Index Hints: Helpful or Harmful?
25 Comments
Let me ask you a question: do you want to boss the SQL Server query optimizer around?
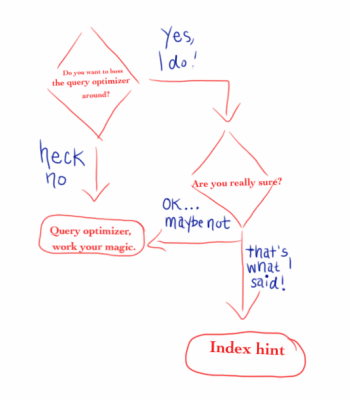
If you answered no: good. You’re willing to let the query optimizer do its job, which is to find the least expensive way to run a query, as quickly as possible.
If you answered yes: you’re a brave person.
Maybe you’ve hit upon the perfect index for a specific query, but for some reason the optimizer won’t use it. But you know it improves performance. How can you make the query optimizer listen to you?
Index hints are a powerful, yet potentially dangerous, feature of SQL Server.
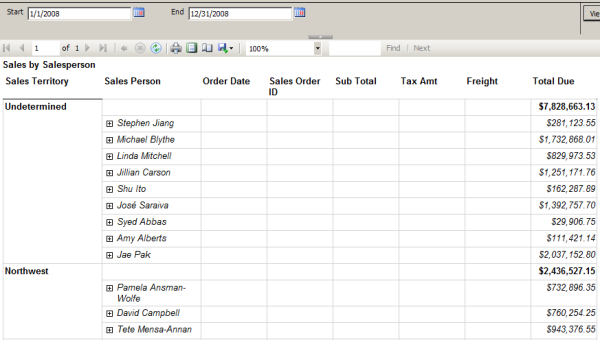
Let’s look at an example. I’m working with AdventureWorks2012. The database has two related tables, HumanResources.Employee and Person.Person. They are related through the BusinessEntityID column. I want to retrieve information about the users and their logins.
|
1 2 3 4 5 |
SELECT PER.FirstName, PER.LastName, EMP.LoginID FROM HumanResources.Employee EMP INNER JOIN Person.Person PER ON PER.BusinessEntityID = EMP.BusinessEntityID; |
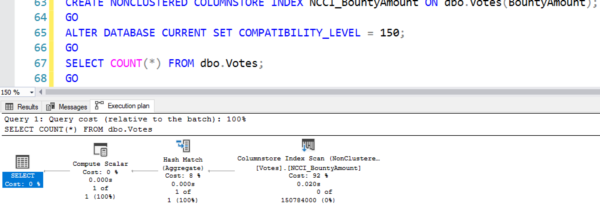
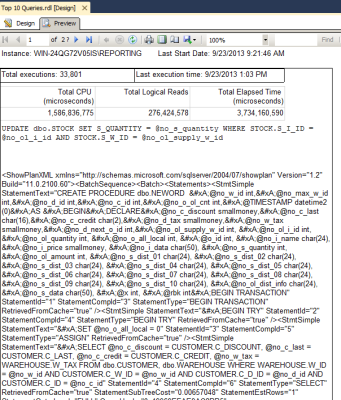
Let’s look at the execution plan.

