Announcing Free MASTERING Week 2025!
7 Comments
You’ve been working with SQL Server, Azure SQL DB, or Amazon RDS SQL Server for years.
You’re jaded. You’re confident. You’re pretty sure you know what you’re doing.

You’ve never taken my Mastering classes because you’ve read the blog, watched the live streams, and figured you’ve pieced it all together. You can’t imagine there’s anything left to learn — no surprises left in the box.
Well, now’s your chance to find out, for free.
From November 11-14, I’m running a brand-new special event: Mastering Week, four half-day classes, totally free to attend live.
- Tuesday: Mastering Index Tuning
- Wednesday: Mastering Query Tuning
- Thursday: Mastering Parameter Sniffing
- Friday: Mastering Server Tuning
Register here to grab your seat and download the calendar invites before your coworkers try to book you into yet another “quick sync.” At showtime, head to the live stream link in the invite — that’s where the magic happens.
Can’t make it live? The recordings won’t be on YouTube or free later. You’ll need my Recorded Class Season Pass: Mastering, which includes all four full-length classes — available for one-year or lifetime access.
In just four hours, you’ll know whether you’ve really mastered Microsoft databases… or if there are still a few tricks this old dog can teach you.
Let’s hang out and talk data. Bring your curiosity (and maybe your ego!)

