
The Two Ways to Fix Non-Sargable Queries
In the database world, when we say something isn’t sargable, what we mean is that SQL Server is having a tough time with your Search ARGuments.
What a sargable query looks like
In a perfect world, when you search for something, SQL Server can do an index seek to jump directly to the data you want, then read only the rows you want, and nothing more. As an example, say we’ve got an index on DisplayName, and we look for users with a specific display name:
|
1 2 3 4 |
CREATE INDEX IX_DisplayName ON dbo.Users(DisplayName); GO SELECT * FROM dbo.Users WHERE DisplayName = N'Brent Ozar'; GO |
Then our execution plan shows a nice, tidy index seek with one row read and one row actually produced:

What a non-sargable query looks like
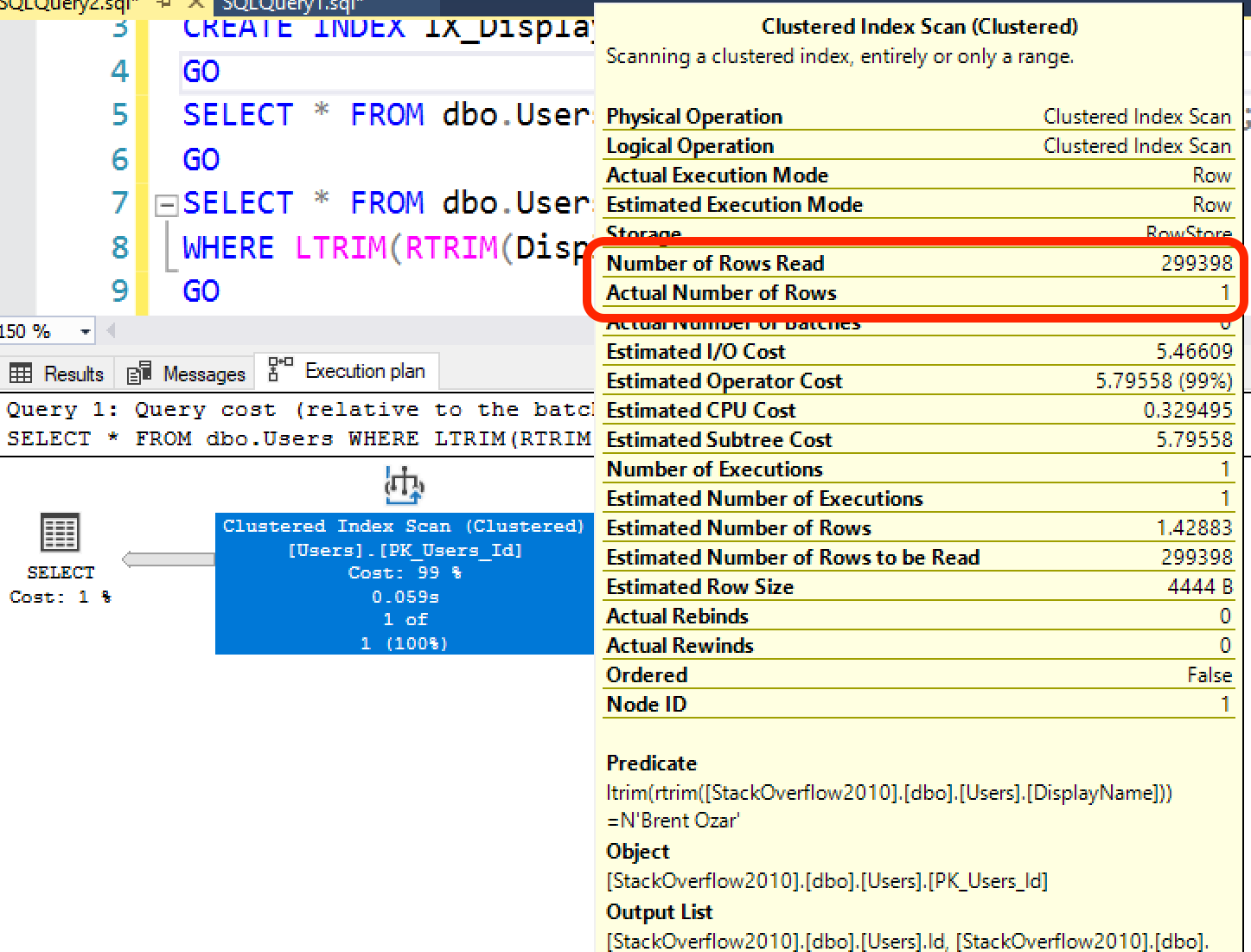
Say I don’t trust the data in my database, and I ask SQL Server to strip off the leading & trailing spaces:
|
1 2 |
SELECT * FROM dbo.Users WHERE LTRIM(RTRIM(DisplayName)) = N'Brent Ozar'; |
Now, my execution plan looks a lot worse: I’m reading a lot more rows than I’m actually producing.
