Office Hours Speed Round: Text Edition
10 Comments
Not all of the questions you post at https://pollgab.com/room/brento are hard. Some of ’em can be answered in one line:
Q: accidentalDBA: Hi Brent, My friend is moving from two physical servers (production + failover) to VMs on the same host and SAN. His manager wants to keep log shipping as a DR solution. I advised against this as most disasters would affect both VMs equally. Am I missing something?
If both your servers are in the same physical location, you don’t have disaster recovery. You just have disaster.
Q: Efraim: When refactoring a clustered index for a multi-terabyte table, is it recommended to take the db out of full recovery and put it into simple recovery mode first? Concerned about maxing out the transaction log during the refactoring.
Will the business allow you to lose point-in-time recovery while this operation is happening? If no, then no.
Q: Doug E: Is Azure Data Studio ready for SSMS users to make the switch? If not, what functionality needs to be added to Azure Data Studio?
Why do you need to make the switch? Your answer to that question will determine whether Azure Data Studio has what you need in order to switch.
Q: Pramod A: On one of the servers, BPE is enabled and the SQL max memory is set to 4x the physical RAM. Does this make sense ? Are there any best practices for SQL max memory configuration when BPE is enabled specifically ?
I haven’t seen a good use case for BPE. Read this. I’m sure there *is* one somewhere, I just haven’t seen it.
Q: SaveTonight: You always say that once we move to the cloud we cannot move back to on-prem. Azure doesn’t let you manage your backups, but there must be a way to go back to on-prem from Azure SQL Database. Azure/AWS cannot steal your data, that would be a law infringement, right?
They didn’t steal it. You gave it to them.
Q: AlwaysLearningDBA: Hello Brent, a friend of mine : ) has been asked to implement TDE on two node AlwaysOn with Replication. He is starting with Failover Cluster with Replication for now.He knows that you don’t work with Replication.Google didn’t help much.Do you recommend any resources about this?
You’re asking me for good learning resources for things that you know I don’t use? Okay, uh, sure, try this. That video is everything I know about 2-node AGs with TDE and replication.
Q: Jack McCoy: Which job provides more satisfaction / income, development DBA vs production DBA?
For me, development DBA because I’m not on call, and I can provide a high value in a short period of time. Production DBA work is more grueling, involves a lot of on-call and weekend time, and isn’t as financially rewarding because you’re seen as the cost of doing business to keep the plumbing flowing.
Q: Anthony DiNozzo: What percentage of work time should DBA’s commit to continuing technical education?
Learning the right stuff pays off in higher future earnings. How much more would you like to earn in the future, as opposed to today? Figure out what you want to earn, and then learn what it would take to earn that. If your goals are minor and incremental, your current employer might sponsor it. If your goals are major and involve leaving your current employer, well, you’re gonna have to figure it the %$&* out.
Q: Joe Friday: Is clustered index fragmentation any more / less detrimental to query performance than non clustered index fragmentation?
Q: Pramod A: A table has 80 statistics ( Index + system ) on table row count of 160 million. To improve the performance of the query, if I have to pick few stats specifically and update those stats with full scan, how would I know which stats to pick in order to expect a performance gain ?
The ones the query is using for its cardinality estimation decision. We cover how to do that in my Fundamentals of Query Tuning and Mastering Query Tuning classes.
Q: Omer: Did DBA Brent have a outlook rule / folder strategy for classifying / triaging the various SQL errors encountered on a daily basis during their career? If so, what strategy was used?
As soon as you start putting alert emails into a folder, you’re screwed. You’re not looking at those folders. Go change the alert thresholds so you only get actionable emails you’d want to have in your inbox.
Q: Ned B: Is there any harm / benefit in using SQL page compression if the SAN is also compressing the data?
Compressed pages can help you can store more in memory and get faster throughput to storage since less 8KB pages go across the wire.
Q: DBAInHiding: If you’ve been employed as a staff employee for various companies over the years but feel your next gig as a DBA or developer will require you to be a 1099 contractor, what’s the essential checklist to prepare for such a move and what gotchas should you be on the lookout for?
I don’t have an easy answer for that one. I’d pick up a book on how to start freelancing.
Q: Anul: What is the ideal cluster and sector size for new SAN drives hosting SQL data files and transaction log files?
Ask your storage vendor.
Q: Kurt Wagner: What are the monitoring hurdles / challenges when moving bare metal SQL from onprem to Azure SQL? Do we throw away our current SQL monitoring software?
Not all of the same monitoring data is available, and when it’s available, it has to be captured in different ways.
Q: Hello Brent, my friend need some help to understand apply, cross apply and outer apply operator. He understand joining table and function using those, but not joining 2 table using cross or outer apply. Probably he is missing some basic understanding.
