
Home Office Studio Tour
7 Comments
Ever wonder what it takes to do this stuff behind the scenes? I’ll show you.
If you’re thinking about getting started with live streaming or training videos, don’t be intimidated by this setup. There’s a lot of gear involved, but it’s because I’ve been doing this for years, and I’ve accumulated a lot of gear that works well for me. You can start with much less gear!
Let’s start with the big picture:

At left, I use a motorized stand/sit desk from Vari. I usually stand when I’m streaming and working with clients, but after a few hours, I prefer to sit down. When I do, I can just hit a button, and the whole thing comes down (but not the main camera – more on that in a minute.) In the corner of the room, you see the the black stool with just one leg – that’s a Vari Active Seat. I pull that over to the desk when I’m sitting.
At right, I have my “Camera B” setup: a C-stand with another camera, a light, and a laptop. I don’t actually type on that laptop – that’s just my monitor for when I turn to the side to address my audience directly. See, when I live stream, I have multiple camera angles. When I’m chatting with the audience and I don’t need them to see what’s on the stream, I switch scenes so that my camera is full screen, and the audience sees my side office wall:

(The shutters on the right side are closed, but that’s just because I wrote this blog post early in the morning before the sun rose. Once the sun rises, I open those shutters and look out at my neighborhood.)
For the audience, that Camera B view looks like this:

This busy background was a big goal for me when I moved to this house a few years ago. Inspired by video game and tech streamers, I wanted a wall of stuff that would show off my personality. Sometimes I have this camera zoomed in, and other times I zoom it way out to show the whole flair wall.
Anyway, when I’m on Camera B, that laptop mounted right under the camera helps me continue to watch the audience chat live while still facing the camera, plus watch the output from Twitch as a public viewer just to make sure everything’s working okay.
Here’s a zoomed-in view of that Camera B setup:

The gear involved:
- Light: Neewer 660 with softbox diffuser – the diffuser helps soften the light, which helps not only the viewers, but me because I have to stare at it
- Camera: Sony ZV-E1 with Sony FE PZ 16-35mm F4 lens – complete overkill, do not recommend, and requires a SmallRig Peltier cooler just to stay on for live streams. If I had to go back and do this over again, I’d get another Sony ZV-E10 instead, which is more than good enough for live streaming, and doesn’t need a fan. The camera’s live feed goes into my MacBook Pro via an Elgato Cam Link 4K USB capture device. (I run a really long HDMI cable down through that closet and around the room.)
- Laptop: every few years, I buy a Windows laptop in the hopes that I can switch back over from the Mac. I get pissed off, give up, and then I use the laptop for stuff like this.
- C-stand: don’t use a tripod for stuff like this. A C-stand is much sturdier, has a smaller footprint, and can mount more devices like all the stuff you see here.
- Magsafe camera attachment: when I wanna record TikTok comment response videos like this, I just slap my phone onto here and use the light, and my office is in the background. I record those directly in the TikTok app itself.
Now, over to my main desk, which gets a lot more complicated:

The gear:
- Apple MacBook Pro – the current generation of M4 Max with 128GB RAM. It handles live streaming at 60 frames per second, two 4K 60fps camera inputs, multiple displays, 60fps recordings for archival, running a VM, a ton of USB gear, and the CPU fan is never even audible. It’s bananas how fast this thing is, not to mention how battery efficient. I took it on a one-week Alaska cruise recently and didn’t charge it even once.
- Above the MacBookPro, there’s something a little odd: a Logitech Brio 501 mounted sideways on a Manfrotto Magic Arm.
- Main monitor: MSI 32″ 3840×2160 – down under $500 these days, and really good value for money. When I’m streaming, this has a VM or RDP window with what I’m streaming, but I only stream that one app window. Around it, I put things like streaming utilities.
- Teleprompter: Elgato Prompter – when I’m streaming, this shows the live chat. When I’m working with clients, I put the Zoom camera views up there so that it’s more natural – I’m looking directly at the camera, even when they’re talking. The camera is hidden behind that prompter.
- Camera (not visible, inside Elgato Prompter): Sony ZV-E10 with Sigma 16mm f1.4 lens, piped through another Elgato Cam Link 4K – total workhorse. Love this thing. Powered by USB-C, no dummy battery or fan required, runs for hours even at 4K 60fps.
There’s more gear, but let’s stop here for a second and talk about that main camera. The teleprompter and Sony camera are mounted to a C-stand behind my desk because when I type or bang on the desk for emphasis, I don’t want the camera to wobble. Putting the camera on a separate C-stand, not tethered to the desk at all, keeps it more still.
When I’m standing, my main Sony camera is shooting directly at me, with my green wall in the background, so I can use a chroma key filter in OBS to make my background disappear, and let me float over what I’m streaming:

