T-SQL & Development
Using WITH (NOEXPAND) to Get Parallelism with Scalar UDFs in Indexed Views
Scalar functions are the butt of everybody’s jokes: their costs are wrong, their STATS IO results are wrong, they stop parallelism when they’re in check constraints, their stats are wrong in 2017 CU3, they stop parallelism in index rebuilds and CHECKDB, I could go on and on.
Recently, we ran across yet another scenario where scalar UDFs were killing performance.
Someone happened to add a scalar UDF to an indexed view, and any query that touched that view couldn’t go parallel – even if it didn’t need query the function-based field!
Check it out, using my friend the Stack Overflow database.
First, let’s create a function that just returns the number 1. That’s it. No data access, no worries about how much work the function’s doing – it just returns 1, that’s it:
|
1 2 3 4 5 6 7 8 9 |
CREATE OR ALTER FUNCTION dbo.fn_Returns1 ( @Id INT ) RETURNS BIGINT WITH RETURNS NULL ON NULL INPUT, SCHEMABINDING AS BEGIN RETURN 1; END; GO |
Then let’s create an indexed view that includes that function:
|
1 2 3 4 5 6 |
CREATE VIEW dbo.vwVotes WITH SCHEMABINDING AS SELECT Id, dbo.fn_Returns1(1) AS One FROM dbo.Users; GO CREATE UNIQUE CLUSTERED INDEX IX_Id ON dbo.vwVotes(Id); GO |
Then run a query on that view:
|
1 |
SELECT COUNT(*) FROM dbo.vwVotes; |
We scan the index, and the cost is above my Cost Threshold for Parallelism, but it still goes single-threaded:

Why? Well, right-click on the plan, click View XML, and check out the highlighted area (emphasis mine):
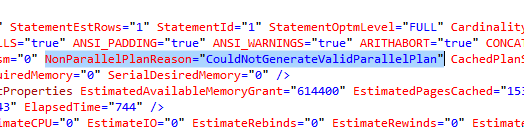
Doh. Scalar functions strike again.
But check out WITH (NOEXPAND)
Add that query hint, and look what happens: the query goes parallel!

Both plans have full optimization. Both hit the same index. I have no idea why you suddenly get parallelism when you use that hint – I just stumbled on it accidentally.
This may be related to a fix Paul White found in SQL Server 2016 last year – look for the “A New Option” section in that post. That one requires a trace flag, but I’m certainly not using that trace flag here. It might be that WITH (NOEXPAND) now triggers the same behavior in computed fields that the trace flag used to.
I have no idea what version/build this was introduced in – my testing was done on 2017 CU3. Feel free to talk amongst yourselves and try other versions/builds if you’re having the scalar-in-indexed-views problem.
Of course, the best answer isn’t to use the WITH (NOEXPAND) hint – as long as you’re in there mucking with the query, if you can, just get rid of the scalar function.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
I don’t have the ability to dl the full DB (no torrent ability), so I followed your advice from a few weeks ago and grabbed the smaller one for my testing. When I remove the function and just SELECT ID, 1 with both the WITH(NOEXPAND) and without, I am still getting pretty different results https://www.brentozar.com/pastetheplan/?id=SyYnAKnDz
Looks like I’ll need to do some more reading on WITH(NOEXPAND)
To be fair, they are not “pretty different” but there is a shift in where the work is being done between the two.
Yeah, database size definitely influences query plans for sure.
I may not be 100% accurate here but my understanding is SQL Server will interrogate the view and use the view definition for queries if it deems better. I’ve had to use the WITH(NOEXPAND) to avoid this because of performance issues with Indexed views before. My experience is that SQL Server is not really good at choosing the most performant option here but treating this as a regular view instead of as a materialized view.
Russell – right, but this isn’t just about hitting the view definition – it’s about getting parallelism as well due to the presence of the scalar. The call of querying the scalar versus using the indexed version of it has huge performance implications.
Super interesting. Working on an issue that should be a trivial change that resulted in a about a 1000x slow down, wondering if this would solve help by bringing parallelism back in.
By using NOEXPAND the optimizer “know” that it will NOT expand to access the underlying tables which uses the scalar UDF. Therefore, this let the optimizer generate a valid parallel plan. But, if the Optimizer “think” that it might use the underlying table then it “think” that there is an option that it will not be valid for parallel and therefore it must work synchronously