The two ways to fix it
If you want to read less data, you can either:
- Change the query to make it sargable, or
- Pre-bake data on disk to match what you’re looking for
Changing the simple query in this case is pretty easy: we’d just remove the LTRIM/RTRIM. (I’ll talk about more complex situations at the end of the post.)
Pre-baking the data on disk can be as simple as adding a computed column, and then indexing it:
|
1 2 3 4 5 6 |
ALTER TABLE dbo.Users ADD DisplayNameTrimmed AS LTRIM(RTRIM(DisplayName)); CREATE INDEX IX_DisplayNameTrimmed ON dbo.Users(DisplayNameTrimmed); GO SELECT * FROM dbo.Users WHERE LTRIM(RTRIM(DisplayName)) = N'Brent Ozar'; |
Now my execution plan is awesome again, reading just one row and producing one row:

My favorite part is that we didn’t even have to edit the query! The query still refers to LTRIM(RTRIM(DisplayName)). That good ol’ SQL Server looks at the query and says, “Ah, they’re looking for LTRIM/RTRIM DisplayName, and it just so happens I’ve already pre-baked that data on disk!” He uses the index on the trimmed column even though we didn’t ask for it.
My least favorite part is what happens if I flip the order of LTRIM/RTRIM, or if I use the new TRIM command:
|
1 2 3 4 5 6 |
SELECT * FROM dbo.Users WHERE RTRIM(LTRIM(DisplayName)) = N'Brent Ozar'; GO SELECT * FROM dbo.Users WHERE TRIM(DisplayName) = N'Brent Ozar'; GO |
SQL Server’s all, “Whoa, I’ve never seen functions like that in a WHERE clause, and I don’t have any of that data pre-baked,” so he ends up scanning the table again:

So if my users were regularly running non-sargable queries using all 3 methods (LTRIM/RTRIM, RTRIM/LTRIM, and TRIM), then I would either have to create 3 different indexes (bad idea), or else create just one of ’em, and incentivize my users to query the data in a consistent way.
To learn more about this technique and how to solve more complex non-sargable queries, check out the Mastering Index Tuning module on filtered indexes, indexed views, and computed columns.

34 Comments. Leave new
Couldn’t you create 3 pre-baked columns (one for each trim method) then add all three to a single index?
Index column order matters. So, no. Not if you want to achieve the single-row index seek result for each of the three column versions.
The more I learn about Database design and Indexes, I’m getting more against functions in the Where clause. Also, we started doing code reviews in my current project and I’m pointing out bad code.
Also, make sure your computed columns are PERSISTED on the disk. I guess the Index would do this too, but just my preference.
Thanks as always for a great post!
Isaac – the index takes care of that. I actually hate persisting computed columns on the clustered index because adding them is so invasive and outage-inducing.
Personally, I’ve mostly used persisted, computed columns as a means of keying non-clustered indexes. E.g., storing checksums or truncated data.
You realize you don’t have to persist them to index them though, right? See the example in the post.
You know how sometimes, you repeat the same thing over and over again and the people you’re addressing ignore you over and over again? Well, once in a while those people actually read what you said.
Somehow, I not only missed that in the article. but also missed that in your reply to Isaac. So much blindness. I didn’t miss it this time.
Thank you 🙂
Hahaha, you’re welcome! And yeah, that’s my life, heh.
