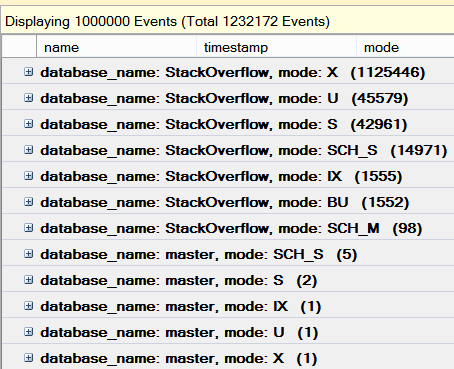
Microsoft Ignite Morning Keynote Liveblog #MSIgnite
Summary: Microsoft announced SQL Server 2016, with the first public preview coming this summer. The SQL Server 2016 release dates for the download were not announced. Here’s the SQL Server 2016 PDF data sheet, and here’s the SQL 2016 announcement.
As it happened:
8:00AM – Good morning, folks. This week, Microsoft’s new infrastructure conference, Ignite, opens in my current hometown of Chicago. Gotta love it when the conference comes to you – along with a sold-out crowd of 20,000 attendees.
Before talking about this morning’s keynote, let’s put the timing in context. Last week at the Microsoft Build conference in San Francisco, Microsoft made a few data-related announcements:
- Full-Text Search in Azure SQL Database (available in preview now)
- Transparent Data Encryption in ASD (available in preview now)
- Azure Data Lake (not available yet, no dates given)
- Azure SQL Data Warehouse (not available yet, no dates given)
Given that Build is a developer-focused conference, where the audience would really have loved to hear dates, see demos, etc, and didn’t get them, I don’t expect to see more details coming out of this morning’s Ignite keynote.
However, there are two types of keynotes today. First up this morning, we have Satya Nadella doing the overall keynote. With the infrastructure focus of Ignite, I’d expect to see a heavy focus on Windows, O365, SharePoint, System Center, and Azure.
Later this afternoon, we have another set of keynotes: foundation keynotes, including one dedicated just to SQL Server. I’m much more excited about that one, and I’ll liveblog that one as well.
This morning, though, it’s all about Windows. So why am I here? Well, I got my start as a sysadmin, and I’ve never seen Satya Nadella in person before, and hey, it’s only about 20 blocks south of my house.
The keynote starts in about 90 minutes, and you can watch online at Ignite.Microsoft.com.
You can tell it’s a Microsoft tech conference because the DJ is in a button down shirt. #MSIgnite pic.twitter.com/eUyUaqDtrJ
— Brent Ozar (@BrentO) May 4, 2015
8:18AM – the logistics of filling a room this big, wow. It’s an air traffic control style job, with dozens of staffers waving lit batons around, filling up one section at a time. The front sections are reserved for press, a tech leaders forum, and so on.
8:30AM – the button-down DJ explained that the live online feed is about to start, so he left the stage. He’s a warmup act, evidently. The music continues even though he’s not onstage. This is actually a political statement that human beings are no longer needed for block-rockin’ beats, and Microsoft is about to unveil their new product, IntelliDJ.
8:36AM – The audience is cackling about the awkward transcriptions onscreen.
8:38AM – How the hell is the WiFi still working this well? Witchcraft!
8:40AM – A Microsoft Band on one hand and an old-school watch on the other is the new socks with sandals.
8:43AM – Transcriptions good for laughs. “So whale you’re watching the keynote…”
8:48AM – Sounds like like the keynote streaming site is suffering issues already. If there’s 20K people here, I wonder how many people are trying to stream the video live. I don’t envy Microsoft – that’s hard work.
8:53AM – The pre-keynote-show is a neat idea, but talking to people about the motivation behind their tweets? Really?
8:58AM – It took two days to lay out the 15,000 chairs in this room. I believe it. Wow.
9:00AM – The WiFi failed me briefly, but only briefly. Nice job keeping this up and running!
9:03AM – The room goes dark, and they’re playing Microsoft’s version of the Dolby theater intro.
