Production DBA
SQL Server Suddenly Frozen? You Might Be Snapshotting Too Many Databases.
Snapshot backup tools like Azure Site Recovery and Veeam are great for sysadmins. They let you quickly replicate a virtual machine to somewhere else without knowing too much about the server’s contents.
To pull it off, they use the Windows Volume Shadow Copy Service to do snapshot backups – often referred to as VSS snaps. In a nutshell:
- The VSS service tells SQL Server to freeze its writes
- SQL Server stops writing to each of its databases, freezing them
- SQL Server tells VSS, “Okay, I’m out”
- VSS creates a shadow copy of the data & log files
- VSS tells SQL Server, “You can get back to work”
- SQL Server begins writing again, one database at a time (called thawing)
These snapshot backups show up in system tables like msdb.dbo.backupset because when used successfully, they’re like full backups. It sounds like witchcraft, but it really does work, and it’s worked for years.
But when it goes wrong, it goes WRONG.
SQL Server freezes databases one at a time, serially, until it’s got them all frozen. This can take some time, and while databases are frozen, you’ll see blocking chains for writing queries (which can in turn block readers, too, depending on your isolation level.)
Because of that one-at-a-time problem, the SQL Server documentation explains:
We recommend that you create a snapshot backup of fewer than 35 databases at the same time.
Backup apps like Azure Site Recovery and Veeam don’t warn you about that, though. You just find out when your SQL Server suddenly feels like it’s locked up, with tons of blocking issues.
For example, here’s a screenshot from a client’s msdb.dbo.backupset table when Azure Site Recovery was trying to snapshot hundreds of databases all at once:
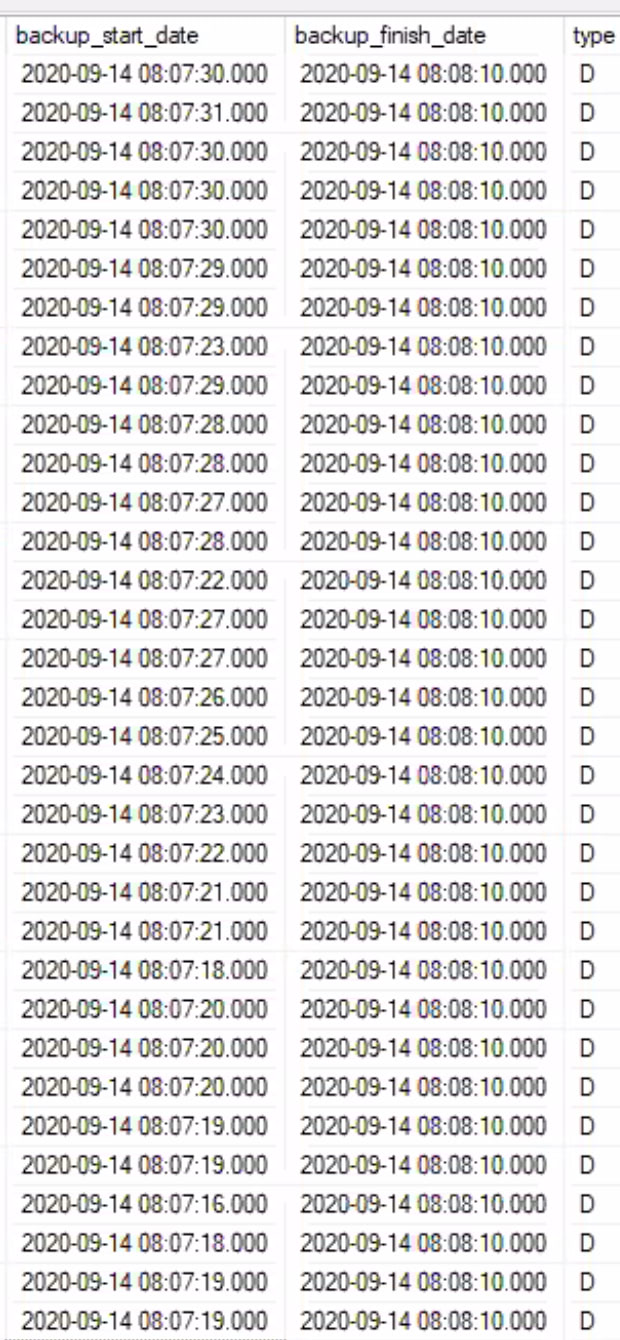
See how the backup_start_date and backup_finish_date are 40-50 seconds apart? That’s because SQL Server was slowly, gradually stepping through the snapshots of each database. Finally, they all “finished” at 8:08:10, but even that is a little tricky – in this case, they didn’t all thaw at the exact same time. (I’m guessing, based on the blocking storms I’ve been seeing lately, that the backup_start_date and backup_finish_date date/times don’t really correspond to the exact VSS freeze/thaw times.)