I didn’t believe what I was seeing the first time I noticed my existing queries using my shiny new computed column’s index before I’d had time to change the column names over, so I’m fine with Microsoft not going overboard on trying to detect the equivalence of the computations in that bit of the engine. I see it as a bonus. It’d be a lot of work to make things magically go faster in some function-heavy queries; as somebody who’d avoid that kind of behaviour in the first place I’d rather see them put that effort into new features or outstanding user requests. They’ve already done a lot of “It Just Runs Faster” stuff to help the accidental DBAs. That said, if they did write something like that, they’d have basically written a refactoring tool that they could bundle into SSMS…
I apologise for the utter dearth of linebreaks there.
My bad.
Hi Brent,
Hi Folks,
great article. I once tried to follow this approach of a calculated column for a query from an ORM (Hibernate).
I guess it is mostly self exploratory. We have a table with information about our partners like address data. The query then implements a function our developers call “Search All”: A user can simply slam in a search pattern and all relevant columns will be searched for a combination of this. For example you could search “Brent%Chicago” and it will return all the people named “Brent” living in “Chicago”. If somebody happens to be named “Brent W. Chicago” (Chicago being the last name) of course this partner will also be in the resultset.
The way this is transformed by the ORM is a big coalesce statement with params for placeholders like Spaces.
Here’s an abbreviated example:
DECLARE @P3 varchar(8000) = ‘ ‘
DECLARE @P2 varchar(8000) = ”
DECLARE @P1 varchar(8000) = ‘ ‘
DECLARE @P0 varchar(8000) = ”
AND (lower(((((((coalesce(partner1_.name, @P0)+@P1)+coalesce(partner1_.zipCode, @P2))+@P3)
Nobody knows why this is done that way…point is even as its our self-developed system we have no way of changing that behaviour (and devs are not willing to put custom hand crafted SQL in there). So my approach in creating a calculated indexed column unfortunately didn’t work based on the parameters.
Did I miss something here or do you have any additional recommendations?
The plan is on https://www.brentozar.com/pastetheplan/?id=SJdq1nuCS
Thanks a lot in advance
Martin
P.S. If I should head over to StackOverflow instead asking here that’s fair…just let me know.
Martin – yeah, for support questions, head over to https://dba.stackexchange.com.
slight aside
The rtrim() is redundant as SQL Server ignores trailing spaces
So if I add a row to People with a leading Z and four trailing spaces either of the queries below does an index seek and returns 1 rows
select * FROM [WideWorldImporters].[Application].[People] where fullname = N’ZBrita Jarvi ‘
select * FROM [WideWorldImporters].[Application].[People] where fullname = N’ZBrita Jarvi’
& the forum editor removes trailing spaces too – but in the first query there should be 4 of ’em 🙁
Some of the authentication libraries I’ve played with get end up stuffing an UPPER into the where clause to ensure that fields are case-insensitive. This sort of thing happens when the author uses an ORM and pays no attention to what the ORM is doing. Of course, the author doesn’t notice a problem in development, because full table scans on near-empty user tables are cheap.
Tip: The way to maintain case-insensitive compares is to use a case-insensitive collation. I think most people will be satisfied with a database-level case-insensitive collation, but this can be done at the column level if necessary.
One interesting thing i’ve noticed today is that if you have something like
DECLARE @Test nvarchar(15) = ‘%Test’;
SELECT Col FROM Table WHERE Col LIKE @Test
then the actual execution plan will read Index Seek with Seek Predicates even though that’s not possible, so it seems to decide at runtime whether or not to seek.
The link below states that persistent is required to index on computed columns. Is the article outdated, misleading or just plain wrong?
https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-table-computed-column-definition-transact-sql?view=sql-server-ver15
You tell me. Did you try the scripts in the post?
Yes, looks good. I’ve submitted feedback to the MS article with a link to this one.
Forgive me if I’m incorrect, but does that line in the MS article actually just refer to indexes on non-precise (but still deterministic) computed columns. In Brent’s article, the computed column is both deterministic and precise.
Also, thanks for the article Brent! Always enjoy learning something new!
Would doubling up on the where clause also be effective?
