Performance Tuning
Why Adding Some Memory Doesn’t Fix All Caching Problems
It seems obvious: add some memory, and SQL Server should be able to cache data, thereby making queries run faster … right?
Well, if you can’t cache everything you need for a query, you might be surprised to find that SQL Server may still read the entire table up from disk, regardless of what parts of the table are currently cached in memory.
Let’s start with a little setup. I’m going to set the server’s max memory at about 8GB, which isn’t enough to cache the entire Comments table from the Stack Overflow database. (I’m using the 2018-06 version of the database, in which the Comments table is about 21GB. I’m also going to drop all of my nonclustered indexes to force SQL Server to do a table scan.
|
1 2 3 4 5 6 7 8 |
EXEC sys.sp_configure N'max server memory (MB)', N'8000' GO RECONFIGURE GO USE StackOverflow; GO DropIndexes; GO |
Then in order to demo the problem as quickly and easily as possible, I’m going to write a query that you probably wouldn’t normally write. I’ll take the Comments table of the Stack Overflow database, which has a clustered primary key on the Id column, and query it to find all the comments Jon Skeet has ever made:
|
1 2 3 4 |
SELECT * FROM dbo.Comments WHERE UserId = 22656 ORDER BY Id; |
A couple of things to recognize:
- There’s no index on UserId, so SQL Server will need to scan the entire clustered index
- The ORDER BY Id actually pays off a little for the clustered index scan – because we asked for the data sorted by Id anyway
The first time the query runs on 8GB RAM…
If we look at the actual execution plan, we spent 48 seconds waiting on PAGEIOLATCH (storage reads) in a 22-second query:
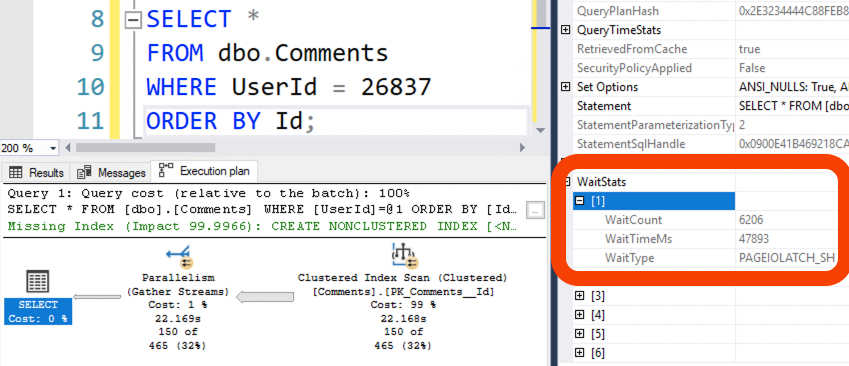
During that 22-second query, we read the entirety of the Comments table up from storage. We can prove that by checking sys.dm_io_virtual_file_stats before & after the query runs. That’s where SQL Server tracks how much it’s read & written from the various data & log files:
SQL Server read 21GB of data from the Stack Overflow database, which is spread across 4 data files. That’s the size of the Comments table. Okay, so far so good.
The second time the query runs on 8GB RAM…
We’ve already got at least some of the table cached in memory, right? If we rerun the table again, surely our PAGEIOLATCH waits will drop a little because the buffer pool is warmed up, right? Right?

And we read the same 21GB of data up from disk again:

The problem is that this query needs the data sorted in the order of the clustered index’s Id, so it’s going to do a scan from the beginning of the clustered index to the end. When the query completes, sure, some of the Comments table is cached in memory – but only the end of it, the highest Ids. So when our query starts again, it’s like Groundhog Day – we begin reading the table from the beginning again.
Adding just some memory doesn’t fix this.
Let’s amp our server’s memory up to 16GB and try the query again:
|
1 2 3 4 5 6 7 8 9 |
EXEC sys.sp_configure N'max server memory (MB)', N'16000' GO RECONFIGURE GO SELECT * FROM dbo.Comments WHERE UserId = 26837 ORDER BY Id; GO 2; |
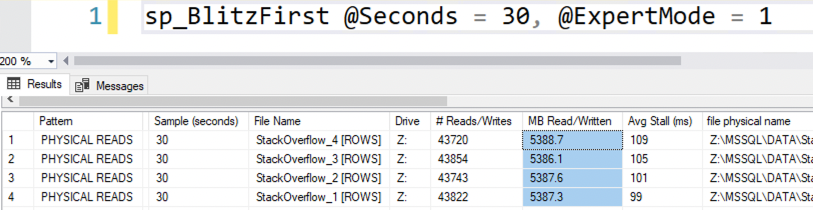
I’m also running the query a couple of times just to make doggone sure the buffer pool is warmed up and that SQL Server’s total memory has risen up to match its target. Then, run it a third time, and check wait stats and storage reads:

The query still takes 22 seconds, and we still wait about a minute on storage because we’re reading it all back up from disk again:

But cache the whole table, and magic happens.
Raise the server’s memory up to 24GB, enough to cache the 21GB Comments table, and run the query a couple times to prime the pump:
|
1 2 3 4 5 6 7 8 9 |
EXEC sys.sp_configure N'max server memory (MB)', N'24000' GO RECONFIGURE GO SELECT * FROM dbo.Comments WHERE UserId = 26837 ORDER BY Id; GO 2; |
Suddenly the query finishes in 3 seconds instead of 22, and we don’t spend any time waiting on storage whatsoever:

Because we did no physical reads at all – the only activity during this span was a little writing to TempDB by sp_BlitzFirst itself:

Keep in mind that this is a simplified demo to illustrate a complex problem:
- Real-life queries are more complex than this, especially in how we have to dig into the plan to understand why they’re scanning an index in order.
- Adding an index to get a seek is a great solution – but only if you’re reading a relatively small portion of the table. If you seek in and read a range of rows, especially on real-world-sized data sets, you can still hit this problem.
- Real-life servers serve multiple databases at a time, each running multiple queries. It’s hard as hell to cache everything you need.
- SQL Server uses memory for lots of things, not just caching data, and they interact in tricky ways.
- This is especially tricky in cloud VMs where you might want to make a giant leap up in memory, but you’re required to buy way more CPUs than you need in order to get more memory.
The point of the story here was to explain why adding memory – even doubling or tripling it – might not be enough to put a dent in PAGEIOLATCH waits. If SQL Server wants to read pages in a specific order, and the pages it wants aren’t in memory, it will throw out cached pages on the very same object – only to read those pages back up from disk again later while executing the query.
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
Yet another well-written insight into the intricacies of SQL Server. Thank you, Brent.
Thanks, glad you liked it!
Good stuff, thank you good stuff, thank you
Thanks, glad you liked it!
Brilliantly explained example. Many thanks
Great explanation!
Thanks!
This is brilliant explanation, thanks Brent. Yet another reason to minimize the use of the “order by” clause.
Glad you liked it!
Hello Brent,
Great article as usual, regarding the cloud infrastructure why it is required to buy way more CPUs than we need in order to get more memory?
Thanks
because MS / Amazon wants to make money?
And there are some hardware limitations too of course. Try to buy a Server with 2 TB RAM but only 4 cores – you can’t. And even if you usually find mostly high end servers with much RAM and much CPUs in the cloud / VMs, it can unbalance your systems, if one VM takes only 4 cores but 1 TB RAM and the other 28 cores have to share the remaining 1 TB RAM. This may be fine for some CPU intense workloads, but usually you need both, CPU and RAM
I wonder, why the SQL server is so stupid in this case. I can’t rembember the name of the feature, but as far I know, it would share the data stream between two sessions, if you would have run the same query a second time and – since the second query was started later – session two would read the missed data from the first pages after it had reached the end (and session one is done).
Theoretical it could do the same thing here.
It’s called Merry-Go-Round scans, and no, that won’t work if you need to read the pages in order as I explained in the post.
well, it could either insert a SORT operator into the plan (yes, I know, it would lead to another execution plan which opens several other problems as plan cache pollution / recompiles). Or it does the same thing as when the plan goes parallel, where the streams has to bring together too (it could even “simulate” paralleslism by executing one thread that reads the in-cache-data and let the other threads wait until it is done before doing the phyisical reads.
And of course it could simply do a backward scan. Or it just puts the physical read data to the start of its sorted list (or to the end, when the first part of the table is in the cache or to start and end when parts of the middle are cached).
I don’t say, that it is a 2 hour change to the base code of SQL server, but it would be possible. On the other hand – why should they make the cheap editions much better …
So I think you’re suggesting that before SQL Server execute a query, it should try to examine which pages are in memory, and then build different execution plans based on that?
Thank you for this valuable information, Brent! Great article.
if active/needed pages are in memory, then fine, but the SQL Server engine is designed to be pretty good at doing disk IO. Unfortunately, most infrastructure people do not understand what disk IO is, and configuring a system/VM that sucks at I/O could result in SQL Server that sucks
Hmm, let me see if I captured that right:
“If SQL Server doesn’t need to do IO, then it’s good at IO”
By that logic, I’m good at everything! Woohoo!
[…] In the client example that prompted this blog post, there were half a dozen update statements, each of which did a table scan on a giant table way too big to fit into memory, so storage was getting hammered and the buffer pool kept getting flushed due to this issue. […]