To make things worse, sysadmins just check boxes in tools like Azure Site Recovery and Veeam and tell them to take backups once an hour. The backups don’t necessarily happen exactly on the hour, so developers are left scratching their heads as to why seemingly simple queries suddenly just freeze every now and then for no reason.
How To Tell If It’s Happening to You
If you’re doing a health check, run sp_Blitz. We warn you about how many snapshot backups your server has taken recently, and in the upcoming October build, we also warn you if you’ve had snapshots spanning 35+ databases in the last two weeks.
Here’s how to see which databases are involved:
|
1 2 3 4 5 6 7 8 9 10 11 |
WITH snapshots AS ( SELECT TOP 5 bs.backup_finish_date FROM msdb.dbo.backupset bs GROUP BY bs.backup_finish_date HAVING COUNT(*) >= 35 ORDER BY bs.backup_finish_date DESC ) SELECT s.backup_finish_date AS snapshot_date, bs.database_name FROM snapshots s INNER JOIN msdb.dbo.backupset bs ON s.backup_finish_date = bs.backup_finish_date ORDER BY s.backup_finish_date DESC, bs.database_name ASC |
Or if you’re troubleshooting live, run sp_BlitzWho and look for blocking chains led by backup commands. You’ll have to move fast, though, because blocking storms like this can disappear within 30-60 seconds. I don’t recommend that you log sp_BlitzWho to table that often – that’s just too much overhead. That’s where 3rd party monitoring tools are more helpful.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
VSS based backups on 8k databases was “fun.” That backup vendor learned a lot that month.
Ouch!
It wasn’t the taking of the snapshot (or rather the acquiescence of the server ) that’s caused us issues. It was when the snapshot was released that the server would drop connections.
We’d been OK until we’d moved data centres and switched to rented kit. To resolve it the backups for the SQL Servers now use dedicated proxies (it’s what I’ve been told, who am I question it) and that fixed it.
Heh… yet another feature that can screw you to the floor. Lordy. Upgrades to new versions are getting damned scary. For example, the “Fast Inserts” change they made along with the caveats that create huge amount of “unused” space and you need a Trace Flag to turn it off because it’s on by default. Upgrading from 2016 to 2019 this year has me seriously concerned with all the supposed “improvements” they made. From what I saw, 2017 was a train wreck for performance (I’ve got it on my laptap). I realize that 2019 has some CUs under its belt but I find that performance improvement frequently aren’t. Like for the Cardinality Estimator “improvements”…. that was a bloody train wreck for us and we still have it turned off.
“Change is inevitable… change for the better is not”.
I experienced massive performance improvements in 2017 just by copying databases over to it. Mostly came from 2014 and 2012 and only a little 2016.
the 2014 CE upgrades at least in my case I noted were from the CE too correctly estimating shitty queries and not providing enough resources based on the number of records read and returned and the expense of getting them back. We couldn’t fix all our queries so we upgraded the worst servers to 2016 briefly then everything else to 2017. There were a few queries we had to add a legacy CE query hint to, but they were few and far between.
