[Video] Consulting Lines
2 Comments
In my consulting work, I often find myself saying the same things to clients – but they’re not the kinds of things I said when I was a database administrator. I call these “Consulting Lines”, and I talked through ’em:
Here’s my full series of Consulting Lines blog posts:
“Yes, that used to be a best practice, and…” – When someone’s been doing something remarkably bad, don’t pull their pants down in front of the group. Here’s how to focus on moving forward with a new way.
“Would you mind driving?” – If someone’s micromanaging you and telling you to do something you don’t agree with, here’s how to call their bluff gracefully.
“SQL Server needs a dog.” – If you’re dealing with someone who keeps bashing buttons that they don’t understand, here’s how to get them to leave all the switches alone.
“I’d be a bad consultant if I didn’t put that in writing.” – When you see something that scares the pants off you, cover your butt.
“Write this down, because I’m not going to.” The flip side of the previous line: this wins people over on to your side when the finding isn’t all that bad.
“What problem are we trying to solve?” – If someone’s trying to play Trivial Pursuit to test your knowledge, or won’t let go of a really minute technical detail, here’s how to get them to step back and look at the big picture.
“Sounds like you’ve got it under control.” – When someone keeps arguing with you about your proposed solution, saying it won’t work, here’s how to get them to open up to new ideas.
“What happens if that doesn’t work?” – When someone’s about to break production or cause irreparable damage, here’s how to get them to think about Plan B.
“Keep going. What else?” – Some people really need to get their story out before they can talk about the technical problem. Let them.
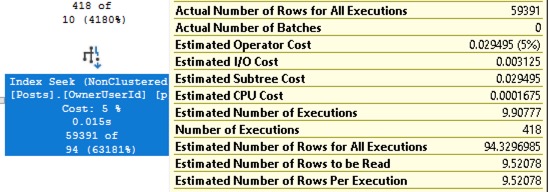
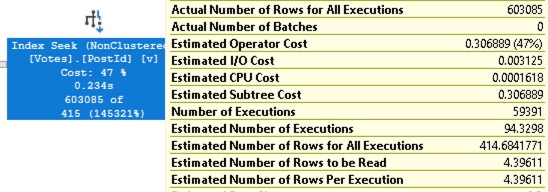
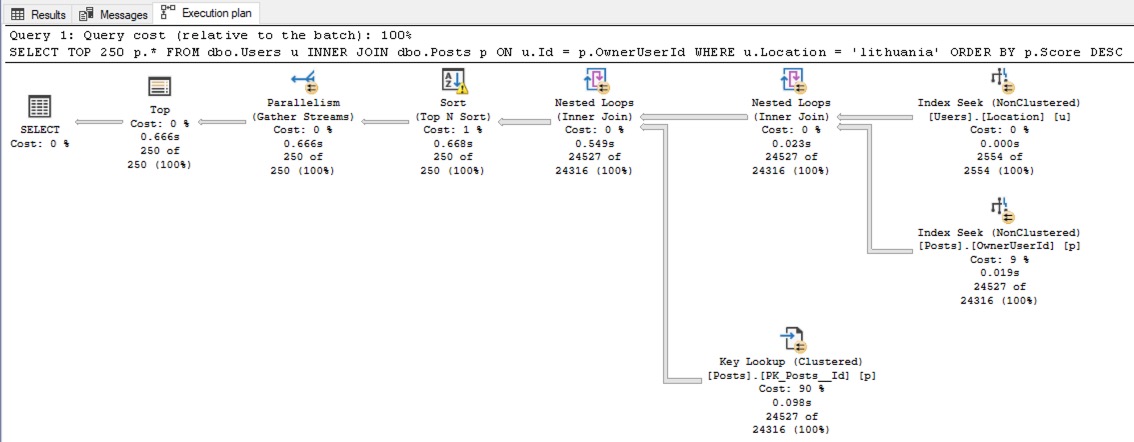
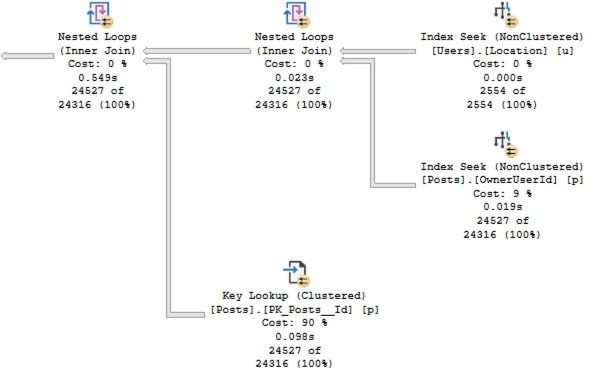
“Do you want 10% faster, 100%, or 1000%?” – When you start performance tuning, make sure everyone’s on the same page about how long it’ll take and how much work will be involved.
“Let’s put that in the parking lot.” – When you’re in the midst of troubleshooting something important or trying to finish a meeting, set aside a separate area for off-topic requests.
“I have a hard stop at…” – Consulting involves a lot of meetings, and not all meeting organizers respect your time. This line helps you get out of unproductive meetings gracefully.

 If your company is hiring, leave a comment. The rules:
If your company is hiring, leave a comment. The rules: