SQLBits Attendees: Here Are Your Prerequisites for Mastering Index Tuning.
6 Comments
![]() Howdy folks. It’s time for SQLBits!
Howdy folks. It’s time for SQLBits!
This year, I’m teaching a one-day Mastering Index Tuning workshop from 9AM-5PM London time, and you can join in online. Pricing is £300 for the one-day workshop, or £800 for a full conference pass. You can register here.
Once you’re registered, here’s what you need to do:
- Watch my 75-minute How to Think Like the Engine video
- Set up a SQL Server 2016 or newer instance – a laptop with 4 cores and 16GB RAM is fine, but just make sure you’ve got an SSD, not an ol’ rusty frisbee
- Get the Stack Overflow 2013 database – 10GB direct download, or torrent or magnet – expands to a ~50GB database
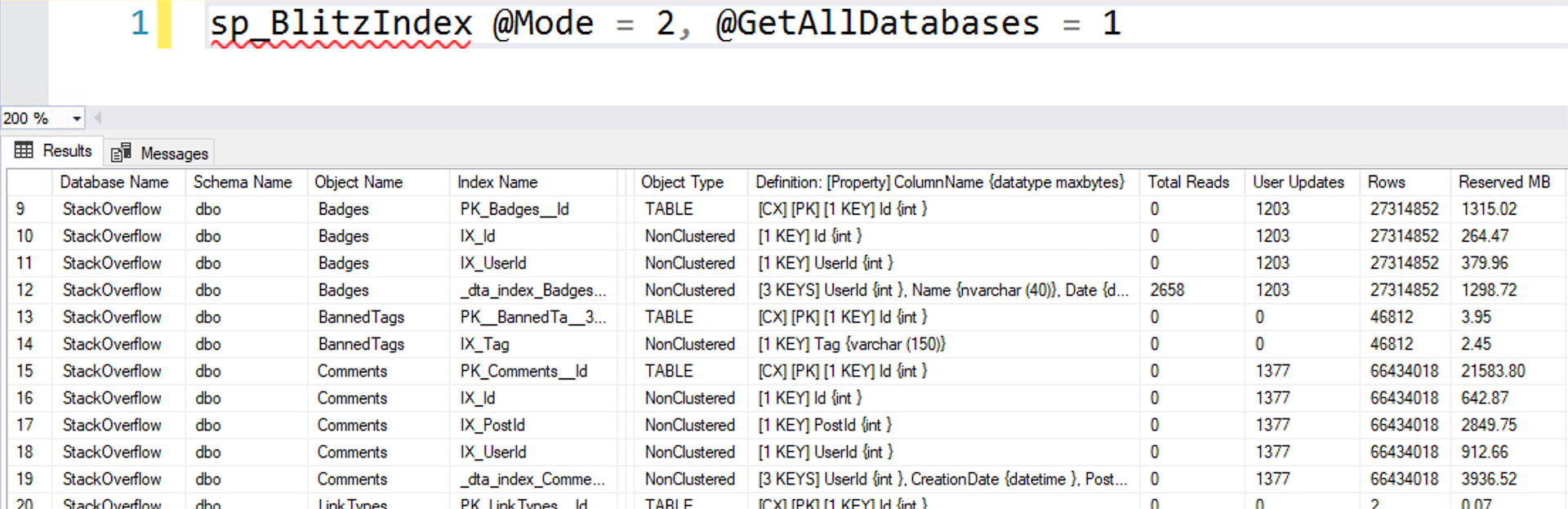
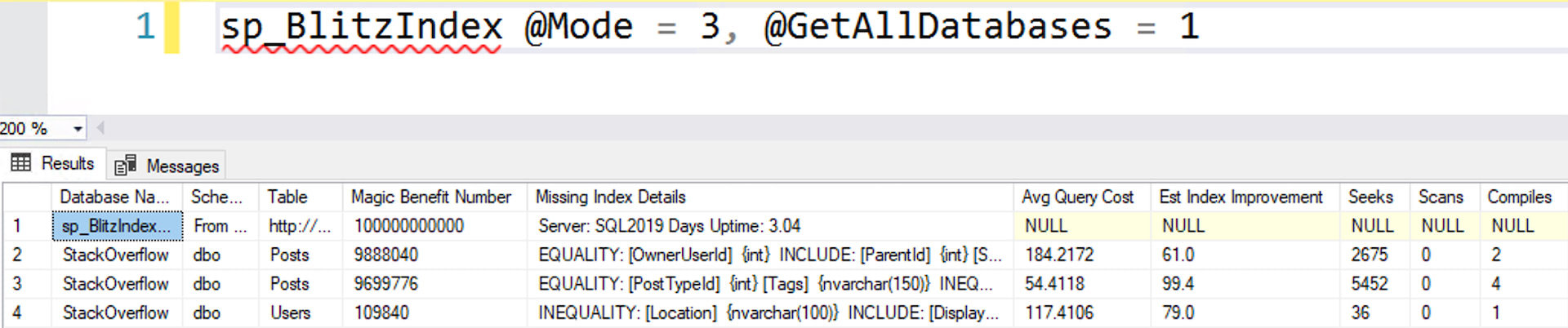
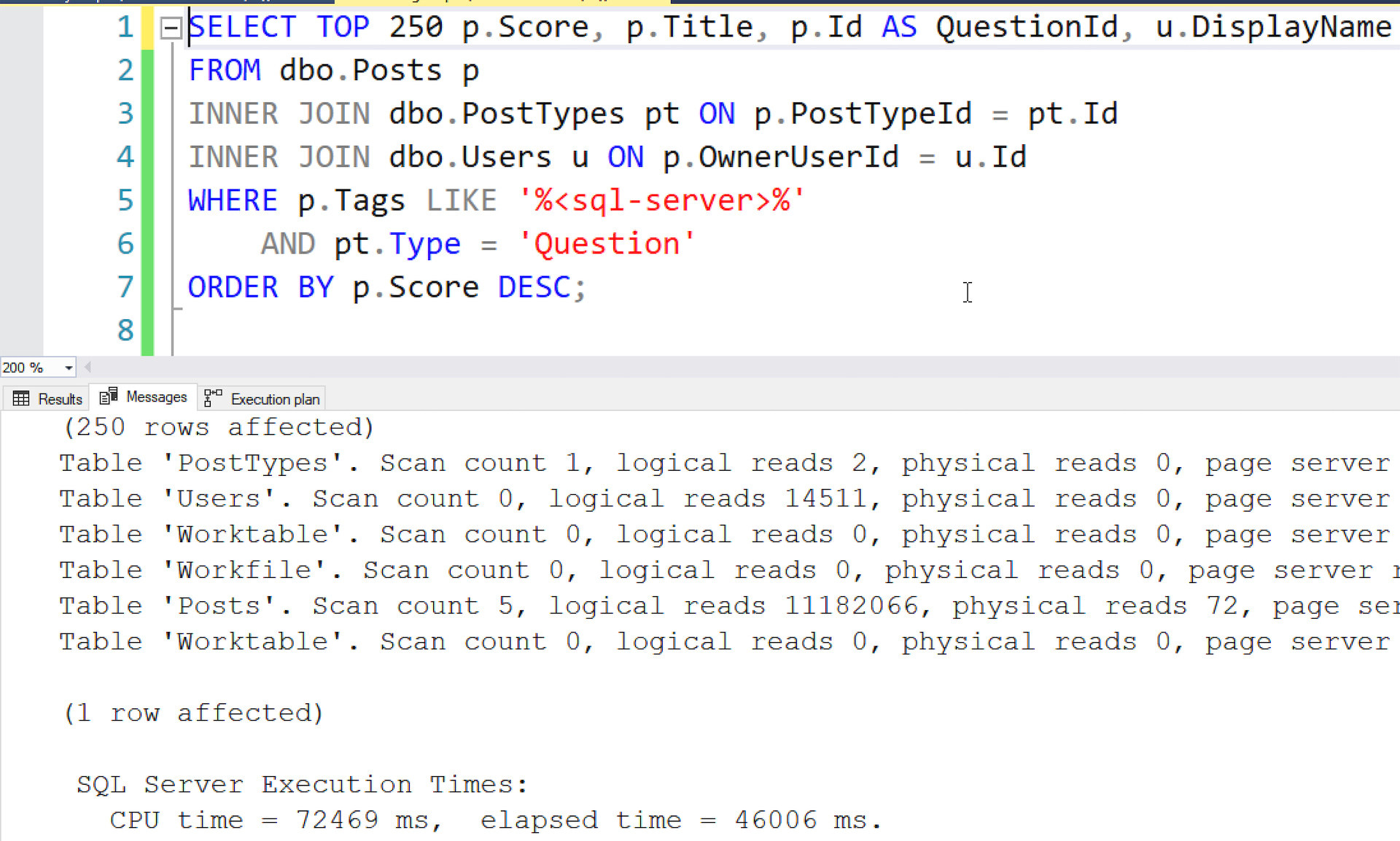
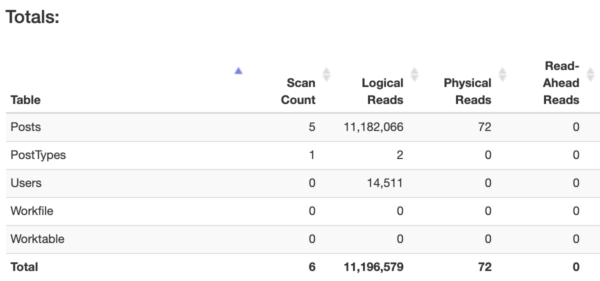
