Demoing Latch Waits with Stupid Tricks
Say you’ve got PAGELATCH_UP or PAGELATCH_EX waits, and you’re wondering what might be causing ’em.
I’m going to keep the brutally simple approach of building a stored procedure to simply dump hard-coded values into a table at high speed. I don’t want to select from other tables since they might introduce some other types of waits, especially when I’m demoing concurrency quickly.
So let’s create a stored procedure that does an insert into a table:
|
1 2 3 4 5 6 7 8 9 |
CREATE OR ALTER PROC dbo.usp_TableVariableShuffle AS BEGIN DECLARE @MyTableVariable TABLE (ID INT, Stuffing CHAR(8000)); INSERT INTO @MyTableVariable (ID, Stuffing) VALUES (1, 'A'), (2, 'B'), (3, 'C'); END GO |
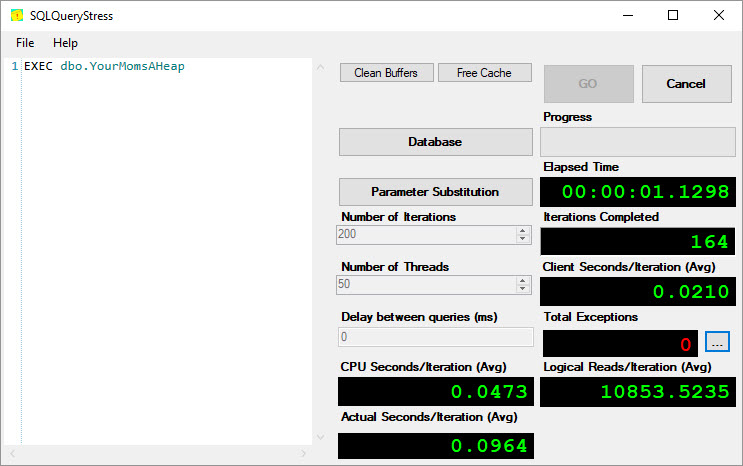
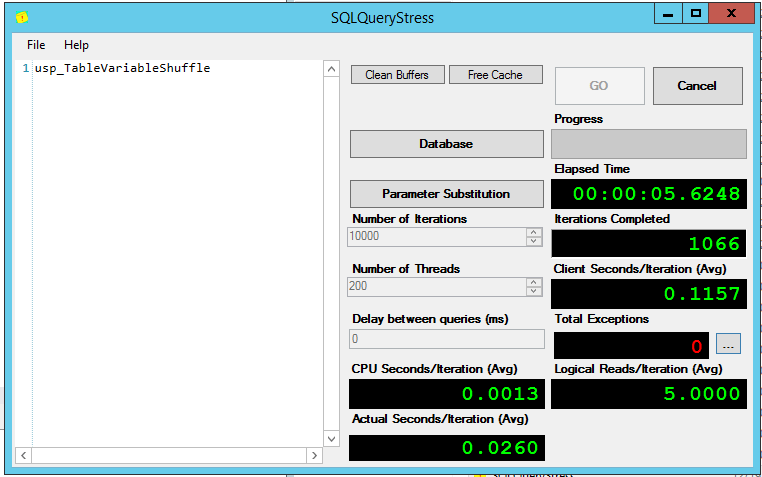
And then use SQLQueryStress to run 200 threads with it:
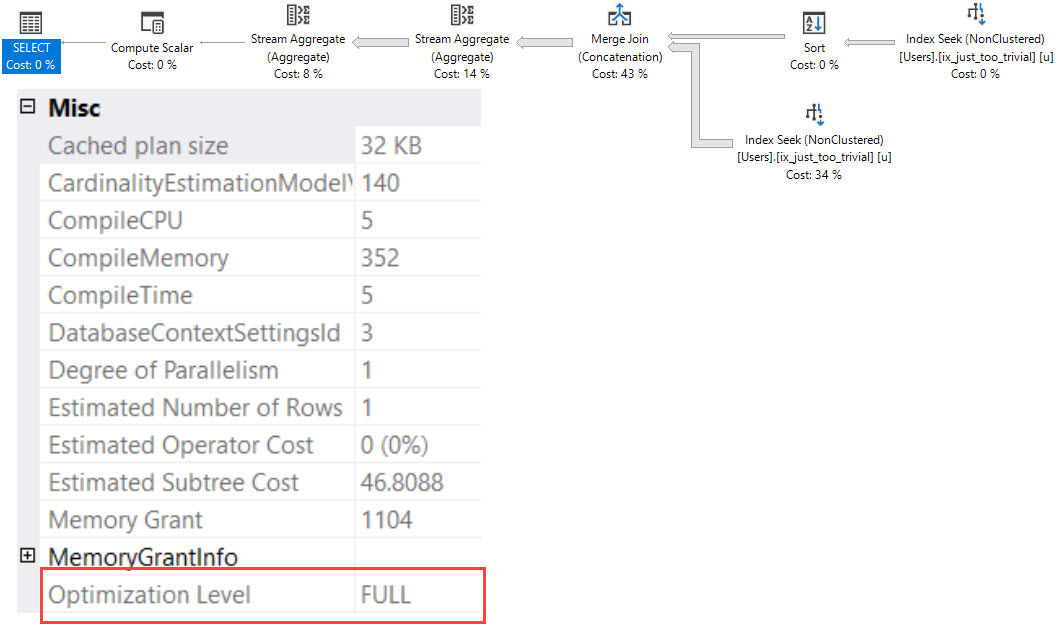
When we run sp_BlitzFirst @ExpertMode = 1 to take a live sample of wait stats, the results aren’t all that impressive:

Because frankly, our code isn’t all that impressive. We’re only inserting 3 rows. What if we insert a lot more? Let’s build SQL dynamically:
|
1 2 |
SELECT TOP 1000 '(' + CAST(object_id AS VARCHAR(20)) + ', ''Stuff''),' FROM sys.all_objects; |
That gives me a nice long list of values:

That I can dump into my stored procedure:
And now, when I run it from 200 threads of SQLQueryStress, the waits for inserting 1,000 hard coded values at a time – each of which needs a page for its whopper CHAR(8000) field – look a little different:

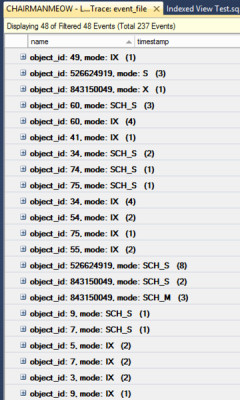
That’s what it looks like when your system is under heavy contention due to a lot of queries partying in table variables: in each second, each core on this system is spending 48 seconds waiting on PAGELATCH_UP. That’s awesome.
What about temp tables instead, you ask? Same symptoms: PAGELATCH_UP.
How about PAGELATCH_EX?
You don’t see exclusive locking on temp tables and table variables because they’re per-session. Global temp tables, however, that’s another story:
|
1 2 3 4 5 6 7 8 9 |
CREATE OR ALTER PROC dbo.usp_TempTableShuffle AS BEGIN CREATE TABLE ##MyTempTable (ID INT, Stuffing CHAR(8000)); INSERT INTO ##MyTempTable (ID, Stuffing) VALUES (1, 'A'), (2, 'B'), (3, 'C'); END GO |
Again, use your system-generated list of values to throw in 1,000 rows each time. Don’t bother selecting anything from the temp table or deleting the rows – that’d only slow us down. The result: exclusivity:

Now, everybody’s fighting over the right to insert into a single shared object, the global temp table. The same thing happens if you use a user table:
|
1 2 3 4 5 6 7 8 9 10 11 |
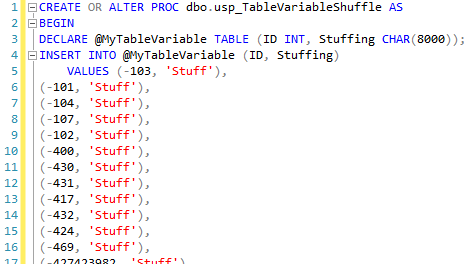
CREATE TABLE dbo.RealTable (ID INT, Stuffing CHAR(8000)); GO CREATE OR ALTER PROC dbo.usp_RealTableShuffle AS BEGIN INSERT INTO dbo.RealTable (ID, Stuffing) VALUES (-103, 'Stuff'), (-101, 'Stuff'), (-104, 'Stuff'), (-107, 'Stuff'), (-102, 'Stuff'), ... |
You end up in a brutal fistfight for exclusive rights to insert rows into an existing page:

You can change the severity of the waits by adding or removing fields on the tables involved. Want to simulate more contention on a single page? Remove the CHAR(8000) field. Want to throw big fields in the mix? Toss in some off-row NVARCHAR(MAX) – but like we generated a hard coded list of IDs ahead of time, do something similar with your other fields, too, lest you end up locked in contention for the source table.
When I’m facing unusual waits like these in production, I love demoing them with the simplest queries possible. This way, we can quickly show how hardware helps (or doesn’t help) a particular bottleneck – especially as opposed to just changing the code or indexes.