Pick up this book.
Q: Andrew: Hi Brent, On daily basis we keep our data on a SAN storage, so does the SQL servers, not so long ago we made a SQL RAS, and i asked the Microsoft Premier Field Enginer about the virtual disk separation for the SQL data files. What do you think about it?
What’s the problem you’re trying to solve?
Q: Raphra: Hi Brent, I thought I knew how a recursive CTE works until I saw the execution plan of a recursive CTE (that was to return the last 100 calendar years) and I saw a Nested Loops (inner join). Can you explain what a Nested Loop operator is doing there?
Not without seeing the plan, but I’m not sure why you think nested loops are bad. They can make perfect sense for some operations.
Q: Hany: Hello Brent, what is the best Azure video learning resources out there?
Q: Bob: Why is an Int primary key on a date dimension recommended instead of a date? All tables that link to the dim keep their native type and can use built in date functions. This can also avoid joining the Date dim for simple queries.
Ask whoever recommended that to you.
Q: Quartz: Why does CAST(‘2022-06-13’ AS DATETIME) fail for SET LANGUAGE british but work for SET LANGUAGE us_english?
I didn’t know British was a language.
Q: DBABA (database administrator by accident): What are good alternatives to dacpac deployments? (Not having to write manual migration scripts but defining the target state of the database)
Check out Redgate Schema Compare.
Q: I Inherited It: I have a server that has a 14TB Data Warehouse database on it. For a couple of days each month, it get’s hammered, often by very poorly written queries and performance suffers. It never recovers, even when the traffic backs back down, performance remains bad until reboot. Why?
Analyze its wait stats like we talk about in Mastering Server Tuning.
Q: YourbiggestFan: Hi Brent, If you are asked to trbshoot perf issues on az paas database, how would you go abt finding the main bottleneck. Would you use sp_blitzfirst(log to table) or use query store to get reliable wait stats info or via any other way? (Account for DB scale down during offhours)
I’d log wait stats to table.
Q: SteveB: In a recent office hours you said the best way to upgrade an AG was with a Distributed AG. Is there a reason you would not add the new servers to the current AG and just failover to them? We done this and it worked great but I might have just gotten lucky.
Yeah, whenever I have new servers in an AG, I prefer testing their failover processes, doing cluster validation, etc before go-live, and that’s really dangerous when you have an existing AG.
Q: Yabba DB Doo: We have a web app in Azure that has individual databases for each of our customers. What’s the best way to manage DB changes during development and then deploy them out to multiple production databases?
See above.
Q: MikeO: My vendor friend is using sp_prepexec. When passing the query with the recompile option the plan shows using an index seek. When passing the same query without the recompile option the plans shows using an index scan. Is this a parameter sniffing issue or a quirk with sp_prepexec
I can’t tell without seeing the queries and plans.
Q: mr_Arturo: hi Brent, a friend of mine (: recently changed the job and “he” (: noticed that the new company use lots of views, but even stranger is that some of views are request data from other views! What about performance and should it be avoided request the view data of the view data?
Q: Ozymandias: Is there a DB size where native SQL backup / restore becomes a concern?
Generally by the time you hit a terabyte, full restore times are tough.
Q: mukesh chaurasia: Dear i am new in sql administrator so i want to know about which book is best to guide about sql administrator real time problem.
Q: Daniyyel: Is it ok to run perfmon directly on the SQL server?
Q: Konstantin: How does Jorriss combat oxidative stress?
He’s made of carbon fiber, not metal.
Q: Odafin: Any noteworthy columnstore improvements in SQL2022?
Q: Jethro: Is the OPTION Label hint ever helpful?
I’ve never used it.
Q: Experto no en la materia: What is the largest number of active databases you have seen hosted by a single SQL instance?
10-12,000.
Q: Arslan: When troubleshooting a SQL agent job step failure, is it better to “Include step output in history” or to output job step results to an Output file?
Which one is easier for you to parse when it’s a big long output? There’s your answer.
Q: David: Who is the “Brent Ozar” of the SSIS world?
Q: SqlPadawan: Hi Brent! A part from grabbing parameters and good/bad plans (as you teach in MPS), how have you used Query Store during your 2-day emergency rescue? Any other practical uses in terms of performance tuning?
Not during my 2-day SQL Critical Care, no, but if I had a full time DBA job again, I’d use it.
Q: Dev on the Dark Side: What are the top 10 (or even 5) things that you can “teach” a development team to do / not do in regards to a mix of stored procs, entity framework, & CF ad hoc queries. So many problems… so little time…
If your developers can only learn 5-10 things, they’re doomed.
Q: Kunoichi: Hi Brent! My question is related to CDC : Why does MS SQL Server allows ONLY TWO capture instances on any given table at a given time?
