
Change Your #SQLPASS Password Right Now.
13 Comments
What you need to do: log into SQLpass.org and change your password. If you use the same password anywhere else, change it on all of those sites immediately as well.
Why you need to do it: anytime you ever logged into SQLpass.org or SQLsaturday.com, or updated your password, or created an account, your password (along with everything else) went unencrypted between your computer and PASS’s web servers. Anyone sniffing network packets along the way saw your username, email, password, etc in clear text. (Think about what a security gold mine this would have been for someone sniffing WiFi at a SQLSaturday or the PASS Summit.) There’s a nice side benefit for updating your account – you also become eligible to vote in the current PASS elections.
Who you need to thank: the vulnerability was discovered by George Stocker on Friday, and PASS HQ finished the fixes & testing on Saturday. That’s a fantastic turnaround time – kudos to PASS for reacting so fast!
Who you should blame: yourself, for not noticing for years that you were putting login information into a web site that wasn’t using https. What kind of data professional are you, anyway? You’re probably even using that same password on multiple web sites, or heaven forbid, your company email. Get it together and use 1Password or LastPass.
Who you should not blame: the current PASS Board of Directors because this has likely been in place ever since PASS set up their current web site, and the current management inherited this little surprise. (You know how it goes – it’s like your ancient SQL Server 2000 in the corner where everybody knows the SA password.)
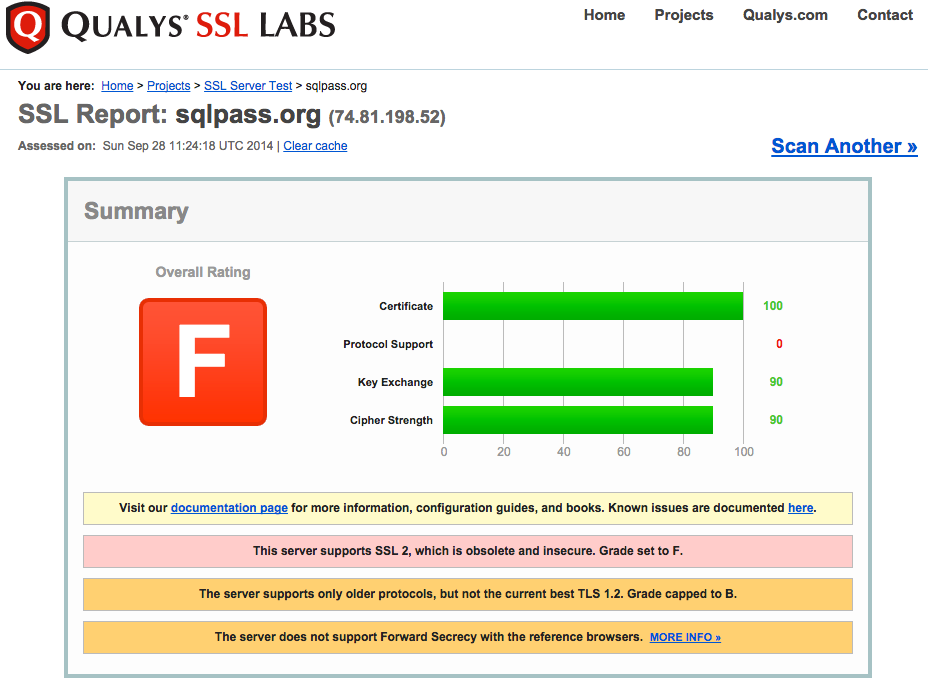
What’s still left to do: PASS needs to clearly, concisely communicate the severity of this issue to members as well – I really wish they’d set all passwords in the database to null, and force everybody to go through the password-reset process. The SSL setup still needs some work, as shown in the SSL tests, but considering the whole thing was done in 24 hours, it’s one heck of a good first step. (SQLsaturday.com also fails that test.)
Where to go for more information: logged-in PASS members can ask PASS public questions in their blog post comments, email info@sqlpass.org privately, or ask questions here in the comments.


 Funnily enough, I’ve heard the exact same thing from developers who are facing a tough problem on a dramatically undersized SQL Server. The basic gist of what they ask is:
Funnily enough, I’ve heard the exact same thing from developers who are facing a tough problem on a dramatically undersized SQL Server. The basic gist of what they ask is:








































{kind=link}