
Creating Basic Indexes on the Stack Overflow Public Database
My public SQL Server database copy of the Stack Overflow data dump only includes clustered indexes by default. I want to keep your database size as small as possible for quick downloading.
But like any database – when you create it, should you add your own indexes to make queries go faster? The answer lies in knowing your workloads, but we don’t usually know our database workloads until they start.
The general generic advice is to start by indexing your foreign key relationships between tables. After all, if tables are related, you’re probably going to join on them by those fields. I like this advice for brand-new databases where we truly don’t know the workloads at all – although I’ll quickly go back and revisit these indexes once they’ve been in production (or even in testing) for a few weeks.
With that in mind, here’s how to index the foreign key type fields in Stack, and here’s a Github Gist for it if you’re into that kind of thing:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
/* Create relational indexes for Stack Overflow */ USE StackOverflow; GO CREATE INDEX IX_UserId ON dbo.Badges(UserId); GO CREATE INDEX IX_PostId ON dbo.Comments(PostId); GO CREATE INDEX IX_UserId ON dbo.Comments(UserId); GO CREATE INDEX IX_PostId ON dbo.PostLinks(PostId); GO CREATE INDEX IX_RelatedPostId ON dbo.PostLinks(RelatedPostId); GO CREATE INDEX IX_LinkTypeId ON dbo.PostLinks(LinkTypeId); GO CREATE INDEX IX_AcceptedAnswerId ON dbo.Posts(AcceptedAnswerId); GO CREATE INDEX IX_LastEditorUserId ON dbo.Posts(LastEditorUserId); GO CREATE INDEX IX_OwnerUserId ON dbo.Posts(OwnerUserId); GO CREATE INDEX IX_ParentId ON dbo.Posts(ParentId); GO CREATE INDEX IX_PostTypeId ON dbo.Posts(PostTypeId); GO CREATE INDEX IX_PostId ON dbo.Votes(PostId); GO CREATE INDEX IX_UserId ON dbo.Votes(UserId); GO CREATE INDEX IX_VoteTypeId ON dbo.Votes(VoteTypeId); GO |
Mind you, these aren’t officially foreign key relationships: the public database doesn’t ship with those. (I don’t have religious feelings about whether you should enforce foreign keys in the database.)
After creating those indexes on the 2017-06 data dump, here’s what sp_BlitzIndex @Mode = 2 has to say:
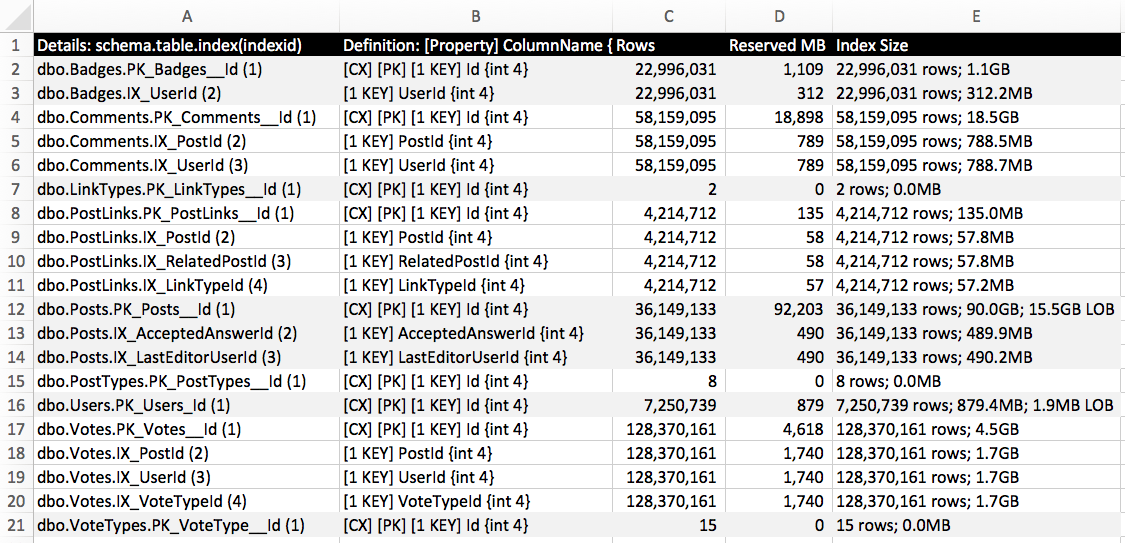
Generally speaking, for OLTP tables, I recommend that folks start with 5 or less indexes per table, with 5 or less fields per index. Even though we’re not even close to hitting that number, you’ll notice that the nonclustered indexes for a couple of tables – PostLinks and Votes – have now grown larger than the size of their original clustered indexes. That’s because these tables are really narrow, and most of their fields define relationships to other tables.
At the other extreme, the Posts table has only 1GB of nonclustered indexes – but 90GB of data on the clustered index. That’s a wide table, with some big ol’ NVARCHAR fields. We might be able to afford several more indexes on that table – depending, of course, on our read/write ratios.
sp_BlitzIndex @Mode = 1 gives us the summary:

In all, we’ve got 115GB of clustered indexes, and 8GB of nonclustered indexes. The far right ratio column refers to size only, not quantity – but either a size or a quantity ratio gives you something to start thinking about when you’re evaluating index levels on an existing database.