Jeff – I love that last line!
I joined a new company and first thing I noticed were I/O freeze in log. I immediately got a back up solution and implemented backup schedules. Everyone is more happy now !
I remember several years ago at Company X, when we were rolling native, a particular vendors product taking full non-copy only backups. Our internal support claimed they weren’t doing SQL backups, but the msdb backupset clearly showed they were. The vendors code was triggering the SQL VSS Writer, our only option was to disable the service. That product thankfully was retired.
AWS.. wasn’t there a similar limit recommended? Which would be expected unless they’ve written their own VSS provider..
*Yeah I am not naming and shaming.
When we implemented Veeam I was very concerned about the “freeze” especially with the servers behind Solarwinds. The NPM/Netflow data never stops flowing and I didn’t want 3 am phone calls every morning. These DB servers typically only had one large user database, so the issue with freezing sequentially never made itself known and things generally ran smooth. Until I inherited an environment that had a two member AG.
It wouldn’t happen daily, but I started getting alerts about the secondary getting a serious beating. It was to the point that the AG considered the secondary offline. This would occur during the time the backup was running, so it seemed pretty obvious where I needed to start looking. In addition to managing the DB servers the Veeam environment was mine as well, so nothing was in my way as far as making changes. All tweaks related to the backup job made no difference. No increase or decrease in frequency of the issue.
For our VMware, Azure and GCP environments I’ve written reports I get daily that tell me everything about the environments, backups, storage, etc. While looking at the VM detail I noticed that the secondary in the AG had volumes in two datastores. This was unusual as we generally keep DB servers together on dedicated LUNs/datastores. I discovered that the odd volume wasn’t just on a different datastore, it was also on a different SAN. The SAN was doing its own snaps during the time the Veeam job was running. Once the file location issue was cleaned-up the issues stopped.
Snapshots are the single most malignant cancer that has ever been added to systems administration. Its a hack tool that allows mediocre sysadmins to pretend like they can get away with not knowing what they are doing, and create absolutely colossal amounts of work and 40 hours days when they invariably go wrong.
Getting the call to be up all night when a AAG cluster with for availability groups containing several multiple terabyte databases all have to roll back at the same time? Check.
Getting the call when Veeam corrupts and entire AD FS farm serving 18 thousand users in 2 continents due to a snapshot bug? Check.
Getting the call when most of an exchange 2010 organization with a few dozen databases go offline in 6 server DAG requiring manual copy resume for every DB? Check.
Having to deal with absolutely horrendous queuing from tens of thousands of monitoring alerts and daily
internal mail blasts getting stuck immediately after that? Check.
Rebuilding SCCM in a university, just before fall terms, from an 8 month old copy of the site database because veeam decided stop clearing out snapshots in march and never alerted on it when most of the technical staff were out? Check.
Rebuilding an extraordinarily complex sharepoint farm manually following a power surge that took out the UPS and SAN because the snapshot based sharepoint backup wasn’t actually taking consistent backups, and the “low brow” backups that were definitely not as good as snapshots were cancelled? check.
Running a four month support ticket with Azure trying to make their snapshot based backup work while trying to fit ad hoc backups into the extremely firm budget limit of your client? check.
Naturally, the sysadmins that evangelized how awesome these snapshot based backups are, who couldn’t originally get the regular backups to work, would leave WELL before the 24 hours mark to get some sleep and food. But maybe I misunderstand when I hear them say that “snapshot backups just work without being messed with.”
The thing that I really, really hate with these solutions is losing capabilities that are available when using native backups. Want to skip the last full backup, restore from the one before and restore all the transaction log backups up to now? No. But the CHECKDB has failed and it’s not repairable without data loss. Want to do a page restore? No. Want access to the transaction log backups? No.
And then you have the conversations about the space to store your backups because you want to “go native”.
Yeah, agreed, I’ve had some awkward discussions with clients when it comes to the recent data corruption bugs in SQL 2019 and how their snapshot backup apps would have been helpless.
