Trace Flag 2330: Who needs missing index requests?
7 Comments
Hey, remember 2005?
What a great year for… not SQL Server. Mirroring was still a Service Pack away, and there was an issue with spinlock contention on OPT_IDX_STATS or SPL_OPT_IDX_STATS. The KB for it is over here, and it’s pretty explicit that the issue was fixed in 2008, and didn’t carry over to any later versions. For people still on 2005, you had a Trace Flag: 2330.
Like most things, there are trade offs. When you enable it, SQL stops collecting missing index requests. Probably not a great idea unless you’re working with extreme edge cases where you’ve already tuned your indexes really well. Most people will never fall into that category, though many of them will think they have.
The issue that it quite commonly addressed was around the creation of many objects in tempdb. You probably don’t need missing index details on a bunch of temp tables. What a lot of people didn’t realize was that it also made SQL stop collecting them for every other database.
Here in 2015
That Trace Flag can still be enabled with the same effect. Some people may not be aware that it’s not fixing anything, and still hurting things. Below is a script to reproduce the lousiness in a user database.
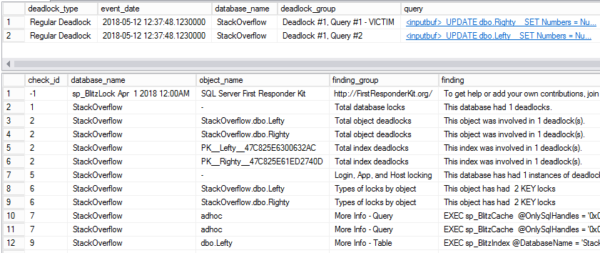
First we’ll clear out missing index requests by rebuilding the index (you know this happens, right?), and verify that there are no missing index requests with sp_BlitzIndex®. Running it in @mode = 3 will generate only missing index request details.
|
1 2 3 4 5 6 7 |
USE [StackOverflow] ALTER INDEX [PK_Users] ON [dbo].[Users] REBUILD; EXEC [master].[dbo].[sp_BlitzIndex] @DatabaseName = N'StackOverflow' , -- nvarchar(128) @Mode = 3 |
Once we verify that’s empty, we’ll run a query that will generate a missing index request in the Stack Overflow database, and verify it registers with sp_BlitzIndex® again.
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @id INT SELECT @id = id FROM [dbo].[Users] AS [u] WHERE [u].[LastAccessDate] > 2015-01-01 ORDER BY [u].[LastAccessDate] EXEC [master].[dbo].[sp_BlitzIndex] @DatabaseName = N'StackOverflow' , -- nvarchar(128) @Mode = 3 |
Whaddya know? We got ourselves a missing index.

Now comes the ugly
We’ll enable TF 2330 globally, and use some GO magic to run the same query 5x consecutively, then check back in on sp_BlitzIndex®.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DBCC TRACEON(2330, -1) GO DECLARE @id INT SELECT @id = id FROM [dbo].[Users] AS [u] WHERE [u].[LastAccessDate] > 2015-01-01 ORDER BY [u].[LastAccessDate] GO 5 EXEC [master].[dbo].[sp_BlitzIndex] @DatabaseName = N'StackOverflow' , -- nvarchar(128) @Mode = 3 |
The compiles ticked up one, but SQL stopped counting requests for the index.

There is a light
But hey! We can turn that off. And… Well, you know the drill.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DBCC TRACEOFF(2330, -1) GO DECLARE @id INT SELECT @id = id FROM [dbo].[Users] AS [u] WHERE [u].[LastAccessDate] > 2015-01-01 ORDER BY [u].[LastAccessDate] GO 5 EXEC [master].[dbo].[sp_BlitzIndex] @DatabaseName = N'StackOverflow' , -- nvarchar(128) @Mode = 3 |
We have stopped breaking SQL!

What did we learn?
2005! What a lousy year for hair, and Trace Flags, and, uh, I don’t remember much else about 2005. Feel free to tell me what you hated about 2005 in the comments. Just check all your servers to make sure no one turned on this Trace Flag as an April Fool’s Day joke and then never came back from lunch, first.
Thanks for reading!