Building SQL ConstantCare®: What Database Growths Do You Care About?
34 Comments
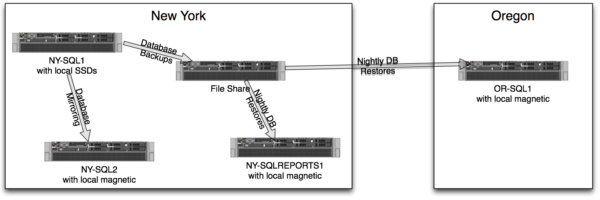
 SQL ConstantCare® alerts you when your databases have unusual growths.
SQL ConstantCare® alerts you when your databases have unusual growths.
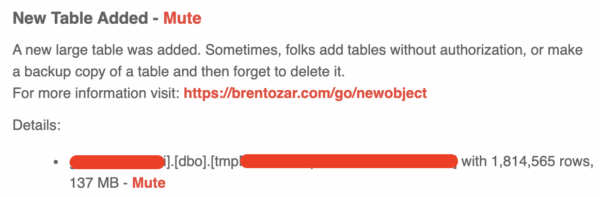
No, not like that one on your neck. And you should really get that checked out. No, I’m talking about a database that suddenly jumps in size, making you suspicious about whether somebody created a backup table or built a set of ridiculously large indexes.
But Richie was working on an update to the unit tests, and we started wondering:
How big of growths do you personally care about?
If you were going to write the rule that alerted you when your database jumped in size, what would be your own personal size threshold? Does it change based on the database’s size? (Think about 1GB, 10GB, 100GB, 1TB, and 10TB databases.)
Let us know in the comments! We’re curious.



 Update Oct 29th – classes are over. Thanks for joining in!
Update Oct 29th – classes are over. Thanks for joining in!