Common walking up through the crowd. #MSIgnite pic.twitter.com/Alo0XaUyVb
— Brent Ozar (@BrentO) May 4, 2015
9:06AM – Common walks off the stage, and Satya Nadella takes over. The air conditioning just kicked on big time, too. Or maybe it’s the cloud coming in.
Satya Nadella taking the stage. #MSIgnite pic.twitter.com/1YMrxN5meM
— Brent Ozar (@BrentO) May 4, 2015
9:09AM – Satya: “We are the only company that feels deeply about both companies and organizations, and bringing them together to empower transformations.” Uhh, okay, no.
9:11AM – Mobile first, cloud first – but it’s not about the mobility of a single device. It’s about the mobility of the experience. It’s about the cloud back end, and adding intelligence to your experiences. (Interesting take – one way to read that is, me: “We’re giving up on one device to rule them all, and just putting our experiences on every device.”)
9:14AM – Satya: “There are going to be more devices than people on the planet.” In an environment like that, Microsoft can be a winner. Not THE winner, just one of multiple winners, and that’s a good thing. Microsoft has had a tough time selling devices that consolidate – for example, Surface Pro simply isn’t selling as the tablet that can replace your laptop, but if it’s just one of your devices, it makes much better sense.
9:17AM – Satya: IT is Innovation & Transformation. Cute. “Microsoft is the productivity and platform company that will thrive in the mobile-first, cloud-first world.”
9:20AM – Satya: “It is important to us to build trust into the core of the operating system…that’s not a bolt-on, you have to build that in.” That’s a tough sell here – it hasn’t historically been one of this platform’s strengths.
Announcing Windows Update for Business. #MSIgnite pic.twitter.com/E6uDKzsW6i
— Brent Ozar (@BrentO) May 4, 2015
9:22AM – Announcing Windows Update for Business, but no details on that yet.
9:25AM – Satya’s talking a lot about letting people make their own technology choices, but letting IT staff get the control and compliance they need.
9:26AM – Office 2016 is going into a new public preview, Skype for Business will have live broadcasting features, Office Delve will have more organizational analytics. Will show you all of these as the keynote proceeds.
9:27AM – There’s been multiple announcements so far, but just kinda glossed over, no clapping.
9:28AM – Satya says SQL Server 2016 is “the biggest database breakthrough you’ve ever seen.” Makes the version number official, apparently – doesn’t seem to be a code name.
9:34AM – Satya telling the story about Fujitsu selling lettuce grown in their old clean rooms. “So think about it,” he says to the attendees. Okay. I’m thinking. How is Microsoft reinventing themselves, is that what you want me to think about?
9:35AM – “Realmadrid is an amazing brand. Everyone knows about them.” I have no idea who they are. The attendees apparently do, though – the first round of applause we’ve had yet as the CEO comes onstage.
CEO of Realmadrid onstage with Satya at #MSIgnite. pic.twitter.com/gD23DCaEcl
— Brent Ozar (@BrentO) May 4, 2015
9:38AM – Satya: “You’re like a software company now.” Talking about the work Realmadrid does in analyzing data about their fans. Pretty vague.
9:40AM – Details are starting to come out about Windows Update for Business.
9:41AM – Joe Belfiore coming out to talk about Windows 10, then Gurdeep Singh Pall will talk about reinventing productivity with Windows, O365, and Dynamics. Brad Anderson will talk about security.
9:44AM – Joe: “My mission is to convince you, and give you the tools to go back with, to get your end users to love Windows 10.” Sounds perfect for this audience. Alright, I’m in. Show me what you’ve got.
Joe demoing the new Windows 10 start menu. #MSIgnite pic.twitter.com/5vnVkIeFpG
— Brent Ozar (@BrentO) May 4, 2015
9:48AM – Joe says about 5-8% of users use Alt-Tab to switch between apps. Adding multiple desktop support. Hold down control/Windows/right-arrow and switch between desktops, or left-arrow to go back. Dragging an app from one desktop to another got the first spontaneous audience applause.
