Office Hours in the Valley of Fire
1 Comment
I took the Graffiti Gulf 356 out to the Valley of Fire State Park to exercise it, and took your top-voted questions from https://pollgab.com/room/brento.
Here’s what we covered:
- 00:00 Start
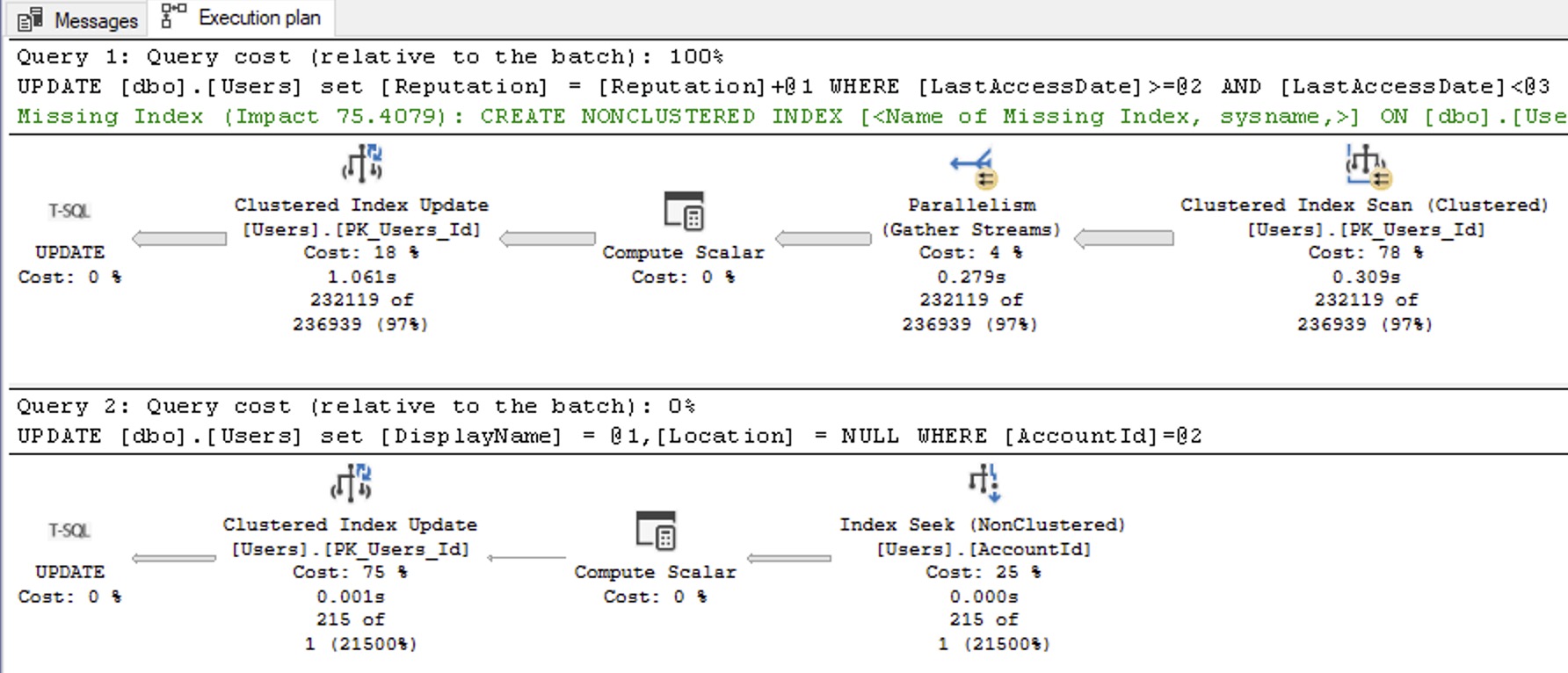
- 01:39 mailbox: Hey Brent! I’m really enjoying your prerecorded training classes. Quick question,I’m running sp_BltizCache @SortOrder = ‘reads’ on our DW server and receiving a priority 1 warning of Plan Cache Instability. How meaningful is this warning on a DW server?
- 02:49 Briggers: Hi Brent. I have inherited an intense AG with 1 database, utilising an async read-only secondary. Is there a way to help reduce the size of a redo queue? For example reducing the number of checkpoints (Automatic) on the primary?
- 04:00 DoesTimeReallyExist: Hi Brent! I prefer to learn SQL Server in depth instead of learning no-SQL or PostgreSQL and TimescaleDB. What do you think?
- 04:31 Aksel: Duplicate Index How to explain a situation where there are indexes A (col1, col2) and B (col1, col2, col3, col4), and there is a query that checks the values of col1 and col2. If the query uses index A, no memory grant occurs. If the query uses index B, a memory grant occurs.
- 05:31 Cameo: What are your pros / cons of using local time vs UTC time for OS clock running SQL Server? Which do you see more of out in the field?
- 06:51 mailbox: My friend’s company pays only to license 4 cores enterprise(SA) on a reporting server. Best I can tell, we don’t need enterprise as of now. However, we might need it in the future. Is it a good idea to switch to Std edition on same budget, thus increasing core count?
- 08:00 adba: I am seeing high CPU on a SQL server VM,I have added more cpu and tuned the query, but we still see the issue. What parameters do I need to monitor to show it is a problem on the host side.
- 08:59 GenXerTiredOfTheBabyBoomers: You have probably got this question often, but getting up there in age/end-of-corporate-life, how does one become a consultant? I have decades of experience with MS SQL, Windows OS, and networks, yet have trouble crossing the great divide of corp to cnslt.
- 10:18 SportsFan101: What are your thoughts on the new JSON data type in Azure SQL? Will we see this feature in the new on-prem version, SQL Server 2025?
- 11:28 Bandhu: When doing row vs page compression for canned SQL, do most of your clients do all row compression or all page compression or some combination?
- 11:48 mailbox: In your experience, when is it time to upgrade server hardware? Maybe I should ask, how often should we try to upgrade the server hardware of our SQL Servers? My friend says that they have VMs on hosts that are 8 years old.
- 12:53 Juan Pablo Gallardo: In pure ERP environments, with no user queries or tasks outside the ERP, is it safe to say that any deadlock is responsibility of the ERP vendor to solve?
- 14:06 Dopinder: What criteria do you use when evaluating standup desks? What is your favorite brand and model?
- 14:44 Vasilis Hadjiloucas: Should I exclude my antivirus software from scanning my FILESTREAM container in SQL Server? What are the potential risks or benefits of doing so?
- 15:17 CryingInTheCorner: Hi Brent, you still didn’t update most of your Mastering classes since Sql Server 2022 came out… :'(
- 16:41 Dumb dude: If you had a server that was having a lot of resource contention and you were only allowed to add CPUs or Memory, but not both, without cost being factored into it, which would you pick.
- 17:21 About the 356’s Graffiti Gulf paint job
- 18:40 Dopinder: Can a single DBA manage a new SQL AG or is a team of DBAs recommended for AG administration? What do you see in the field?
- 19:31 mailbox: What is it like to work as a DBA for a consulting firm? Is it just non-stop performance tuning fun? Or are their lots of nights and weekend work?
- 20:50 Eddy Grant: When upgrading Azure SQL VM from 2019 to 2022, is it ok to do in place migration since we have snapshot backups or should we logship to new VM hardware?
 If your company is hiring, leave a comment. The rules:
If your company is hiring, leave a comment. The rules: This week at the PASS Data Community Summit in Seattle,
This week at the PASS Data Community Summit in Seattle,