However, after a few hours of standing while working, I wanna sit down, so I push a button on the motorized Vari desk and it drops to a sitting position. But because the Sony camera is mounted to that separate C-stand, it’s still up high. That means I need another camera.
If you look closely at the desk screenshots, above my MacBook Pro, you’ll see something goofy: a Logitech Brio webcam turned sideways, mounted to the desk via a Manfrotto Magic Arm. It’s turned sideways because I want the max resolution possible (given that it’s a crappy webcam) and I use it in the stream like this:
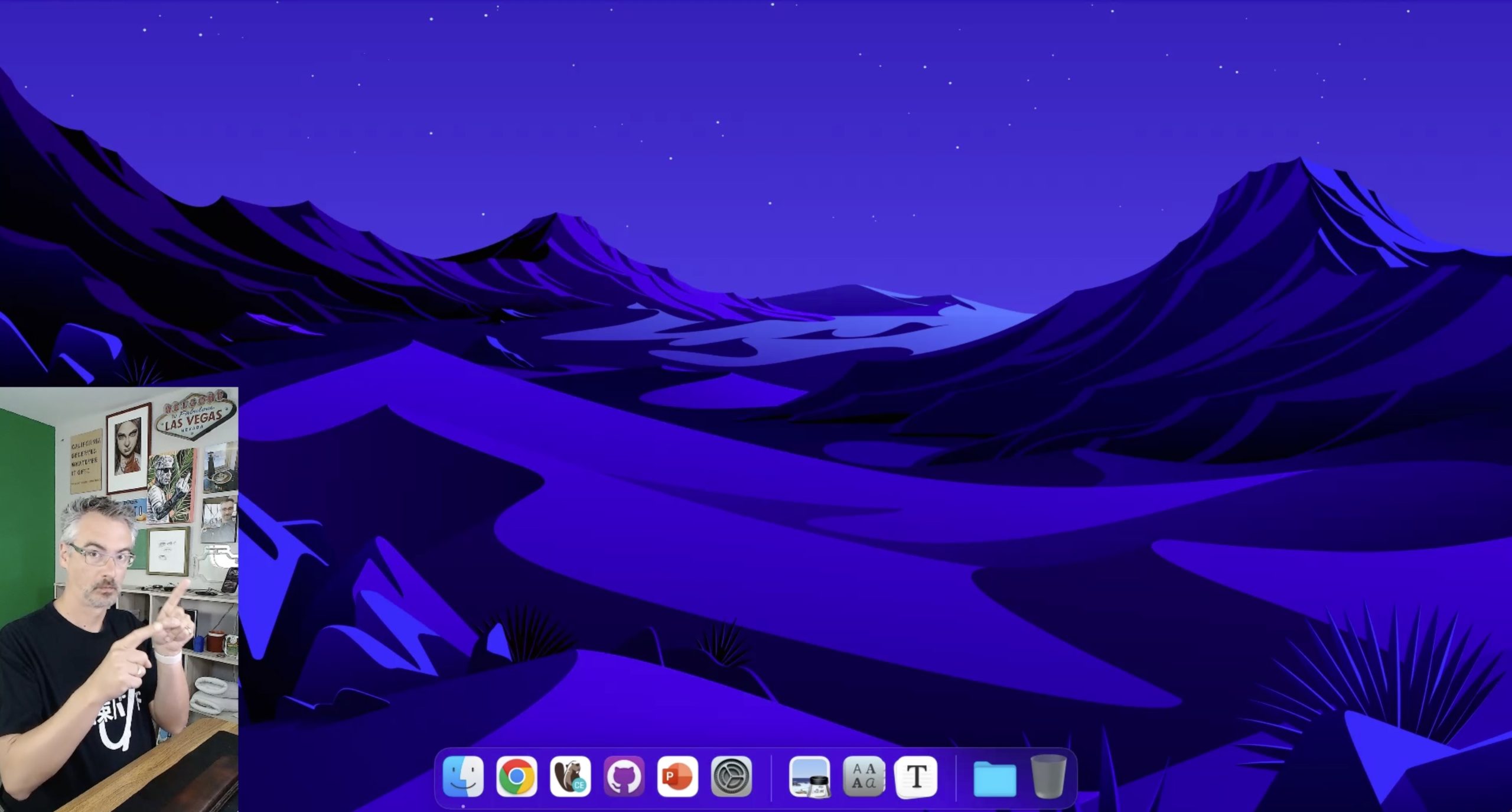
This view isn’t green-screened. This will probably be the next thing I upgrade in my home studio gear – switching to a different sitting camera, mounted to the C-stand, so that I’ve got nice green screen views whether I’m sitting or standing.
Back to the gear on the desk:
- Lights: Neewer 192 soft lights – mounted on desk platforms from the old Elgato Key Light Air, so that they also work when the desk is in sitting position.
- Control panel: Elgato Stream Deck XL – because I have a lot of sound effects and scenes.
- Microphone (not shown): DPA directional headset plugged into a Sennheiser AVX wireless system, piped into a Focusrite Scarlett 2i2 – because I wanna move around a lot between different scenes, and walk around on the green screen demonstrating stuff, without the audio changing. Every now and then, some commenter gives me flak for using an “old” microphone, and I just shake my head and laugh. When I’m working with clients, I use a much simpler wired USB Plantronics monaural headset.
