
Microsoft SQL Server 2012 Always On AGs at StackOverflow
I recently finished helping the StackExchange team migrate their SQL Server 2008 infrastructure to SQL Server 2012. These servers power StackOverflow, DBA.StackExchange.com, the new AskPatents partnership with the US Patent and Trademark Office, and hundreds of other Q&A sites that together form one of the biggest web site networks. It’s one of the most visible success stories for the Microsoft web stack.
How StackExchange Used SQL Server 2008
Before we talk about their new infrastructure, let’s look at their business needs. I’ve blogged about how we designed the StackOverflow recovery strategy back in 2009, but things have changed a little since then.
We store two types of data, and let’s start with the one you already know – the questions and answers. The public-facing web site data (questions, answers, comments, users, reputation, etc) is valuable, but it’s not priceless. From a business perspective, we could afford to lose a few minutes of this data in the event of a disaster, and we could take a few hours of downtime. (SQL Server can indeed do zero-data-loss solutions, but they’re not exactly cheap, so I try to avoid those where I can.)
The second type of data is growing more and more valuable: Careers.StackOverflow.com, for example. Careers merges your online reputation (like the number of answers you make on StackOverflow) in with your traditional resume. Employers can find people who don’t just say they’re good at .NET – they actually are, and they’ve proven themselves by getting high votes from their peers. Employers pay to post tech jobs and reach the best candidates. There’s real money involved with this kind of data, so a few hours of downtime is less acceptable.
Here’s how StackExchange used SQL Server 2008 for data protection, simplified a little for illustration:
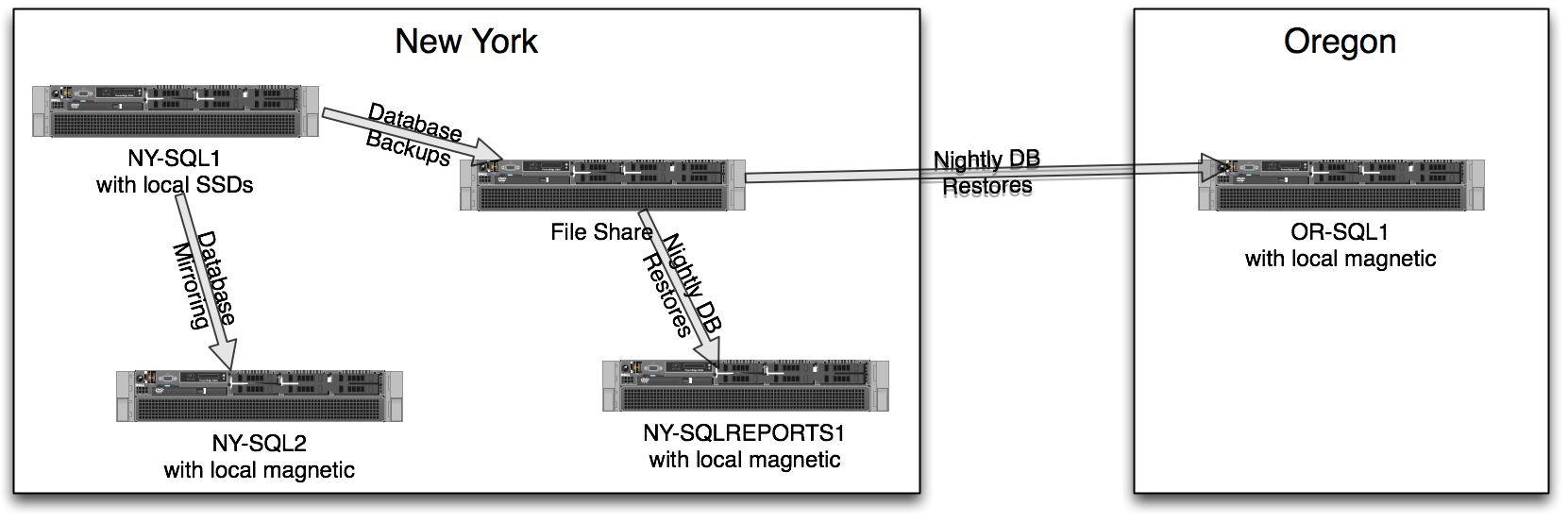
The servers:
- NY-SQL1 – primary. All web site connections go here.
- NY-SQL2 – hot standby using SQL Server asynchronous database mirroring. When NY-SQL1’s not doing transactions or playing sudoku, it sends the transaction log data over the network wire to NY-SQL2, which then applies the same changes. If NY-SQL1 had a serious hardware failure, we could manually go live with NY-SQL2 with a little work. Note that the storage doesn’t have to be the same – although that can introduce some challenges. Unfortunately, this server isn’t accessible to end user queries – its only purpose is madly scribbling down the live transactions.
