Why Nobody Ever Patches Their SQL Servers
I saw a DBA.StackExchange.com question and had to laugh out loud:
“Is there a cool way of performing CU updates for SQL Server on hundreds of machines?”

No, and it has nothing to do with technology.
- Which servers are mission-critical 24/7 and can’t go down?
- Which servers can only be taken down in specific time windows?
- Which servers have dependencies between each other, like database mirroring and AlwaysOn Availability Group replicas?
- Which servers have automatic failover mechanisms (like clusters) where you can patch the standby node first, then fail over once, and patch the primary without having to fail back?
- Which servers have vendor apps that required a specific hotfix that may not be included in the cumulative update you’re about to apply?
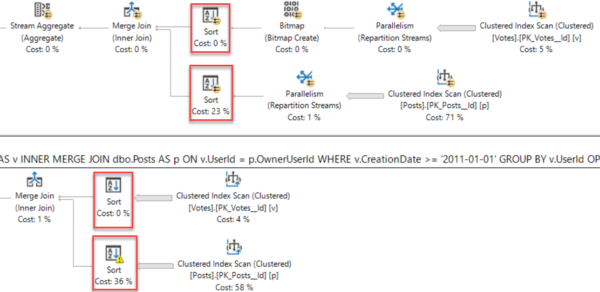
- Which servers are running long batch jobs like data warehouse loads or backups that would take a long time to restart if you took it down in the middle of its operations?
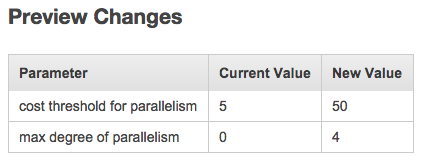
- Which servers have pending sp_configure changes that will take effect and surprise you when you restart?
Patching is hard work. Seriously.