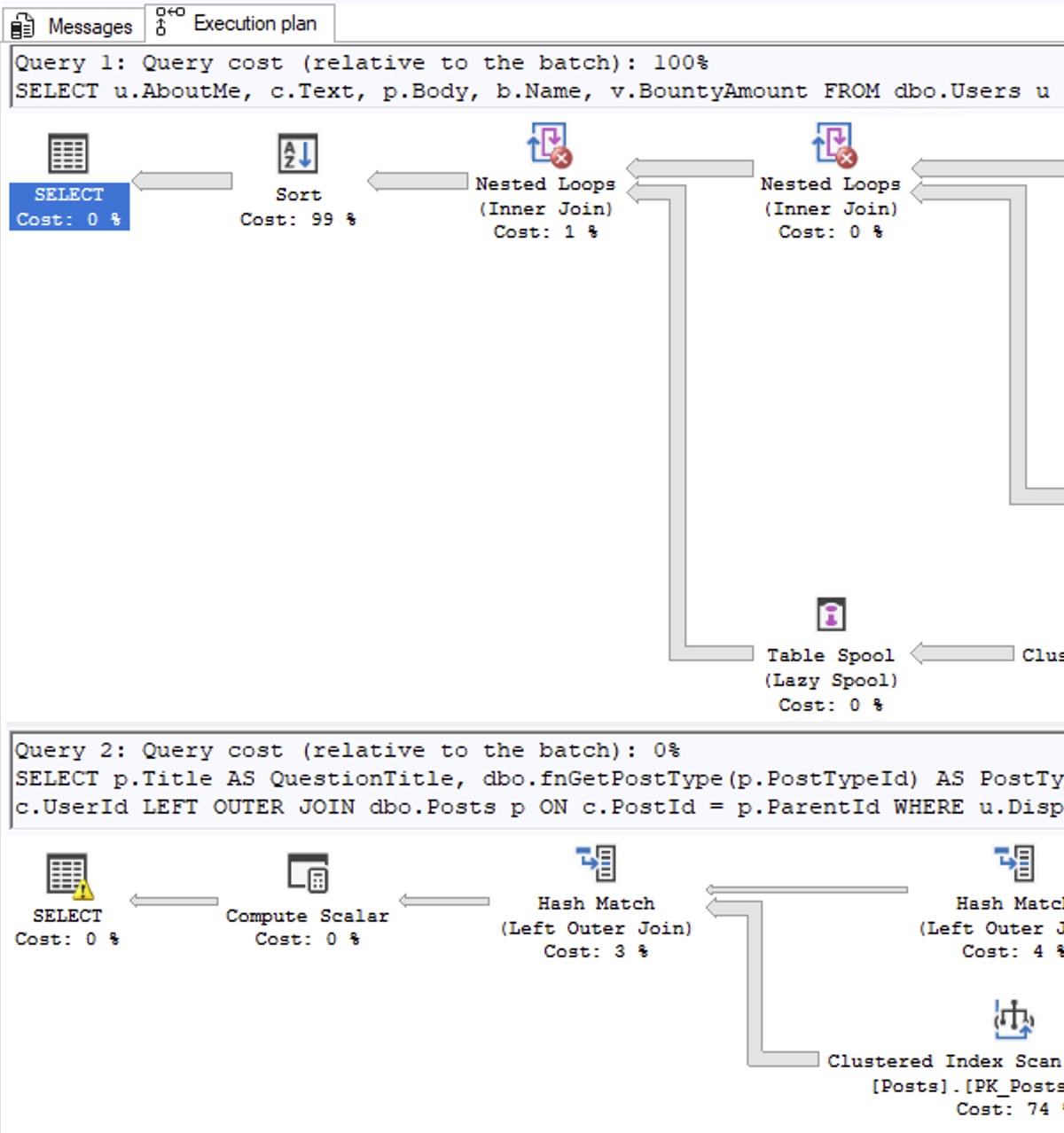
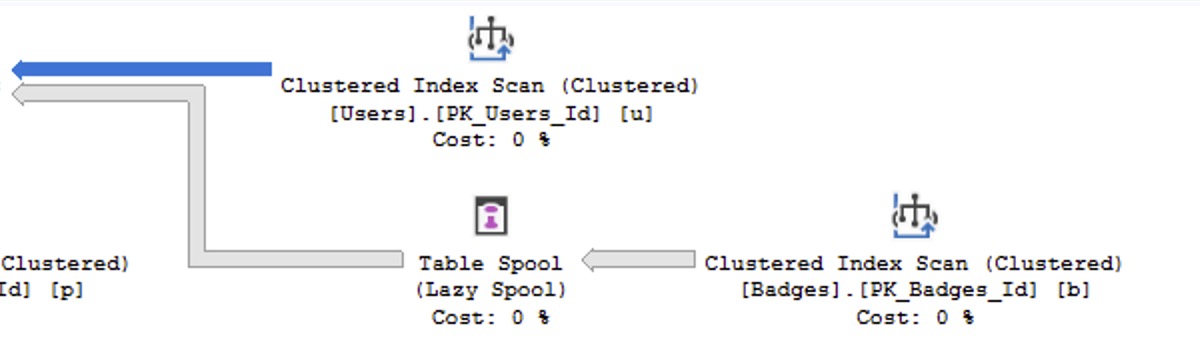
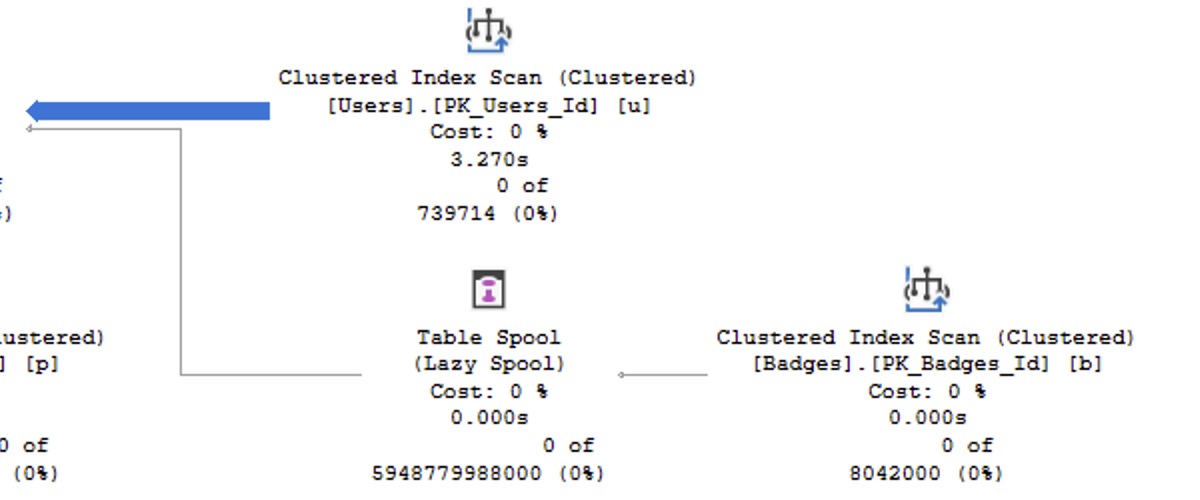








 I’m teaching my two most important classes live, online, completely free!
I’m teaching my two most important classes live, online, completely free!