Let’s Make a Match: Index Intersection
Most of the time, when you run a query, SQL Server prefers to use just one index on a table to do its dirty work.
Let’s query the Users table in the StackOverflow database (I’m using the March 2016 version today), looking for people with a certain reputation score OR a certain number of upvotes:

If I create an index on each field, will SQL Server use it?

Diabolical. The cost on this query is 74 query bucks – not a small operation, and large enough to go parallel, but SQL Server still turns up its nose at the indexes.
But the indexes weren’t perfect – they weren’t covering. I was doing a SELECT *, getting all of the fields. What happens if I only get the fields that are on the index itself – the clustering key, the ID of the table?
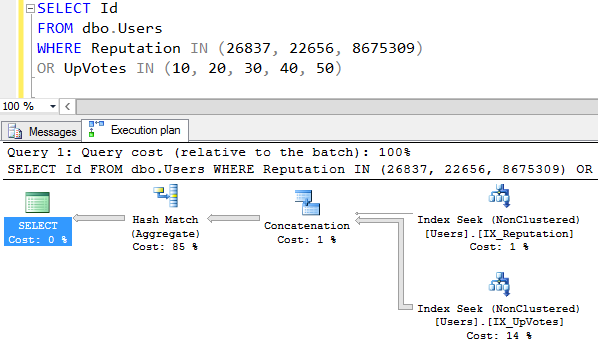
Presto! Now SQL Server is doing an index seek on two different indexes on the same table in order to accomplish my where clause.
Now, that’s not really index intersection – it’s doing two two index seeks to get two different populations of users – those that match the reputation filter, and those who match the upvotes filter. What happens if we change our query’s OR to an AND?
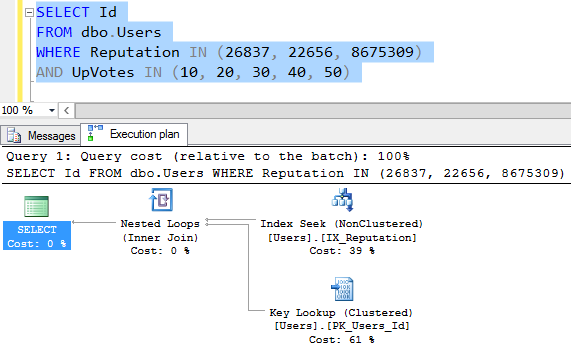
Now we’re down to a query plan you know and tolerate: an index seek followed by a key lookup. The reason is that the filters on reputation are extremely selective – there just aren’t that many users with those exact reputation numbers.
In order to get real index intersection – finding the overlapping Venn diagram in two filters – we need to use ranges of data that are less selective. It’s an interesting challenge:
- If either filter is too selective, we get an index seek on that one, followed by a key lookup
- If neither filter is selective enough, we get a clustered index scan

Presto! SQL Server is doing index seeks on two different indexes, on the same table, and then finding the rows that match both filters. I can count on one hand the number of times I’ve seen this in the wild, but that probably has to do with the kinds of servers I usually see. I’ll leave that interpretation to you, dear reader.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
indexes gone mild. LOL
Why dont you add Comedian to your true skills also. You are much comedian then interpretive dance.
Ah, so this is what my granddad was telling me about since SQL Server 7.0.
Nonetheless, hard to demo so thank you for the lovely post.
Would have been nice to see the reads, but I guess much less reads for the intersection.
Was there something in the screenshots that lines up w/ the comment “74 query bucks”? Or is that just an awesome saying? 😀
Jonas – no, I don’t show it in the screenshots – you have to hover your mouse over parts of the query to see its estimated subtree cost.