Now I’m worried.
Could you please link me to the data corruption bugs you’re referring too.
Not been as on top of SQL current affairs as usual. Life / family / global pandemic getting in the way.
Sure, I blog about those over at SQLServerUpdates.com.
Got it.
KB4538515 looks interesting ….. if it still existed 😀
Indeed. Most of them abstract your backup monitoring so heavily and helpfully tune out the ‘noise’ that you sometimes miss stuff. Commvault was the only one I found that managed your backups nicely, provided all the logging you needed and reliably produced SQL-relevant alerts. Learning it was quite a steep learning curve however, and you needed to take care to configure it to use regular SQL backups – there was some check box that made it back up, but not checkpoint.
Keith – you sound like you’ve got all the fun scars, hehheh!
we have a similunar issue with rubrik taking vm snapshots. we experience ag failovers within 1 minute of rubrik logging on. any suggestions for hostrecord ttl? has anyone else experienced this?
Asking in comments here probably won’t be productive – I would suggest contacting Rubrik for support.
Our firm uses Commvault (DBA’s have no access!! ) for full and diff scheduled backups, these use the Commvault SQL Agent & generally work well. However there are also daily vmWare snapshots initiated through Commvault which backup our virtual SQL servers (only the C drive), all other SQL drives are excluded. However on some of our VM’s we still experience these I/O is frozen messages at the time the snapshot is executed. No one can seem to explain this and being advised this is expected behavior, but I have my doubts as we have other servers not having this problem.
Does anyone have any thoughts here?
Darren – for support questions, your best bet is to contact the vendor or Microsoft rather than leaving a blog post comment here.
So what would best practice be. Setup the backup tool to backup the the Server C drive, then have the backups scripts backup the individual databases to a different server when that server is backed up with he backup tool. That way we can control when the databases are backed up, and the main tool does not control it.
Well, designing backups is a little beyond what I can do in a blog post comment, but click Consulting at the top of the screen if you’d like my personal advice on your architecture.
We’re doing hourly transactional backups on a 40+ databases. The tool is giving us a warning, and your test script above is flagging the transactional backups.
Can transactional backups also cause the database freezing problem?
Yes, depending on the tool.
Interesting. We’re using a scheduled maintenance plan to make the transactional backups. Would they cause the database freezing problem?
Unfortunately, personalized server troubleshooting is a little beyond the scope of what I can do in blog post comments – hope that’s fair.
Yes, very fair. Thanks for answering my first question!
Hi There,
ok what to do if application is not transparent for this freeze and JIT system ends up in manual reconnection from every computer ? Change backup supplier ? For example Veeam is doing this. I really dont know why they are not using a full mssql backup integration like HP DP. (they are using it only for transaction log backup)
Thx
Either switch to regular SQL Server native backups, or fix the application.
Hello Brent,
I ran your sp_Blitz Health Check, and got a “Snapshotting Too Many Databases”. We currently use Veeam for backup. Is it possible to get more information about these snapshots, such as which user is running it and when it happened? Thanks.
Unfortunately, inside SQL Server, we don’t have a way of knowing which user called the Veeam backups. You’ll want to check with Veeam.
Hey,
So if you have a vendor like Veeam – what would your recommendations be to them concerning the snapshot process. Thanks
For personalized advice about your particular system, click Consulting at the top of the site.
[…] ayn? anda dondurdu?unda da benzer semptomlar ortaya ç?kar. KB #943471, bu yüzden 35’ten az veritaban?n?n ayn? anda yedeklenmesini önerir. Bu limit a??ld???nda, yazma sorgular? için bloklanma zincirleri olu?ur ve okuyucular […]
Hi Brent, just for the record. The new link to the mentioned KB article. https://learn.microsoft.com/en-us/troubleshoot/sql/database-engine/backup-restore/error-when-you-create-a-snapshot
Thanks for that! I’ve updated the post with the new link.