9:51AM – Demoing Cortana, asking her questions aloud. This is especially useful in today’s workplace with open cubes and meeting rooms. Oh, wait, hold on, I’m being told…
9:54AM – Demoing Cortana connecting to PowerBI. “What’s the number of people at Ignite by country?” Pops them up on a map with circle graphs and no numbers, not really useful at all.
Demoing more complex Cortana/PowerBI queries. #MSIgnite pic.twitter.com/znmuuYY5Wc
— Brent Ozar (@BrentO) May 4, 2015
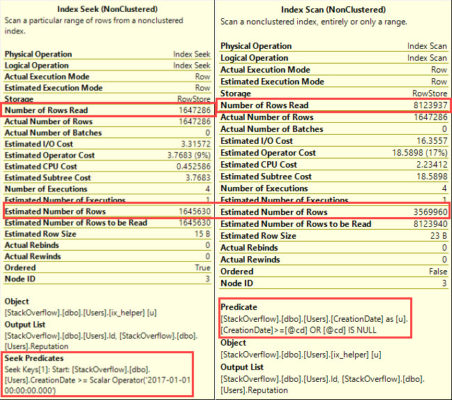
9:58AM – Announcing SQL Server 2016 – and the feature list!
10:04AM – Demoing Continuum, a new way of changing the Windows user interface to change between tablet mode and laptop mode depending on how you hold the device.
10:12AM – Demoing Windows Hello, a new authentication mechanism that works through the webcam. He takes a cloth off a webcam, and it unlocks his laptop in a matter of seconds without the user doing anything.
10:18AM – Belfiore off the stage. Good demos, relevant to this audience. Nothing jaw-dropping or magical, just steady progress. I don’t think he delivered on his commitment to get users excited about the Windows 10 UI, though.
10:19AM – Gurdeep: “Even as I speak, some of you are swiping right on Tinder.” HA!
10:21AM – Gurdeep is explaining how millennials are different by saying that his kid came up and told him “yolo.” Uhhhh..
10:23AM – Millennials work wherever they are. (News flash – seriously, this is not a millennial thing.)
10:24AM – Office 2016 Public Preview now available.
10:25AM – At Microsoft, we consider ourselves the custodians of productivity. (Again, news flash – millennials would probably tell you otherwise.)
10:27AM – Users can now create their own groups and teams on the fly, share things with them, schedule meetings. (I literally can’t even.)
10:29AM – “We’re making a huge bet on video for meetings….Polycom, Crestron…” (What year is this?)
10:32AM – Showing a HoloLens video and saying it’s a real, live product that’s that good. The reviews say otherwise.
10:36AM – Julia White coming onstage to do demos.
10:37AM – “This is the YouTube for the enterprise.” Well, in our company, I know what we would have: cats. Lots and lots and lots of cats.
10:40AM – Demoing the use of Delve to store files, share expertise, contact people. Isn’t this what SharePoint was supposed to be? When would I use one over the other?
Demoing upcoming improvements to O365 that are a “health tracker for your time” #MSIgnite pic.twitter.com/HXryI1uUvg
— Brent Ozar (@BrentO) May 4, 2015
10:46AM – Demoing live collaboration in Word that works just like Google Docs. Widespread applause. Have that many people really not seen Google Docs? Or are they clapping because Microsoft’s finally getting closer after all these years?
10:47AM – Sway will be part of O365 Business and Education soon.
10:52AM – Some awkward demos around collaboration and inking.
10:55AM – Julie’s off the stage. Her part seemed extreeeeemely rushed – guessing the prior presenters ran too long. This keynote is supposed to be over in 5 minutes. Oops, my bad. Thought it was 9AM-11AM, but it’s til 11:45AM.
10:59AM – Brad Anderson taking the stage to talk security. After 2 hours in a folding chair, I’m out. Time to grab some coffee and snacks, then I’ll blog the afternoon keynote that focuses on SQL Server.