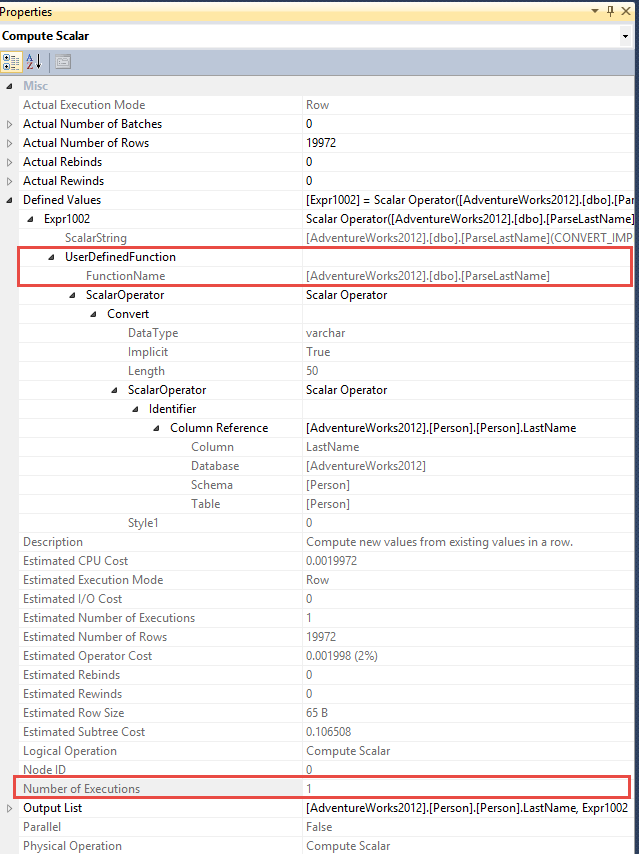
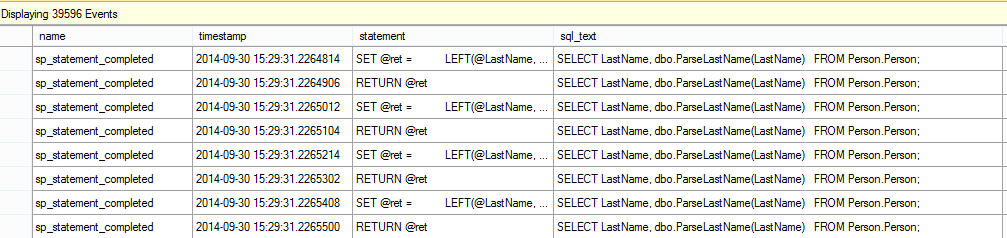
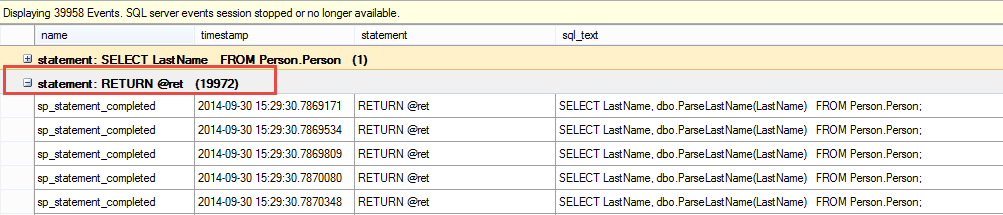
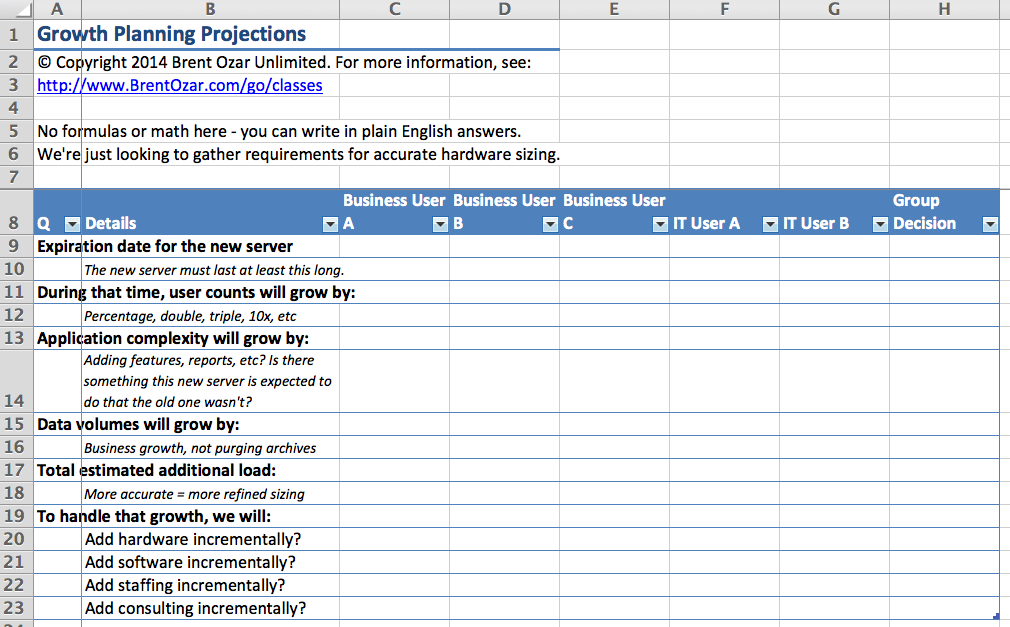
#SQLPASS Summit 2014 Keynote LiveBlog
7 Comments
10:03AM – Ranga back onstage to finish things up. Thanking Pier 1 for letting them share the exploratory work. And we’re out!
10:00AM – Power BI adding a new authoring and editing mode. James removes the pie chart and replaces it on the fly. Now that is knowing your audience – nice job.
9:58AM – Demoing updated Power BI dashboards. Man, these screens are always so gorgeous – Microsoft is fantastic at reporting front end demos.
9:56AM – Oops. Looks like somebody is running out-of-date Apple software that needs an update. Note the screen.

9:54AM – “I’ve been watching the Twitter feed, and I kinda have a pulse of where people are sitting.” Talking about why Microsoft is moving to the cloud. “I can ship that service every single week.” It gives Microsoft agility.
9:50AM – Microsoft’s James Phillips takes the stage by briefly recapping his background with Couchbase. (That name has come up a few times today.) “Data is a bucket of potential.” Love that line.

9:49AM – Demoing a phone app to locate items in, you guessed it, Pier 1. Was there some kind of sponsorship deal here? I do love the opportunity to tell a single story though. Just wish they’d have tied it to a single individual’s journey through the store through the entire keynote.
9:44AM – “Using 14 lines of SQL code, you can do real-time analytics.” Uh, that is the easiest part of the entire demo. How about putting Kinects in stores, building the web front end, etc?
9:40AM – Demoing a browser-based SSIS UI for Azure Data Factory.
9:37AM – Sanjay Soni taking the stage and explaining in-store analytics demos using Kinect sensors to watch where customers go using a heat map.

9:35AM – Apparently the “wave” trick had absolutely nothing to do with the session – maybe some kind of ice-breaker? This keynote has now gone completely surreal. He’s now moved on to machine learning. No segue whatsoever.
9:32AM – Joseph Sirosh, machine learning guy at Microsoft, starts by having the community applaud themselves. And now he’s teaching us to do the wave. Uh, okay.