- File Share – I’m a big believer in doing your full and transaction log backups to a different server, directly over the network. If you back up locally and then copy to a network, you’ve got more things you have to manage, and more things that can go wrong.
- NY-SQLREPORTS1 – once the databases are backed up to a file share, other SQL Servers can restore the backups for development or reporting purposes. You can also run DBCC checks against these databases.
- OR-SQL1 – offsite server with a delayed, somewhat out-of-date copy of the NY-SQL1 databases. If we lost the entire NYC datacenter, we could go live offsite, but we’d lose the changes since the last nightly backup.
That infrastructure diagram is simplified, and there’s some other business needs I’m not covering here. In reality, we had multiple sets of these servers, and the automatic backup/restore strategy was more complicated. I explained one version of this in my post on how to really compress SQL Server backups.
This setup worked well, but it entailed a lot of moving parts: database mirroring, log shipping, manual failovers involving a lot of scripting, and some painful management. I was really excited to simplify the infrastructure with SQL Server 2012.
Why SQL Server 2012 Made Sense for StackExchange
Microsoft brought its A-game to SQL 2012 when they introduced AlwaysOn Availability Groups. Now, along with the production SQL Server, we can have up to four more replicas in any number of datacenters. The replicas stay within a few seconds of the live server, yet people can query the replicas without blocking production load. This is awesomely useful for things like API.StackExchange.com and the Data Explorer (which lets anyone query any Stack database live).
Here’s a simplified version of the new SQL Server 2012 infrastructure:

Now we’ve got three separate pieces of hardware, and their purposes are a lot simpler:
- NY-SQL1 – the primary StackOverflow database.
- NY-SQL2 – the secondary StackOverflow database. NY-SQL1 sends transaction log data directly to this SQL Server, which then applies the updates. Other users (like API and Data Explorer) can query this server, and we could run backups here (but we don’t, for reasons I’ll explain later).
- OR-SQL1 – the offsite copy. NY-SQL1 also directly sends transaction log data here – it doesn’t flow through multiple replicas. Other users can query this server too, so we can make use of both datacenters’ internet connections if we wanted to. We run offsite backups here, so we’ve got redundant backups in both NYC and OR.
A little bit more about the backups – while SQL Server 2012 can indeed offload backups to replicas, the Stack team chose to continue doing their backups on the primary. Our logic was that if replication broke, we wanted to continue to get good backups – something you can’t guarantee if the backups are happening on a secondary. Therefore, we do full and transaction log backups on the primary (NY-SQL1) plus full backups on OR-SQL1 to have local offsite copies.
This diagram has a cluster, but no shared storage. This is one of the most attractive features for StackExchange because they wanted to avoid buying complex, expensive shared storage for this project. They’re speed freaks, and it’s tough to beat local SSDs in RAID 10 for that.
Finally, this diagram is really, really oversimplified. In reality, we’ve got:
- Multiple clusters – one for the highest load sites, and one for everything else
- Multiple availability groups – because we want to be able to fail over databases in groups.
- Multiple live sites – for example, NY-SQL1 doesn’t have to be the primary server for all databases in the cluster. Some sites have their primary home in Oregon rather than NYC.
- Multiple networks, differently powered servers, and more
The new infrastructure solved StackExchange’s business problems, but it introduced a lot of technical challenges.
Our Challenges with Availability Groups
We found a new clustering bug in Windows 2008R2. One night, all four of the SQL Server instances hosting secondary replicas crashed at the exact same time – across two separate clusters. This clearly was bigger than a SQL Server issue since it was happening in separate clusters, so we opened up a Microsoft support case immediately. Thankfully, it didn’t affect the primaries, so we were able to keep StackOverflow live on SQL Server 2012. After weeks of troubleshooting (and multiple crashes per week in the meantime), Microsoft narrowed it down to a race condition in Windows Server’s clustering code and gave us a hotfix. (It hasn’t gone public yet, but I’ll blog about that when it does.) UPDATE Dec 2012 – http://support.microsoft.com/kb/2777201
We ran into networking issues that we still don’t understand. While going live with the second set of clusters, we were stuck for hours with known problems with Windows caching ARP addresses. Once we got past that, we ran into the same symptoms described in this Exchange 2010 cluster post. SQL Server 2012 relies on Windows clustering in much the same way as Exchange does, so we tried the Exchange fix – changing an IP address temporarily. It worked.