A nonclustered index seek is performed on Employee.AK_Employee_LoginID, a nonclustered index on the LoginID column. A clustered index seek is performed on Person. Note the cost is 0.217439.
I notice that the Employee table has another index, PK_Employee_BusinessEntityID, which is on the BusinessEntityID column. I want to force my query to use this index instead. I can do this by using the WITH (INDEX) hint.
|
1 2 3 4 5 |
SELECT PER.FirstName, PER.LastName, EMP.LoginID FROM HumanResources.Employee EMP WITH (INDEX (PK_Employee_BusinessEntityID)) INNER JOIN Person.Person PER ON PER.BusinessEntityID = EMP.BusinessEntityID; |
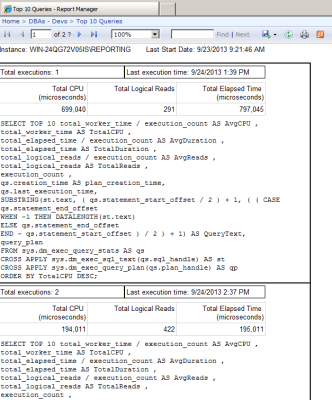
Let’s look at this execution plan.
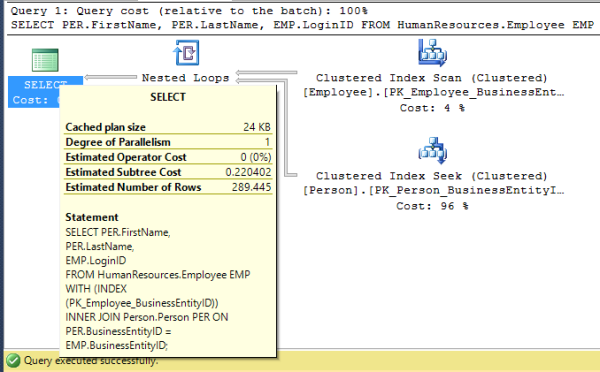
Now, a clustered index scan is performed on Employee. Note, though, that the query cost has increased – to 0.220402.
In your case, the index you force the query to use might get the better cost – for now. But what happens when more data is added to the table, and statistics change? What happens if you update SQL Server, and the query optimizer changes?
Eventually, the index you’re using may not be the best one for the job – but SQL Server is going to continue to use it anyway. You’ve told it to do so, and it’s doing to keep doing it.
Think about how you would get rid of it. Is there an easy way to search all of your code – application code, stored procedures, report definitions – for this specific index hint, to remove it?
Another point to consider is what would happen to that code if the index was disabled or deleted? Would it continue to run? Let’s give it a try. I issue a disable index command.
|
1 |
ALTER INDEX PK_Employee_BusinessEntityID ON HumanResources.Employee DISABLE; |
Then I run the same query as before, and what happens? I get an error:
Msg 315, Level 16, State 1, Line 1
Index “PK_Employee_BusinessEntityID” on table “HumanResources.Employee” (specified in the FROM clause) is disabled or resides in a filegroup which is not online.
Index hints can be a powerful feature, but use with caution. Look for other ways to optimize your query – perhaps a different index can be created, or your query can be rewritten. If you can’t find a better way, document the use of the index hint and its purpose. When you upgrade SQL Server, test whether that index is as effective.
Remember, the query optimizer does its job really well – let it.













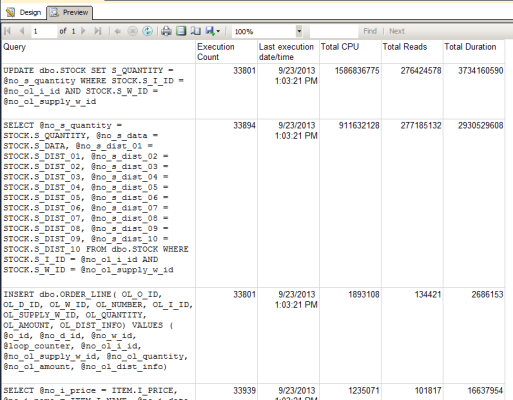
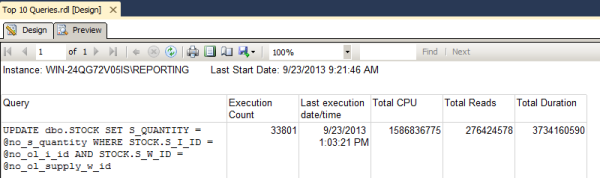

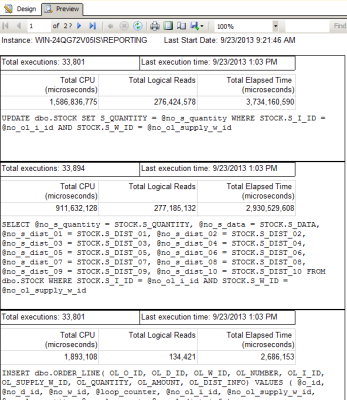









 Chances are that if there was a disaster and your HA solution kicked in right now, you’d experience the same terrible performance on the other server, too – with the added pain of having downtime to failover.
Chances are that if there was a disaster and your HA solution kicked in right now, you’d experience the same terrible performance on the other server, too – with the added pain of having downtime to failover.