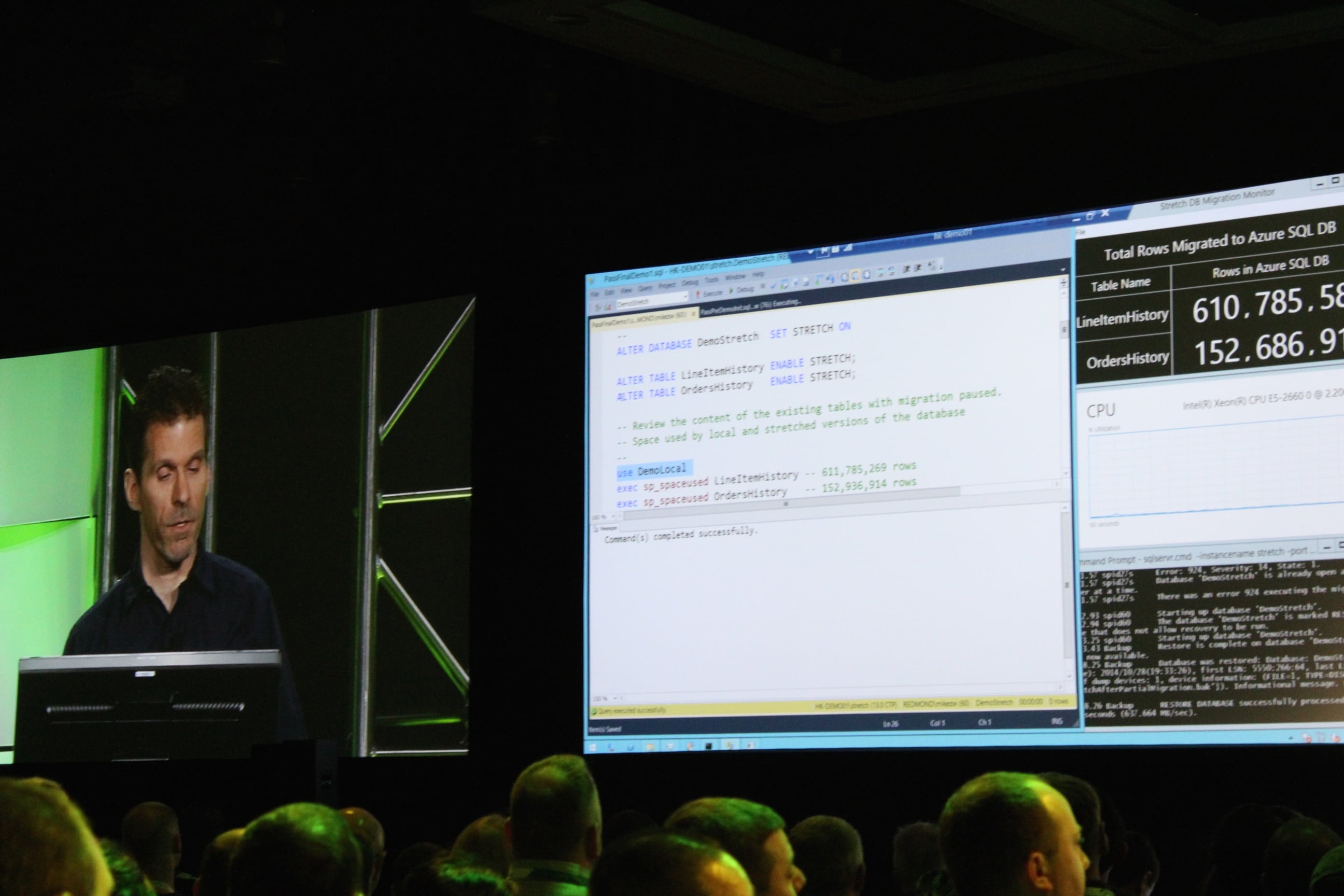
9:30AM – Demoing a restore of the local portion of the database. Even restoring a database got applause. Tells you how desperately rough that first stretch of the keynote was.
9:26AM – Demoing stretch tables: 750mm rows of data in Azure, plus 1mm rows of data stored locally on the SQL Server. It’s one table, with data stored both in the cloud and local storage. You can still query it as if it was entirely local.
9:22AM – Showing a demo of a Hekaton memory-optimized table, plus a nonclustered columnstore index built atop it. This is genuinely new.