For “why”, ask Microsoft.
Q: Steve E: Hi Brent, All of our SQL Servers are currently on premise but I feel I should gain some awareness of cloud services such as Azure Managed Instances or Azure SQL Databases. Is there a way I can do this as a personal user? Most of the plans seem to be 00’s of (British) pounds p/m
Read articles or watch videos rather than running your own server.
Q: Eric Beaumont: My friend read a blog that write once file shares are good at stopping potential ransomware from infecting sql backups. Have you ever implemented at write once file share for sql backups? What all is involved?
The DBA shouldn’t be the one implementing it. The sysadmin team should be. This kind of thing is usable across all servers, not just the database servers.
Q: DBA by addiction: What kind of malware / virus protection can or should be installed on a SQL-Server? Can you give some advice if things around this topic are pretty much senseless?
Whatever your security team requires.
Q: Have you used SQL Server with docker? If so, please elaborate.
Yes, in an early attempt to do SQL Server development on my Mac. It was a huge pain in the rear. I hated it. I can see why people would use it for continuous integration, but it’s not for me, especially with the new Apple Silicon processors.
Q: Hi Brent! A CLR function uses a temporary table. I don’t want to use forced parameterization at the database level at this time. In this case, how to deal with the bloated plan cache?
I’m not a fan of using CLR in SQL Server for a whole bunch of reasons, but if you insist on using it, then I’ll assume you can solve the problems you run into.
Q: Emelio: Does page level compression affect backup performance or size?
Q: Fyodor: Do you have a File Group strategy you recommend when creating new SQL databases?
If it’s going to be 1TB or larger within 30 days, create a new filegroup with 4 files spread across 4 volumes, and make that the default filegroup.
Q: Does Basically Anything: Hi Brent, I’m having issues with the T-log not freeing space after log backups and growing a lot. There are no runaway queries, but there are 200+ sleeping SPIDs with is_implicit_transaction = 1. Are they the likely culprit? What troubleshooting path do you recommend? It’s ISV.
Q: Kinneret: What is your opinion of SQL 2022 Buffer Pool Parallel Scan feature? Who will this benefit the most?
I haven’t looked into it at all, but the Microsoft post on it implies that it focuses on people with a lot of memory, say 512GB and above.
Q: Jayden: What are top gotcha’s you see when using implicit transactions in TSQL and C#?
Q: Biz: Is there a good way to view cache hit / cache miss ratios for when SQL has to load data from slow disk vs fast memory?
By going back in a time machine to 1999 when that was how we did performance tuning. Today, use wait stats instead.
Q: Bart: Have you consulted on Microsoft Dynamics AX (2012) database query/index optimizations?
Yes.
Q: Lincoln: What bad things can happen when data warehouse and OLTP mixed workloads are run against the same SQL 2019 enterprise instance?
Slow performance.
Q: RoJo: We have Dev, Stage, Prod environments. Sometimes the config (for example) points to the Dev from Stage or worse. To isolate them from each other, I’m thinking white listing inside Windows Firewall. Is this too slow, or any best practice to keep collateral damage from near servers
I don’t think I even understand this question. It’s probably too big of a scope to ask for Office Hours – try dba.stackexchange.com.
Q: Henrique Almeida: Hi Brent, how are you, I hope so. Which free SSMS add-ins do you recommend and if not, why?
You hope so what? What the hell does that even mean?
I don’t use any because I can’t usually install apps on the client machines I work with. I’m sure there are good ones out there, but I just don’t have experience on what they’d be.
Q: Raphra: I like notebooks in Azure Data Studios and I can see how we can add comments to stored proc, by replacing the stored proc’s text with a notebook file (with markdowns for comments). However, do you know how I can call this notebook from SQL Agent instead of the stored proc?
I adore notebooks too. I wouldn’t use them as scheduled jobs though.
Q: Maani: Hi Brent! how come select from a view executed by ‘sp_executesql’ is much slower than executing it as a query (it took 4 mins to be executed)?I wrote option(recompile) at the end of the select clause from view, and the request was executed in less than a second.(was no parameter)
I would need to see the query and the execution plans to answer that.
Q: Neil: i have a job that uses OLE Automation to pull some json stuff. can i enable and disable OLE automation at the beginning and end of the job to prevent anyone else from using it ?
No, it’s completely impossible to enable and disable OLE automation, as shown by this link.


