alerts! Most tools will offer a free trial; take advantage of that to make sure you’re making the right decision.