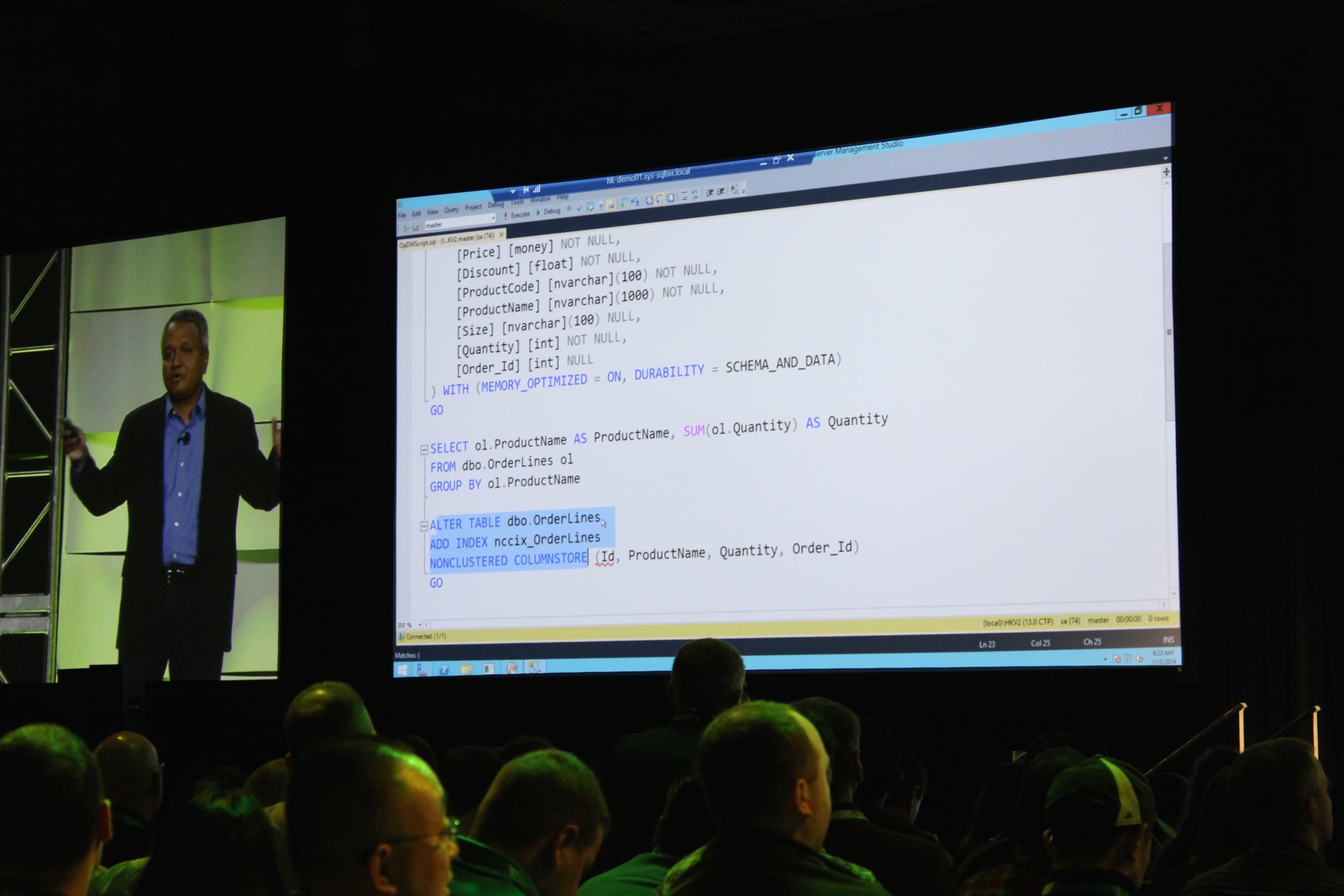
9:20AM – “What if you could run analytics directly on the transactional data?” Doing a live demo of a new way to run your reports in production.
9:18AM – Ranga announces a preview coming at some point in the future. “And that’s the announcement.” Literally one clap, and it was from the blogger’s table. This is bombing bad.
9:15AM – Uh, big problem here. Ranga just said Stack Overflow is using Microsoft SQL Server’s in-memory technologies. That is simply flat out wrong – Stack does not use Hekaton, Buffer Pool Extensions, or anything like that. Just plain old SQL Server tables. Very disappointing. If you’re at PASS, look for Nick Craver, one of their database gurus who’s here at the conference.
9:12AM – Now talking about something near and dear to my heart: how Stack Overflow is pushing limits.
9:10AM – To recap the demo, Azure SQL Database does geo-replication and sharding.
9:06AM – The utter and complete dead silence in the room tells a bigger story than the demo. This is just not what people come to PASS to see. If you think about the hourly rate of these attendees, even at just $100 per hour, this is one expensive bomb.
8:58AM – Quite possibly the most underwhelming demo I’ve ever seen. If you want to impress a room full of data professionals, you’re gonna need something better than a search box.
8:56AM – Pier 1 folks up to demo searching for orange pumpkins.

