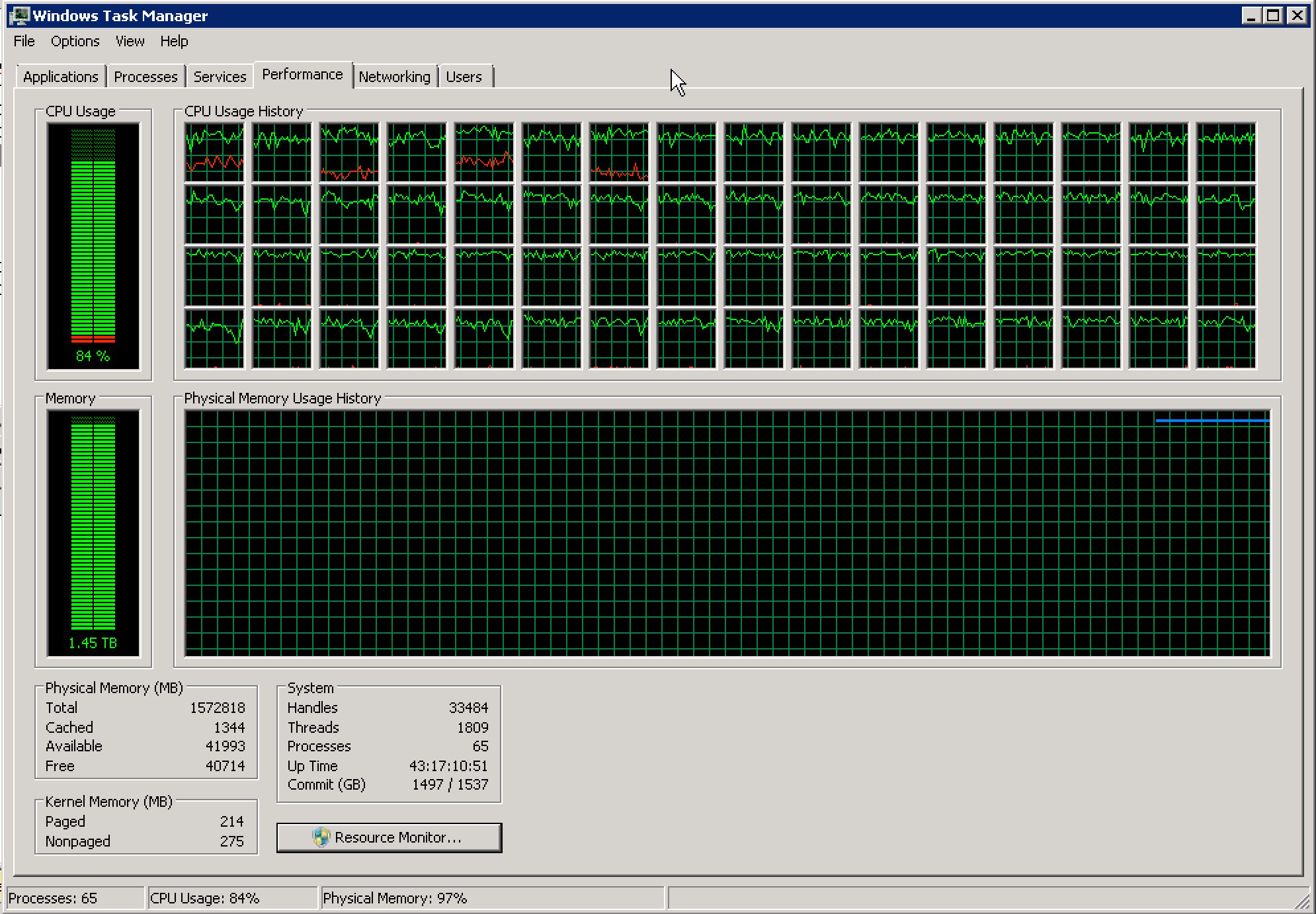
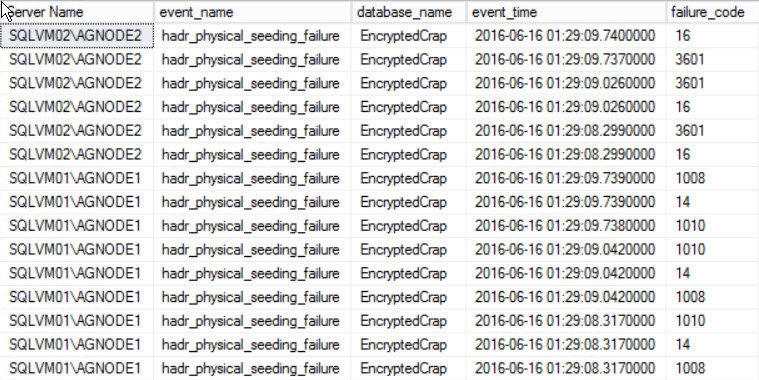
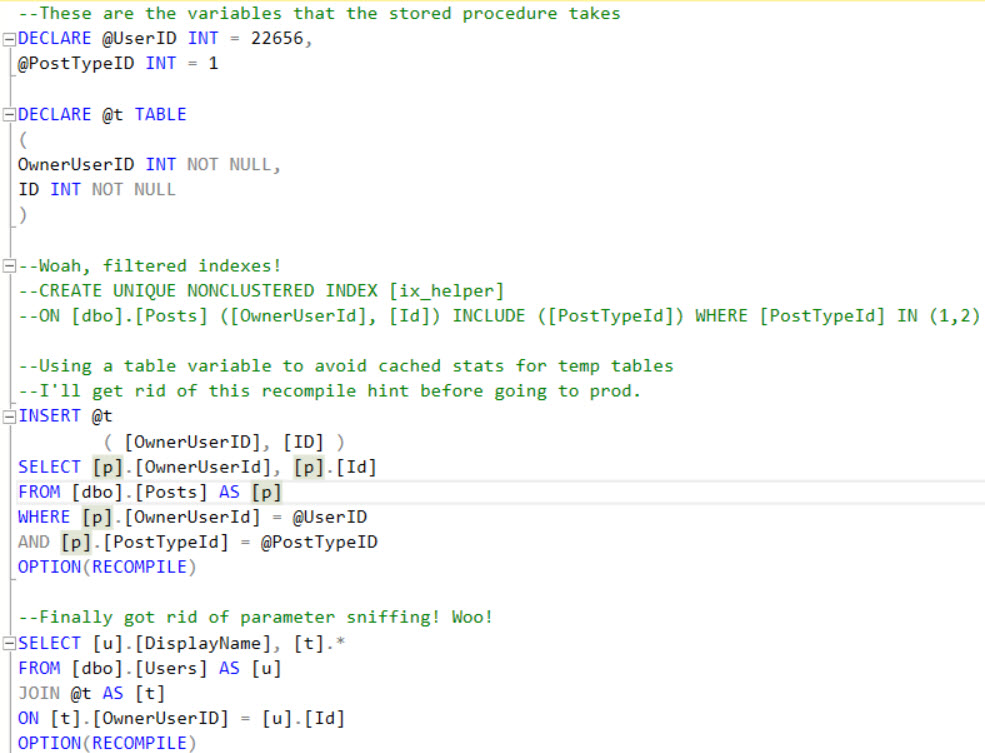
Breaking News: 2016 Query Store cleanup doesn’t work on Standard or Express Editions
5 Comments
If you’re using SQL Server 2016’s awesome new feature, Query Store, there’s a new bug with automatic cleanup. Books Online explains:
Automatic data cleanup fails on editions other than Enterprise and Developer. Consequently, space used by the Query Store will grow over time until configured limit is reached, if data is not purged manually. If not mitigated, this issue will also fill up disk space allocated for the error logs, as every attempt to execute cleanup will produce a dump file.
To work around it, you can manually clean up specific plans with sp_query_store_remove_plan and sp_query_store_remove_query, or just clear the Query Store out entirely with:
|
1 |
ALTER DATABASE (MyDB) SET QUERY_STORE CLEAR; |
We’ve already added an sp_Blitz check for this in the dev branch of the First Responder Kit (zip download), but just be careful using dev branch code since it’s not quite as well-tested as the master branch.