- Connectivity: Sonnet Echo 20 Thunderbolt 4 SuperDock – I have tried so many docks, and this one has been the only one that’s stayed solid without randomly dropping SSD connections under really heavy load. (When I say heavy load, remember, I’m running Ethernet, multiple SSDs, USB video & audio feeds, the Stream Deck, and more.)
- Input: Apple Magic Keyboard and Trackpad on a heated desk mat. Yes, it does get cold in Vegas during the winter.
For software, the big key is OBS Studio. It’s free, open source, frequently updated, and ridiculously powerful, but has an ugly learning curve. I still need to spend time learning how the latest features work, like simultaneous landscape & portrait video outputs (for streaming to both Twitch/YouTube and TikTok/Instagram simultaneously.) Hell, I even need to learn how the basic features work, like better audio settings and chroma key filters.
It’s a lot of gear, and a lot of work, but you can see the quality of the results in my training classes and live streams. See you there!

 This month, I’m teaching two of my classes live, online, completely free!
This month, I’m teaching two of my classes live, online, completely free!
 Plus, while you’re at the conference, the idea of this year’s event is to be really involved in the after-hours events at the venue itself. I’ll be at all of ’em this year.
Plus, while you’re at the conference, the idea of this year’s event is to be really involved in the after-hours events at the venue itself. I’ll be at all of ’em this year.
 The
The 



 However, sometimes when I’m looking at the output of sp_BlitzCache, I scroll across to the Average Rows column and double-check that the query’s actually returning a reasonable number of rows out in the wild.
However, sometimes when I’m looking at the output of sp_BlitzCache, I scroll across to the Average Rows column and double-check that the query’s actually returning a reasonable number of rows out in the wild.


