SQL ConstantCare® Population Report: Winter 2026
12 Comments
It’s time for our quarterly update of our SQL ConstantCare® population report, showing how quickly (or slowly) folks adopt new versions of SQL Server. In short, people are replacing SQL Server 2016 and 2017 with 2022!
- SQL Server 2025: 0% (but it’s 10 servers)
- SQL Server 2022: 29%, up from 25% last quarter
- SQL Server 2019: 43%, no change
- SQL Server 2017: 9%, was 10%
- SQL Server 2016: 10%, was 13%
- SQL Server 2014 & prior: 6%, no change
- Azure SQL DB and Managed Instances: 2%, no change
So, is SQL Server 2022 looking better after all, like it’s going to take the throne from 2019? To understand, let’s jump back to 2023, when I wrote:
SQL Server 2017 is now the version that time forgot: folks are just skipping past that version, standardizing their new builds on 2019 rather than 2017. There wasn’t anything wrong with 2017, per se, but it just came out too quickly after 2016. These days, if you’re going to do a new build, I can’t think of a good reason to use 2017.
SQL Server 2017’s adoption rate had peaked at 24% in 2020, about 3 years after its release. Today, it’s 3 years after 2022’s release, and SQL Server 2022’s adoption rate looks like it’s still climbing – but it has a new competitor, 2025. I’m guessing we’ll see one more adoption rate bump for 2022, and then it’ll start falling again as 2017 did, unable to defeat the powerhouse that is SQL Server 2019.