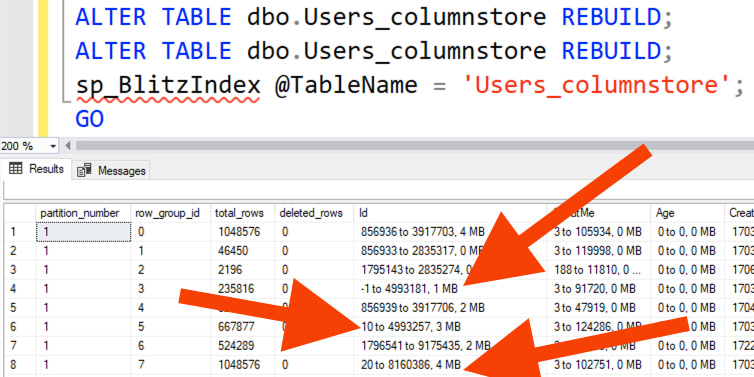

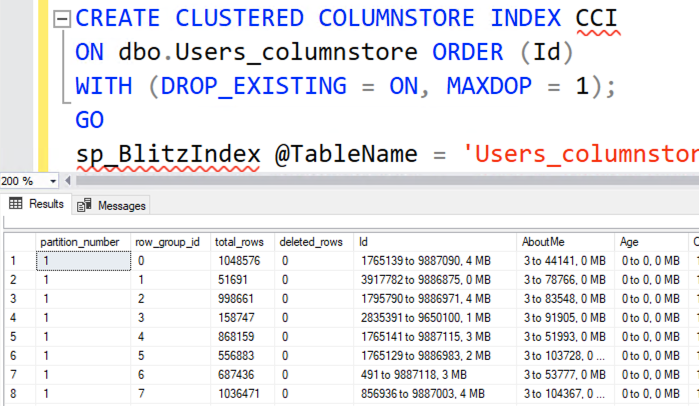







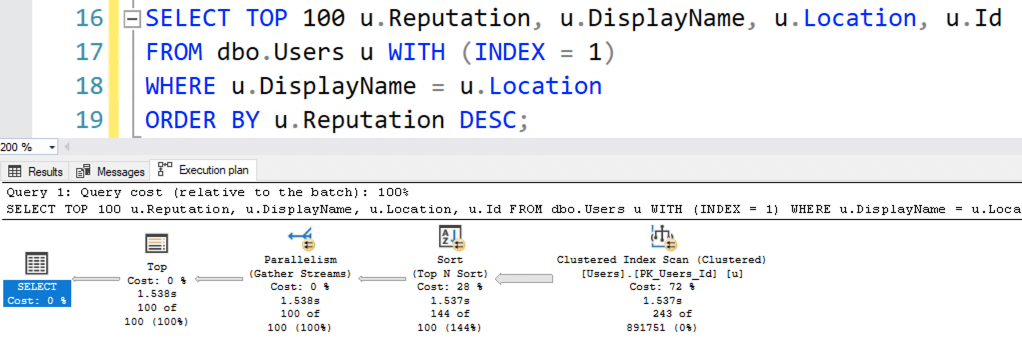
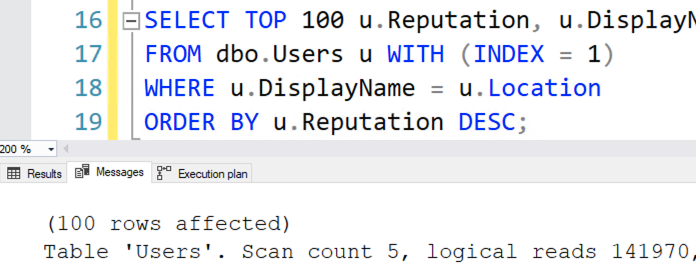

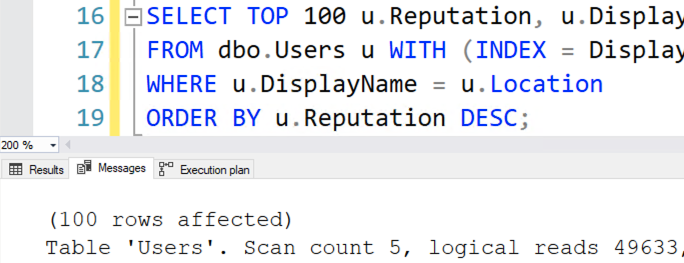


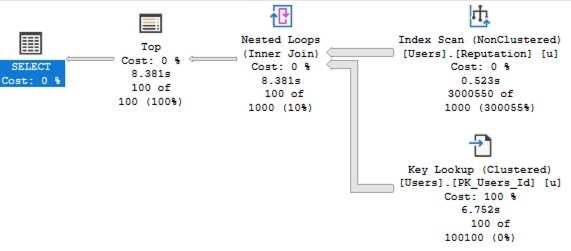



 So here it comes, Eric.
So here it comes, Eric.