We ran into worker thread issues in SQL Server. In the middle of the night (doesn’t that always happen?), one of our primary servers ran out of worker threads and simply stopped sending data to the other replicas. When more threads freed up again, it didn’t restart sending data. Microsoft has blogged about the number of worker threads required for AlwaysOn AGs, and we were well above that number. We manually raised the number of worker threads anyway, and SQL Server still didn’t start replicating again. There isn’t a command to restart Availability Group communication in cases like this – ALTER DATABASE XXX SET HADR RESUME doesn’t work because it’s not at the database level. To fix it without restarting the replicas, Nick came up with the idea of just changing a replica setting (like from read-only-intent to allow-all-reads) and that started communication flowing again.
Through all of this, the troubleshooting tools failed us. During our worker thread issues, the AlwaysOn dashboard reported that everything was A-OK – even when it had stopped replicating data. Even worse, the log_send_queue_size field in the DMV sys.dm_hadr_database_replica_states stopped updating itself once we ran out of worker threads. It looked like only 10MB of data was queued up – but we were actually behind by almost 10GB. Thankfully we caught it manually within a few hours, but this could have been a catastrophic problem. Using AlwaysOn Availability Groups is like flying a plane: you can’t just rely on one metric on one gauge and think everything’s okay. You need multiple copies of every gauge, and you have to watch ’em all.
Microsoft’s support failed us for a while too. I don’t envy Microsoft support at all; it’s really tough supporting a product as big as SQL Server. New features make things even tougher because it’s hard to anticipate what data will be needed to solve a support case. However, I was pretty frustrated when support repeatedly asked questions like, “How is the cluster configured?” SQL Server has had complex integration with Windows Failover Clustering for years, and support needs a better way to get the data they need. Problems with AlwaysOn Availability Groups will require a lot of background information to get a good fix, and right now, the answer is spending a lot of time on the phone trying to explain things. That led to a bad experience for the Stack guys.
I had to fact-check Microsoft support’s answers. During the investigations, I monitored communications with support and interjected where necessary. For example, one support engineer told StackExchange to enable full memory dumps – without any hint of a problem that might cause on a box with 384GB of memory. I had to explain to the support engineer why he shouldn’t be making that recommendation without also explaining the drawbacks. This kind of thing isn’t a new problem with SQL Server 2012, and customers shouldn’t have to get a Microsoft Certified Master involved just to filter answers from Microsoft support.
I don’t think this stuff will get better with SP1. For years, I’ve heard people say, “I’m not installing the first version of Windows/SQL/Exchange/AngryBirds. I’m going to wait until Service Pack 1 comes out.” SP1 usually brings a slew of fixes, and indeed, there’s already been three cumulative updates. Waiting for SP1 also gets you the benefit of better community resources – I’ve already Googled for new error numbers and come up empty, which means I’ve got some blogging to do. But even with bug fixes and better resources, I don’t think AlwaysOn Availability Groups is going to get any easier to design, configure, and troubleshoot. It’s a very complex feature built atop a lot of complex features.
The Bottom Line: It Worked, but It’s Not the Easy Button
Microsoft SQL Server 2012’s new AlwaysOn Availability Groups solve real business problems at StackExchange, allowing us to aim for higher availability with shorter failover times, but it introduced some really tough challenges.
The StackExchange team consists of the smartest sysadmins I’ve ever had the pleasure of working with (and they’re hiring!) and they don’t have a full time SQL Server DBA. I wouldn’t recommend SQL Server clusters without a full time database administrator, though, and ideally a full time team of DBAs. StackExchange’s implementation wasn’t really that complex, and yet we still spent days and days working with Microsoft support to get the bugs ironed out. Along the way, we ran into Windows and SQL Server bugs – always a risk with a new feature – and it requires a highly skilled team to get to the bottom of these complex problems fast. Thankfully StackExchange has that team, but when faced with similarly complex challenges, I’m not sure how other companies are going to react.
Learn more about the challenges of AlwaysOn Availability Groups at BrentOzar.com/go/alwayson. If you’d like help navigating the obstacles in your own AlwaysOn infrastructure, contact me.

25 Comments. Leave new
Rampant FLOSS fanboy insists that the entire set up could be replaced with a single MySQL server in 3…2…1…
Brent – Am curious,are you aware of any similar Issues with Windows Server 2012 Clusters(Bug in Cluster Code for Race Condition) or did MSFT said, it’s just with Win 2008R2?
Sreekanth – support said the bug has been fixed in Windows Server 2012.
Thanks Brent!