8:52AM – “The cloud enables consistency.” Errr, that’s not usually how that works. Usually the cloud enables eventual consistency, whereas on-prem enables consistency. I know that’s not the message he’s aiming for – he’s talking about the same data being available everywhere – but it’s just an odd choice of words.
8:49AM – Discussing Microsoft’s data platform as a way to manage all kinds of data sources. This is actually a huge edge for Microsoft – they have the Swiss Army knife of databases. Sure, you could argue that particular platforms do various parts much better – you don’t want to run a restaurant on a Swiss Army knife – but this is one hell of a powerful Swiss Army knife.
8:45AM – Ranga’s off to a really odd start. He starts by talking about Women in Technology and says “We’ll do our best,” and then segues into an odd story about his wife refusing to use online maps. Really, really awkward.
8:41AM – Microsoft’s T.K. Ranga Rengarajan taking the stage.

8:39AM – Watching several minutes of videos about people and stuff. No clapping. Hmm.
8:34AM – Tom’s a natural up on stage, totally relaxed.

8:33AM – Thanking the folks who help make the event possible: sponsors and volunteers.
8:31AM – Hands-on training sessions for 50 people per workshop are available here at PASS. Good reason to come to the conference instead of just playing along online – convince your boss by explaining that you can’t really get this hands-on experience anywhere else as easily.
8:27AM – PASS has provided 1.3 million hours of training in fiscal year 2014. (Would be interesting to see that broken out as free versus paid, and national versus local user group chapters.
8:22AM – PASS President Tom LaRock taking the stage and welcoming folks from 50 countries, 2,000 companies.

8:18AM – From the official press release: “The PASS Summit 2014 has 3,941 delegates as of last night and 1,959 pre-conference registrations across 56 countries for a total of 5,900 registrations.” The registrations number is always a little tricky because it counts pre-con attendees multiple times, but that delegates number is phenomenal. Nearly 4,000 folks is a lot! This is far and above the biggest Microsoft data event.
8:16AM – Folks are coming in and taking seats.
8:00AM Pacific – Good morning from the Blogger’s Table at the Seattle Convention Center. It’s day 1 of the PASS Summit 2014, the biggest international conference for SQL Server professionals. A few thousand data geeks are gathered here to connect, learn, and share.
The keynote session is about to start, and here’s how this works: I’m going to be editing this blog post during the keynote, adding my thoughts and analysis of the morning’s announcements. I’ll update it every few minutes, so you can refresh this page and the news will be up at the top.
You can watch the keynote live on PASS TV to follow along.
Here’s the abstract:
Evolving Microsoft’s Data Platform – The Journey to Cloud Continues
Data is the new currency and businesses are hungrier than ever to harness its power to transform and accelerate their business. A recent IDC study shows that business that are investing in harnessing the power of their data will capture a portion of the expected $1.6 trillion dollar top line revenue growth over the coming four years. SQL Server and the broader Microsoft data platform with the help of the PASS community are driving this data transformation in organizations of all sizes across the globe to capture this revenue opportunity.
In this session you will hear from the Microsoft Data Platform engineering leadership team about recent innovations and the journey ahead for Microsoft’s data platform. Learn first-hand how customers are accelerating their business through the many innovations included in SQL Server 2014 from ground breaking in-memory technologies to new highly efficient hybrid cloud scenarios. See how customers are revolutionizing their business with new insights using Power BI and Azure Machine Learning and Azure HDInsight services. Learn about the investments were are making Microsoft Azure across IAAS and PAAS to make it the best cloud hosting service for your database applications.
Ignore the first paragraph, which appears to be written for salespeople attending the Microsoft Worldwide Partner Conference, not the Professional Association for SQL Server PASS Summit. The second paragraph – not to mention the neato changes at Microsoft lately – offer a glimmer of hope for us geeks. If Microsoft wants to win market share away from Amazon’s huge lead, they’re going to have to bring out features and services that compete. The terms “investments” and “journey ahead” implies that we’ll be hearing about future features in Azure and SQL Server vNext.
Let’s see what they’re announcing today – and remember, like I wrote last week, my new perspective today is a chillaxed 1960s car show attendee. Bring on the flying cars.
For the latest updates, refresh this page and check the top.