- Watch my Fundamentals of Index Tuning class instant replays, and follow along with the hands-on labs
What’s that, you say? You can’t buy my Fundamentals class because you’re in the EU, and we have that whole pesky GDPR problem? Okay, here’s what we’ll do: I’ve opened that class up for free until SQLBits. Go watch now, no registration required.
See you in the workshop!
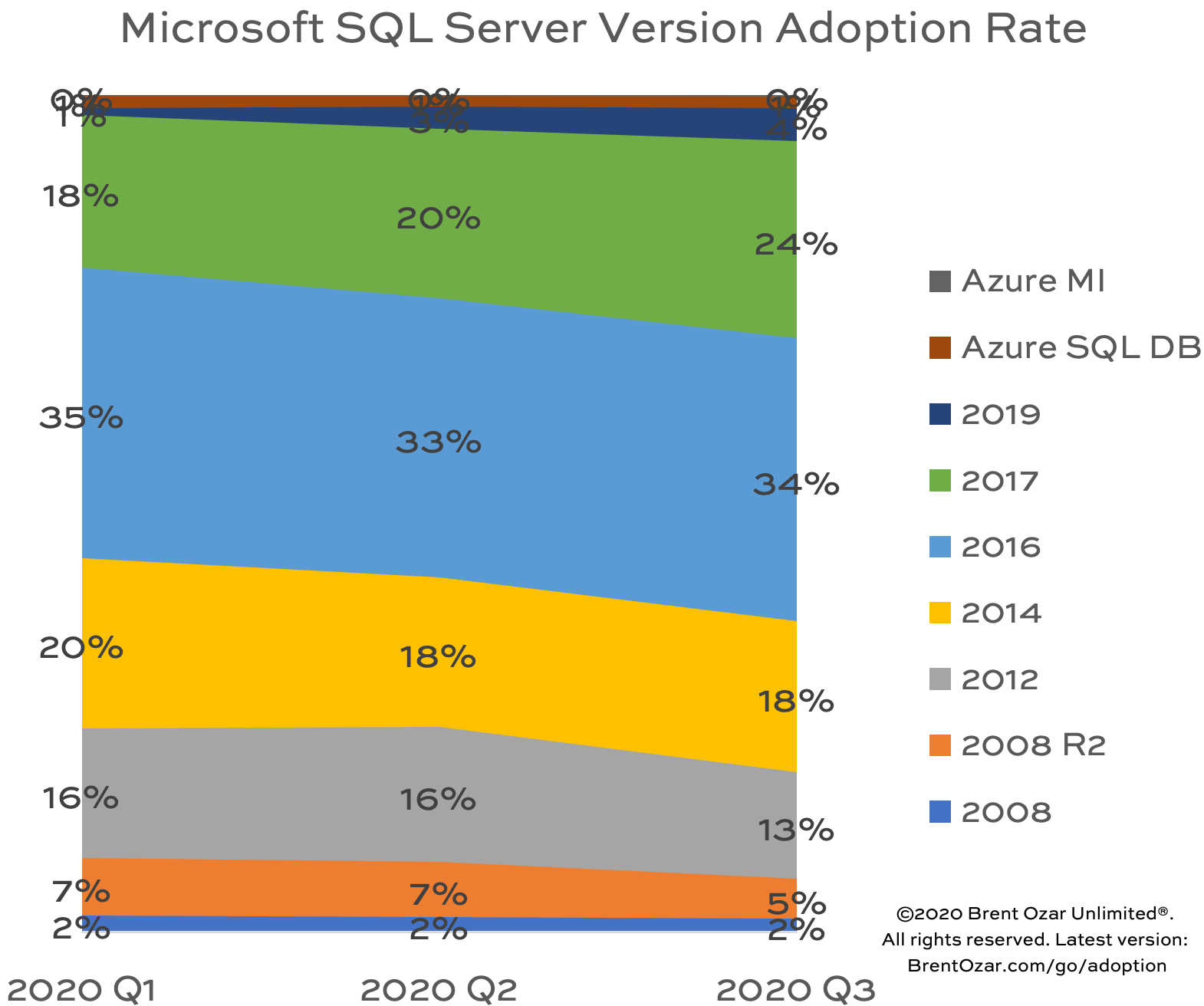







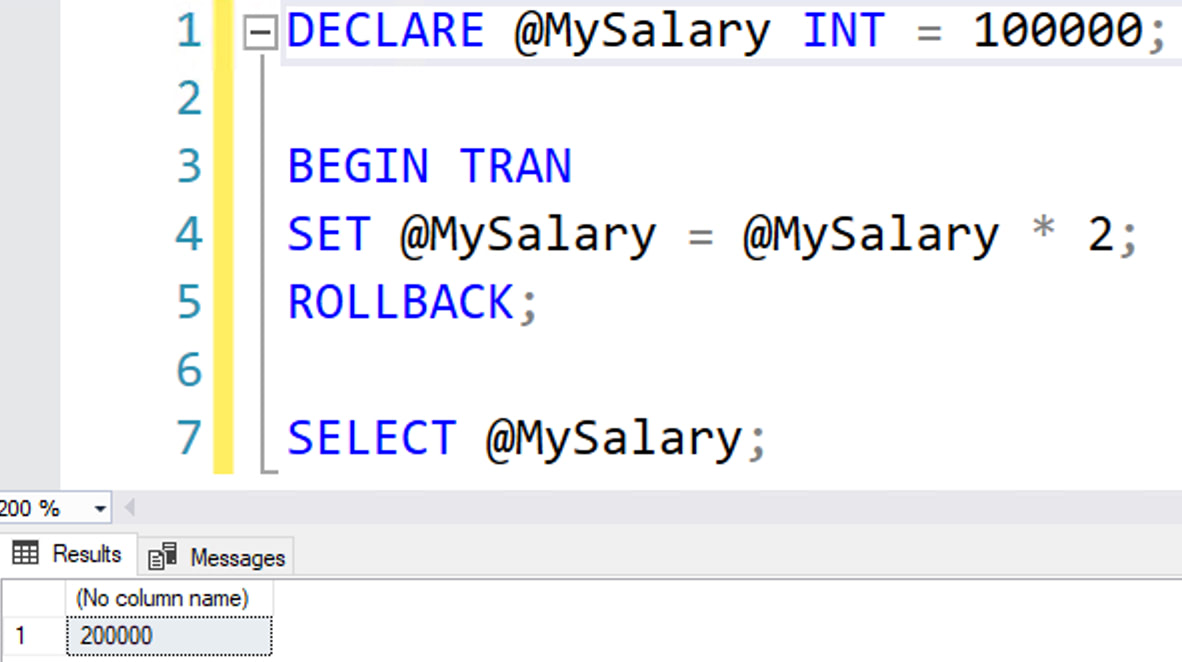

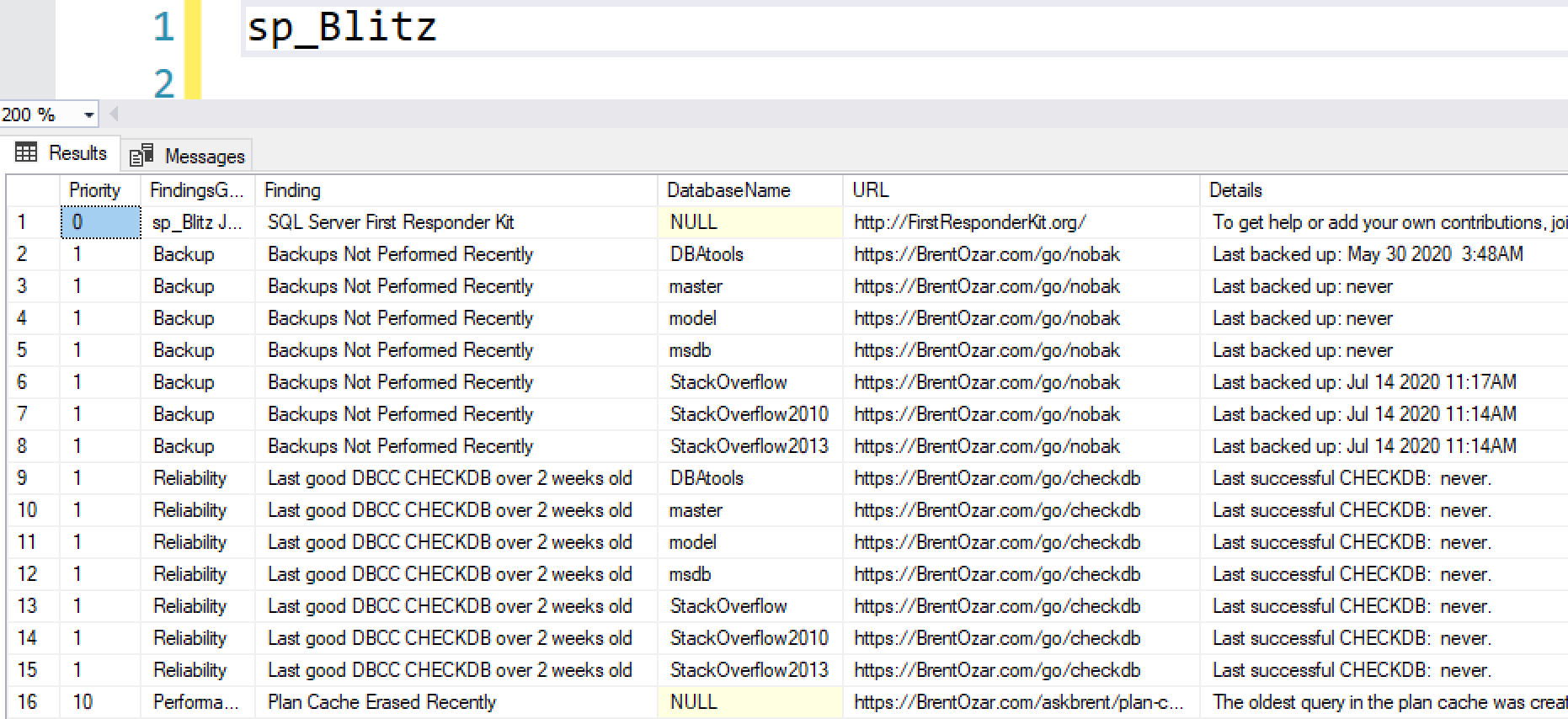

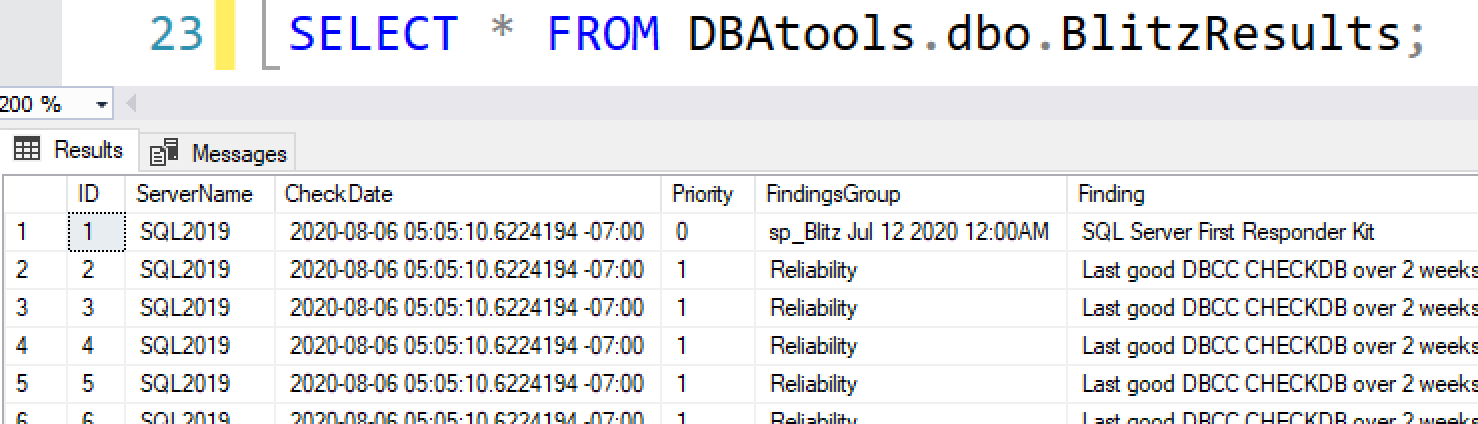



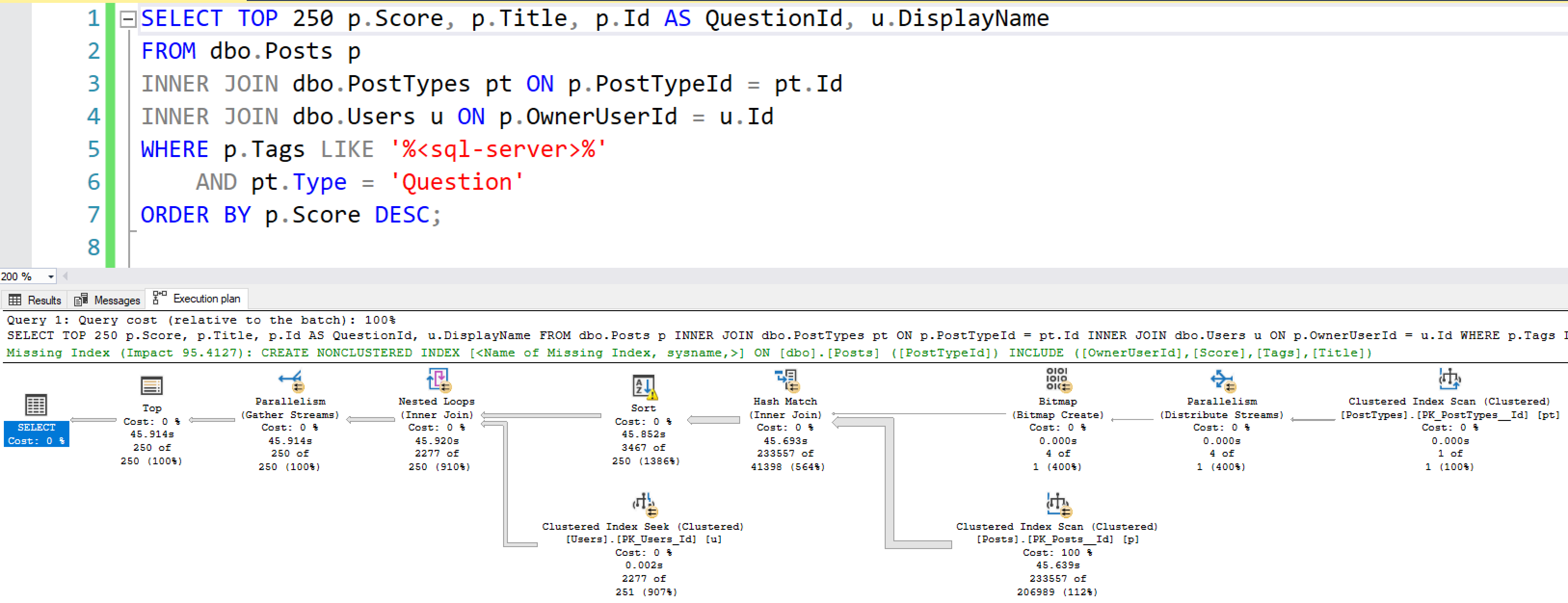

 You need to speed up a SQL Server app, but you only want to make index changes. You don’t want to buy hardware, change SQL Server, or change the code. I’ll teach you the most important advanced lessons in one day.
You need to speed up a SQL Server app, but you only want to make index changes. You don’t want to buy hardware, change SQL Server, or change the code. I’ll teach you the most important advanced lessons in one day.