Brent I know this wasn’t the focus of the blog post; but can your talk more about the rationale of using SSD’s in the primary and magnetic in the secondary machines. Maybe I’m reading too much into the diagram. Great Post
Jason – short answer: it’s cheaper to get higher capacity with magnetic drives. While Stack did get funded, it’s not unlimited moolah. 😉
ahh ok, I thought maybe it was due to the MTBF characteristics of the two media types. I was reading too deep into the diagram. Thanks for clarifying.
Thank you for posting this. Though we are not in 2012 yet, always a pleasure to expand knowledge and learn from a guy who has made expensive mistakes on other people’s hardware. Hehe
Brent – Thanks for sharing your experiences with the overwhelming majority of us for whom AlwaysOn Availability Groups remain something we are only familiar with on an academic level. A very generous contribution by you. It amazes me how many times I have to learn that there is no easy button for these types of complex problems. MS marketing fools you once, shame on them. MS marketing fools you every three years for your entire career… well…
Image trying to implement and support it on servers using Windows Core.
We are re-architecting our SQL infrastructure and this time around we’ve decided to go with stand-alone SQL Servers that take full advantage of VMWare clustering for HA. The reasoning. . .fewer complexities related to clustering setup/maintenance, immediate failover isn’t a necessity and we don’t have the necessity to scale-up vs. scale-out so we can take advantage of commodity hardware (dual hex-core w/ 96 GB RAM).
Does anyone familiar with these variables have any input for or against this solution?
Jerry – how do you plan to handle Windows patches, SQL patches, and full-C-drive conditions? (Like some bozo downloads a bunch of ISO files to the C drive or Windows Updates fill it up and knock the machine offline.)
That thought occurred to me as well. For short term recoverability I’ll be snapshotting the VMs. For long term recoverability I’ll leverage vRanger backups (nightly) to cover the OS/Server backups and of course a good SQL Server backup policy.
The only bozo that would fill up the C drive is is me! I’m told that with Windows 2008R2 you can now extend any volume (even the C volume through diskpart).
Thanks for the response. Much love.
On the worker threads issue, were the HADRthreads in SUSPEND, if so what caused them to go into suspension?
So are you saying that once there were available worker, the threads responsible for syncing AG data did not come out of suspension, and did so only after the AG was reset because of change in settings?
Was the Secondary Sync or Async?
How much time did you wait before Nick changed the settings?
I ask all this because I am trying to recreate the same issue with AG for similar loads.
Rohan – we worked with Microsoft to recreate the scenario, and they had difficulties with it, so I don’t think it’s productive for us to try here. We spent weeks working with them, and explaining the whole scenario is beyond what I can do in a blog comment. It’s pretty elaborate. Thanks though!
I’m wondering if hurricane Sandy caused StackOverflow to spin up their Oregon DR site? if so, it’d be cool to post a follow up story on the event and how things went down and how SQL Server 2012 performed. Sandy might also be a good time to remind everyone of the importance of having a DR strategy … espcially testing the DR before disaster strikes.
Look forward to hearing your talks as Portland SQL Saturday and PASS Summit.
Mike – yes indeed it did! They’ve just published the first blog post about this morning’s failover:
http://blog.serverfault.com/2012/10/30/failing-over-stack-overflow-and-stack-exchange-for-sandy/
There’s also links in the post to the failover test they did two weeks ago. That test made a world of difference in their preparations.
Thanks Brent and Overstack team sharing us with AG. Looking forward more blogs about AG!
Any idea what would cause an AlwaysOn group in synchronous / automatic fail-over configuration to *not* fail over? I had a hard memory dump on the primary node that crashed the SQL processes but the AG did not failover to the other node. Nothing in the AG log even indicated a problem, so SQL wasn’t inclined to do anything but sit there until I manually restarted the services that crashed.
Matt – unfortunately this is beyond something I can troubleshoot in a blog post comment. We teach classes about this – coincidentally, I have 2 hours on this in Newark tomorrow!
Hi Brent, My understanding is WSFC which is a pre-requisite for AlwaysOn AG, doesn’t need block level replication or anything similar on hardware level to enable WSFC (between VMs in different data centres) and alwaysOn Ag.is this correct thanks. Faran
I was talking about block level replication at SAN level
Faran – correct, you don’t need block level replication at the SAN level.
Hi Brent,
Very nice posting. thanks for sharing your challenges in AG setup. I have one question. what could be reason node status changed to Quarantine state of one of my existing AG – DR setup. but no impact in instance and application side during Quarantine, How overcome this issues in feature?
Thanks
Anand
Thanks, glad you like my work. Unfortunately I don’t do free Q&A sessions here in blog post comments.