Chaining Agent Tasks For Alerting The Right Way
Step By Step
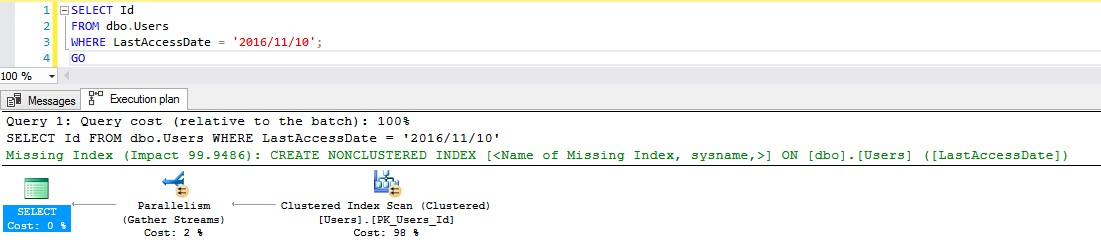
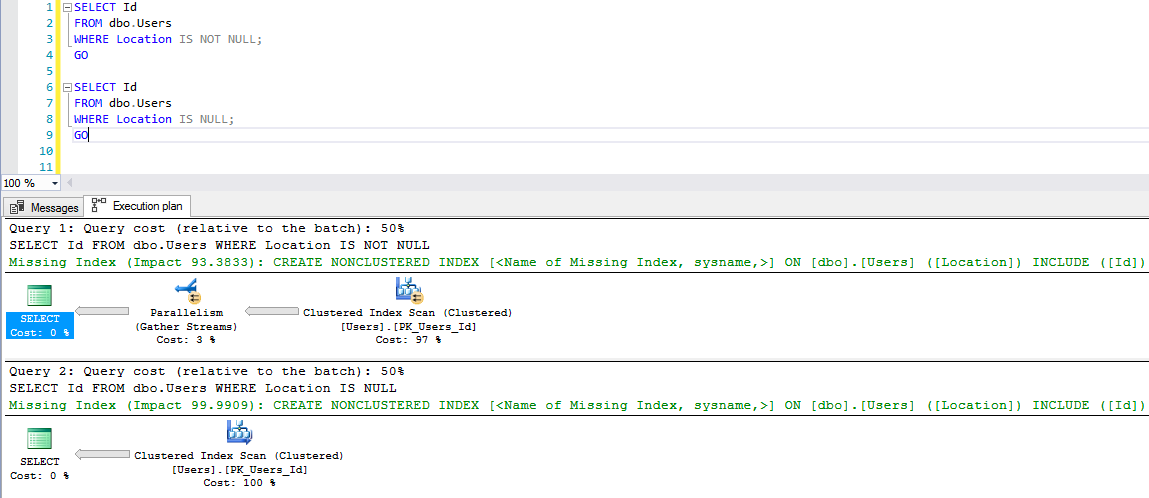
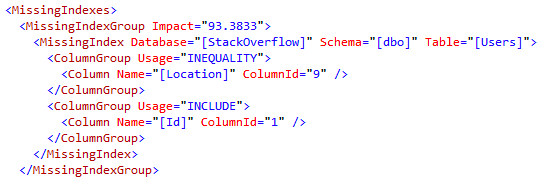
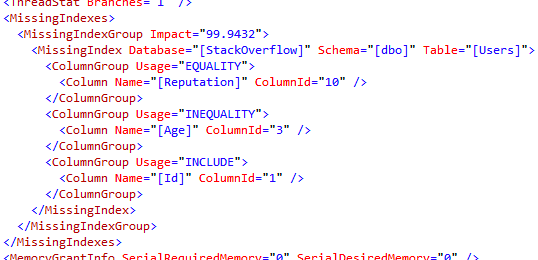
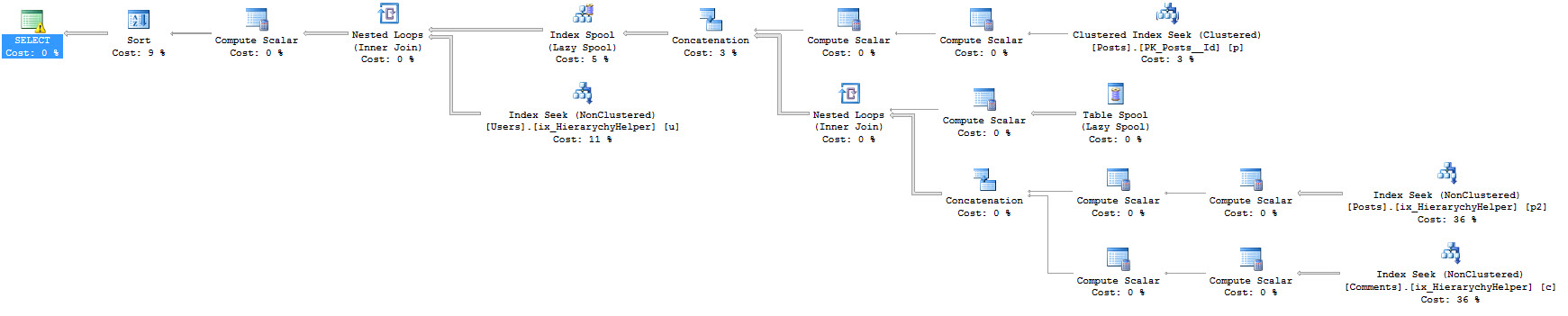
When you think about setting up maintenance, a persistent fear is that tasks may step on each other. You probably don’t want backups and CHECKDB and statistics maintenance running at the same time as statistics maintenance (notice I didn’t say index maintenance, here, because you’re smart and you skip it?). You may also throw in some other steps, like cleanup tasks something.
Your next fear is that if one step fails, you won’t go to the next step. For instance, a Sort from Statistics maintenance may fill up TempDB, a drive for backups may run out of space (or the network path could get yoinked), or there might be some (DEARPLEASEGODDONTLETITBECORRUPTION) error associated with DBCC CHECKDB (like one of those weird NTFS fragmentation errors) or something.
At no point should one step failure lead to another step not running, so you do something like this.

The trouble is, when a step fails, there’s no way for you to get a notification that a step failed (unless you write some custom code within the job).
Bummerino mi amigo.

In The Know
The smart thing to do is use built-in stored procs to call other jobs.

This allows you to retain control over job run order, and still get emails when individual job steps fail, because each job can report and alert on failure.
Update Antony correctly points out that this will go out and run your jobs asynchronously. There’s a second part to this where I discuss how to control that further.
Thanks for reading!