A quick tip for working with large scripts in SSMS
7 Comments
Sometimes great things stare you in the face for years
Sometimes they stare at you for so long that you stop noticing them. This isn’t a romdramadey tag line. There are just so many buttons to push. Sometimes pressing them is a horrible idea and it breaks everything. I lose my mind every time I go to move a tab and I end up undocking a window. This won’t save you from that, but it will at least save your mouse scroll wheel.
This has helped me out a whole bunch of times, and especially, recently, when contributing code to our Blitz* line of stored procedures. Navigating all around large scripts to change variables or whatever is a horrible nuisance. Or it can be. When the stores procedure is like 3000 lines and there’s a bunch of dynamic SQL and… yeah. Anyway. Buttons!
Personality Crisis
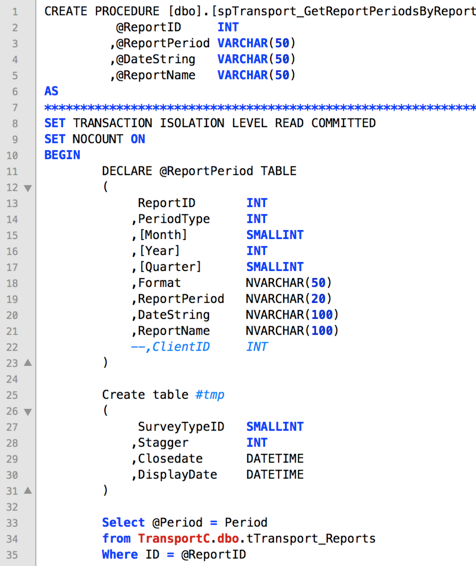
There’s a little button in the top right corner of SSMS. Rather unassuming. Blends right in. What is it? Fast scroll? Some kind of ruin all your settings and crash your computer button? Delete all the scripts you’ve been working on for the past 6 months?
No! It’s a splitter, screen splitter! Guaranteed to blow your mind! Anytime!

If you drag it up and down, you can alter the visible portion of the screen, and scroll and zoom in each pane independently.

There you have it
Next time you need to work with a huge script and find yourself scrolling around like a lunatic, remember this post!
Thanks for reading!

















 Seriously, I love this thing. Not just because many of the databases I worked with under the software were hundreds of gigs, on up to 9 terabytes, but because the people behind the software really do care about the product. The customer support is aces (Hello, Pod One), and the developers are super helpful and responsive.
Seriously, I love this thing. Not just because many of the databases I worked with under the software were hundreds of gigs, on up to 9 terabytes, but because the people behind the software really do care about the product. The customer support is aces (Hello, Pod One), and the developers are super helpful and responsive.