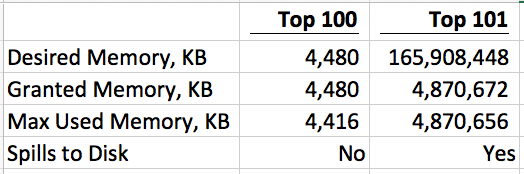
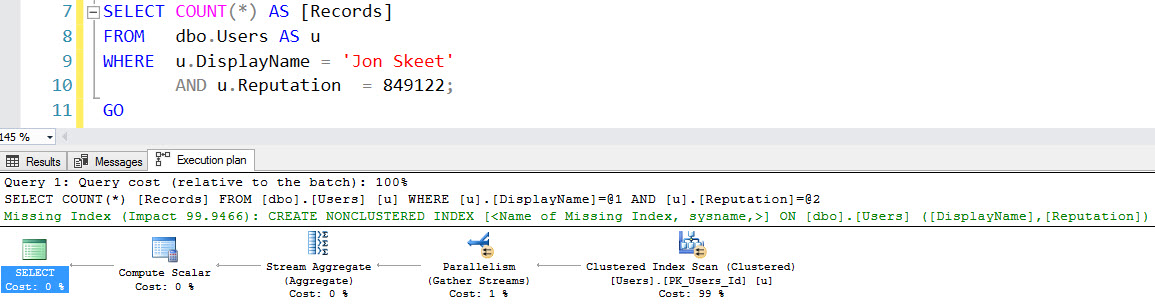
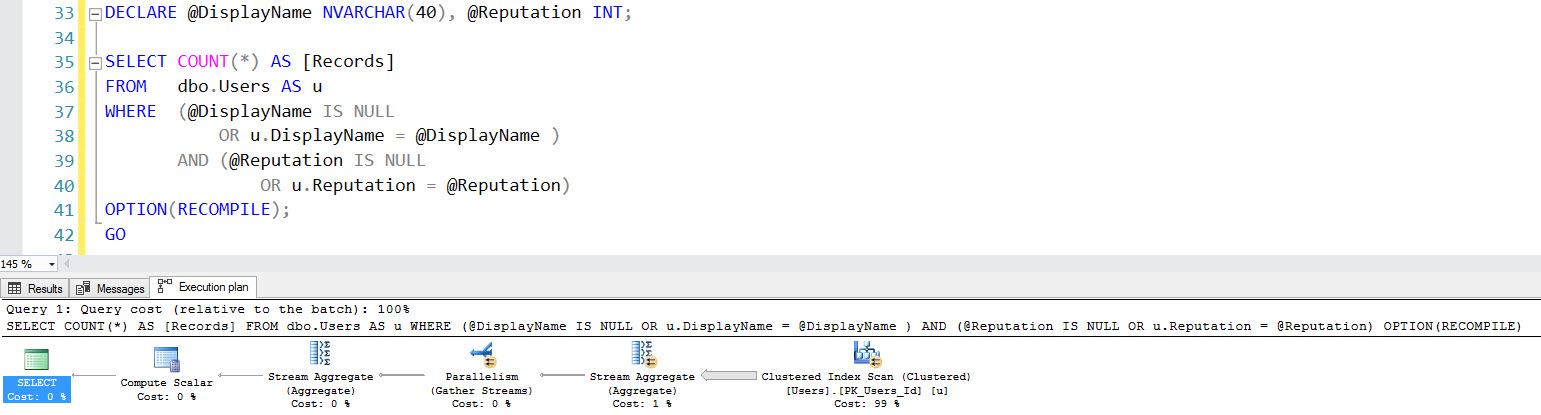
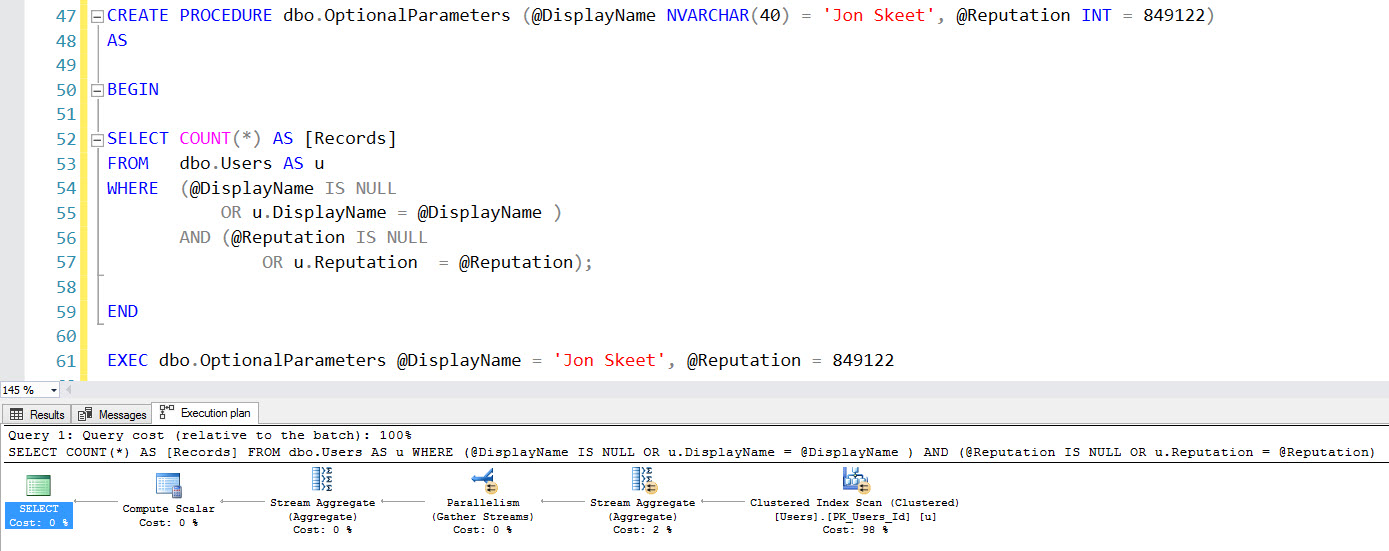
Announcing More Online SQL Server Classes
Our recent class lineup did pretty well, so now we’ve got a new round:
Always On Availability Groups: The Senior DBA’s Field Guide with Edwin Sarmiento – December 20-22, $2,995 – Learn clustering, design, topologies, readable secondaries, monitoring, and troubleshooting.
Expert SSIS Training with Andy Leonard – December 4-5, $1,995 – For SQL Server Integration Services (SSIS) professionals responsible for developing, deploying, and managing data integration at enterprise-scale.
Expert Performance Tuning for SQL Server 2016 & 2017 with Brent Ozar & Erik Darling – November, January, and April – $995 – Your job is making SQL Server go faster, but you haven’t been to a performance tuning class since 2016 came out. Get up to speed in one day. (This is the same class we’re teaching at the PASS Summit with over 300+ folks signed up – but we’ve heard from a ton of folks who can’t make it to Seattle, and wanted us to teach it online, so here you go.)
All of these classes include Instant Replay, the ability to watch the class recordings for one year after your class.
All of these are 50% off right now!
Why? Because we’re going to run a 50% off sale during Black Friday, and we don’t want you buying now, and then doing a giant facepalm when we do the sale. The classes do have a limited number of seats, too, so grab yours now and beat the Black Friday crowd. See you there!