Something like
SELECT * FROM dbo.Users
WHERE
DisplayName = N’Brent Ozar’
AND LTRIM(RTRIM(DisplayName)) = N’Brent Ozar’;
It looks a bit silly
Dan – at that point, the second WHERE filter is extraneous. By adding the first one, you’ve made it sargable, and that’s the end of the story there. I applaud your creativity though, hahaha.
Ah, I missed explaining a crucial part of my thinking there. If for some reason you didn’t want to (or couldn’t) make any changes to the database to add the computed column + index, would just modifying the query to have the double WHERE have met requirements? First where clause for sargability, second where clause for “Say I don’t trust the data in my database”.
Can you do a demo of a scenario where both of the WHERE clauses together produce valid results with an index seek, and the single WHERE DisplayNamr = ‘Brent Ozar’ does not produce valid results by itself?
Well, dang. No, I cannot. Because I was an idiot!
My query was wrong, regardless of indexes. Leading spaces are valid (we don’t trust the data), but rows without leading spaces will be filtered out by the first clause. In order for it to work, my original query would have to be an OR not an AND. By which time you’re going to be doing the table scan, so you need the index, and can drop the “creative” double where clause because it not only looks stupid, it is stupid 🙂
Thanks for making me think about it some more!
You’re welcome! Yeah, I couldn’t figure out how that would work, it I thought I might be missing something. I tried a couple of demos and couldn’t figure out how it would work, but I’ve been wrong plenty. Cheers!
You omit to mention something absolutely critical with indexes on computed columns.
For some reason I’m not clear on, there are strict limitations on using computed column indexes and particularly the SET options are a deal breaker (or shall we say App breaker).
So you need to create an index on an existing computed column, and great, your new query performs well.
You test in UAT, All good.
You deploy to Live. All good…. for a bit.
Then suddenly support requests start piling in as unexpected errors begin appearing all over your app. Pages are hanging or queries are erroring and messages about incorrect SET options start crippling everyone, no one can work, everyone is pointing fingers in your direction.
So you start pulling your hair out and realise that if ANY of your 5000+ existing stored procs that touch this computed column happen to have been created or modified with an unsupported SET option eg Quoted_Identifier Off (usually completely by accident) the proverbial will start hitting the fan and get flung everywhere. Then of course there are some cases where your code happens to use DSQL and you absolutely require Quoted_Identifier OFF but also use the computed column that you have just indexed…
This feature, at least in every case I’ve encountered, has failed as not fit for purpose and we have to drop the index in order to get the systems back up. The risk is just too great that someone will accidentally alter a proc where their connection happens to have quoted_identifier off (happens more often than you might think), and suddenly BOOM, sql server puts its feet up.
Or perhaps I’ve missed something…?!
Yep, we dig into that in the Mastering Index Tuning class. Only so much I can teach in one blog post. There are more gotchas than these, too!
Yes I find the underlying complexities of some of the new features often thwart the solutions it tries to offer!
Not long ago I experimented with in-memory tables (sql 2016) for a new feature required for one of our applications where we needed to identify data-entry duplicates across many different fields against millions of existing records. The in-memory solution was about 7x faster in development, but when tested with production data, sql server would randomly crash and we had no option but to abandon using the new feature and revert to the traditional query methods!
Guys, I have been trying this technique with a CONVERT function, but I cannot seem to get it to work.
example query:
SELECT * FROM dbo.entry e WHERE CONVERT(CHAR(10),e.entry_date, 101) = ’06/15/2020′
My table changes:
ALTER TABLE dbo.entry ADD entry_date_day AS (CONVERT(CHAR(10),entry_date, 101)) –PERSISTED
GO
CREATE NONCLUSTERED INDEX [IXTEMP_entry] ON [dbo].[entry] ([entry_date_day] ASC)
Any ideas why it is not picking up on using the index? I tried both persisted and non-persisted.
I can’t do personalized code checks in the comments, unfortunately, but head to a Q&A site like https://dba.stackexchange.com.
Brent, could you try with your own code with a convert function? I can try stackexchange as well, just curious to see if you could get it to work.
I’m busy teaching classes right now, unfortunately.
No worries, was able to answer my own question. Since they are using select *, SQL Server was deciding to use the PK. Seems I have two choices: 1) Include almost everything, or 2) force the index.