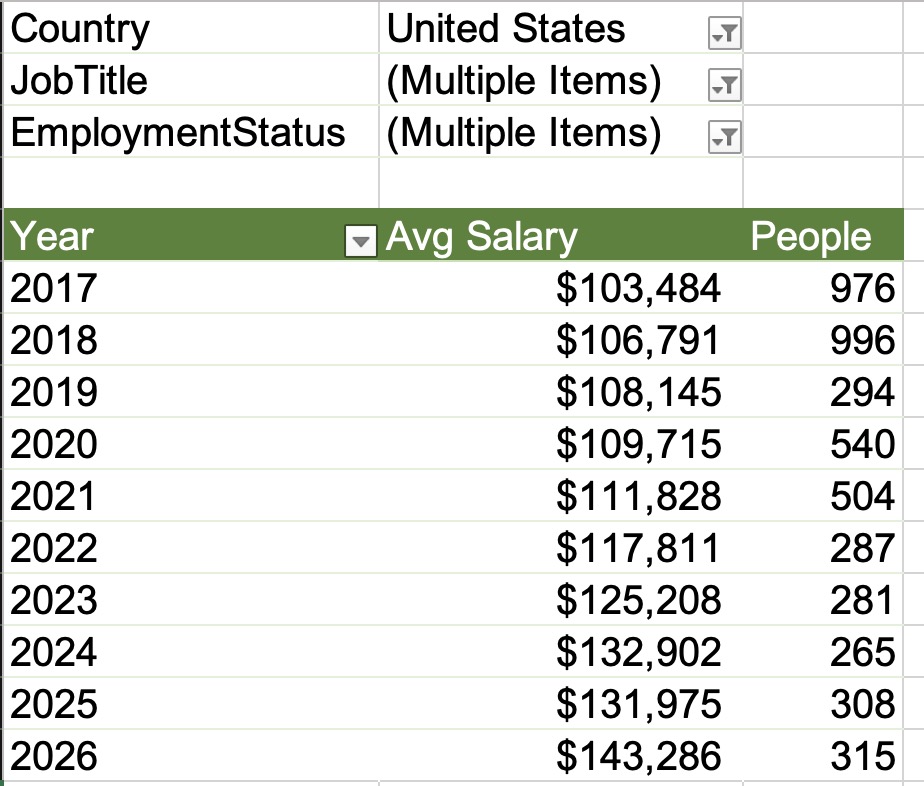
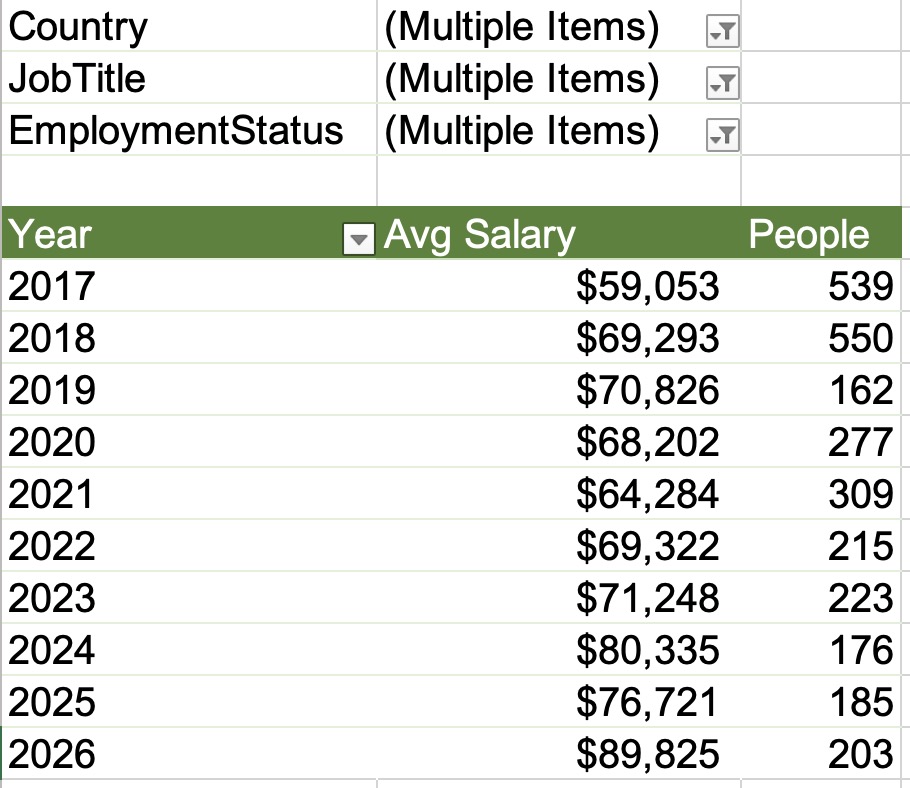
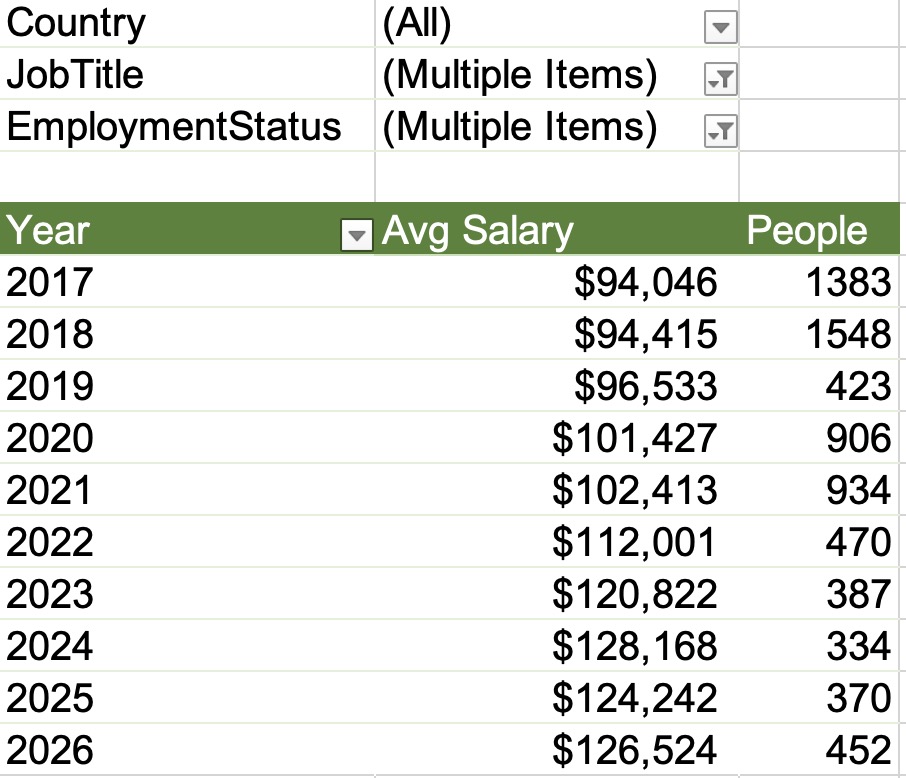
I’ve grouped together 2014 & prior versions because they’re all unsupported, and 2016 will join them quickly in July when it goes out of extended support. (I can’t believe it’s been almost 10 years already!) Here’s how adoption is trending over time, with the most recent data at the right: 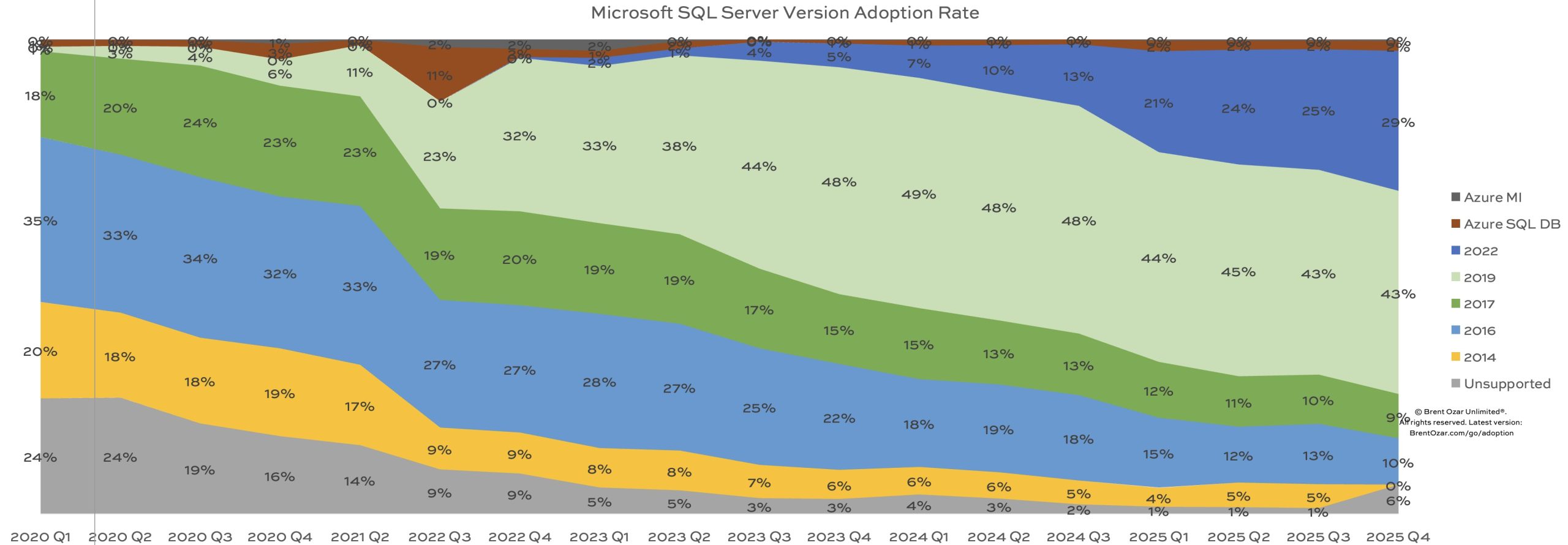
The new stuff continues its steady push from the top down, driving down the old versions out of support.



 It’s a really slippery slope, and it goes downhill fast.
It’s a really slippery slope, and it goes downhill fast.