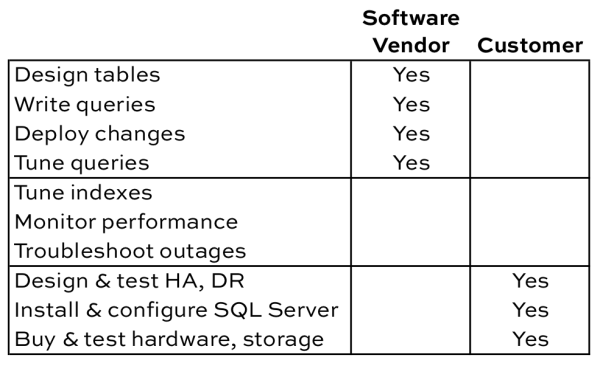
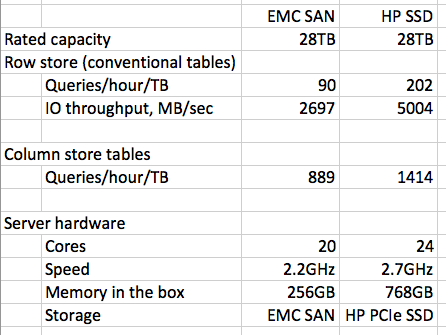
SQL Server Tasks You Probably Shouldn’t Automate
24 Comments
Every now and then I run across an automated script that does something a little suspicious. I’m not saying you should never put these things into a script, but if you do, seriously think about the surprise gotchas when someone runs the script:
- DBCC commands other than CHECKDB
- sp_configure (and especially RECONFIGURE afterwards)
- ALTER SERVER CONFIGURATION
- ALTER DATABASE
- ALTER AVAILABILITY GROUP
- CREATE INDEX or DROP INDEX
- KILL
- SHUTDOWN
- And most of the database engine management stored procedures
If you’re doing any of these on a scheduled basis, take a few minutes to document what you’re doing, why, and whether it’s safe to stop doing it. Your successor will thank you.
Believe me, otherwise she’s going to throw you under the bus when you’re gone, and if you haven’t left something behind to defend you, you’re going to look like That Guy.