![]() The SQL Server community has been waiting a long time for an in-depth Windows clustering course on current versions of Windows.
The SQL Server community has been waiting a long time for an in-depth Windows clustering course on current versions of Windows.
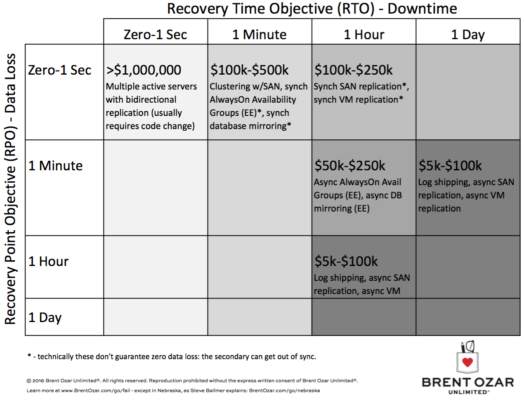
See, AlwaysOn Availability Groups as well as good ol’ Failover Clustered Instances both rely on Windows clustering in order to manage uptime. If you’re going to do an AG or an FCI, you gotta know Windows.
Edwin Sarmiento, a well-respected cluster expert, has brought out an online course, and it’s big. I’m hearing great things about it from folks I know who have gone through it.
Go check out the launch specials he’s running. He’s been running deals that include his HA/DR deep dive course, Personal Lab course, and Azure HA/DR Hybrid Solutions course. If you’re doing clustering, you should go take a look.