I’m Coming to the PASS Summit in Frankfurt!

The pre-conference lineup for the PASS Data Community Summit Frankfurt event was just released, and I’m proud to share that I’ll be teaching my new all-day pre-conference workshop.
Dev-Prod Demon Hunters:
Finding the Real Cause of Production Slowness
Production is slow. Development is fast. The same query runs in both. Somewhere between the two, a performance demon is hiding—and this session is about hunting it down.

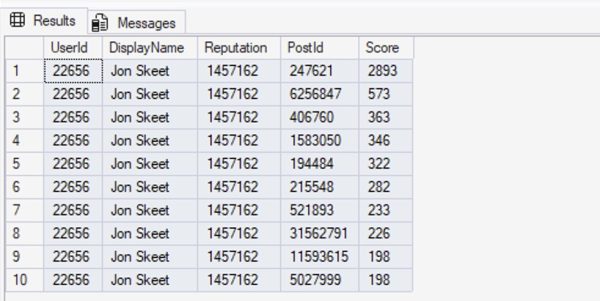
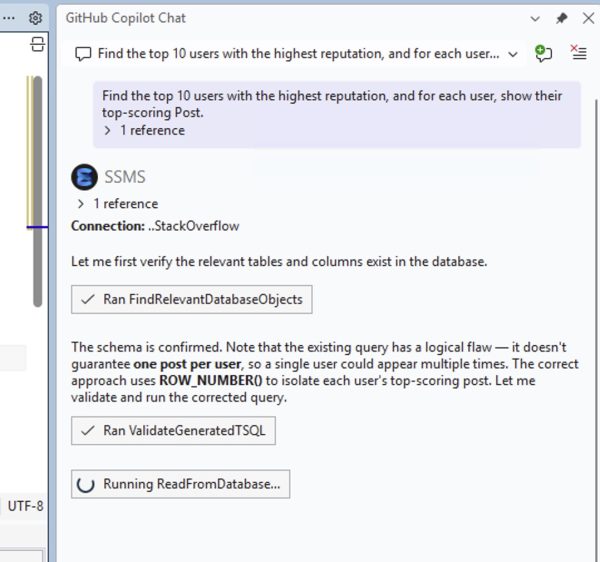
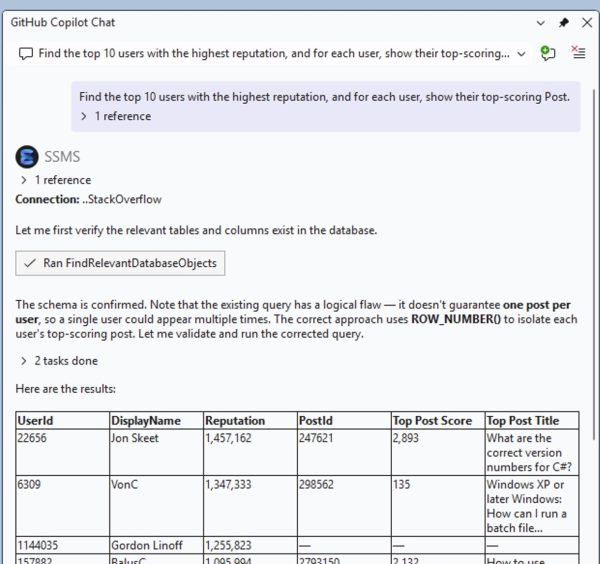
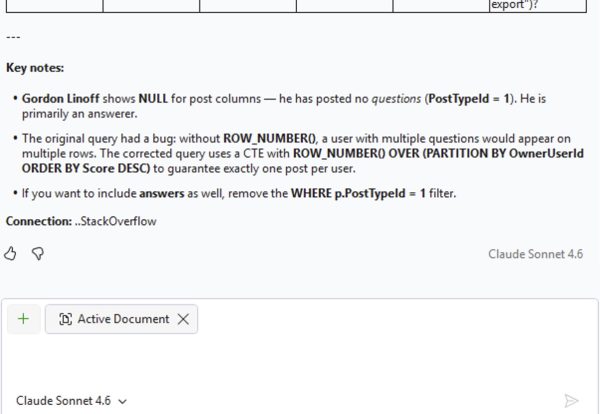
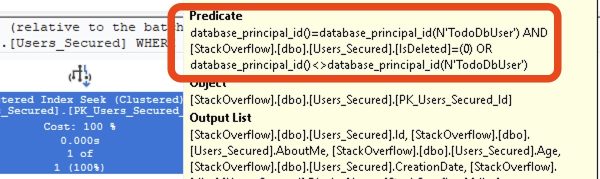
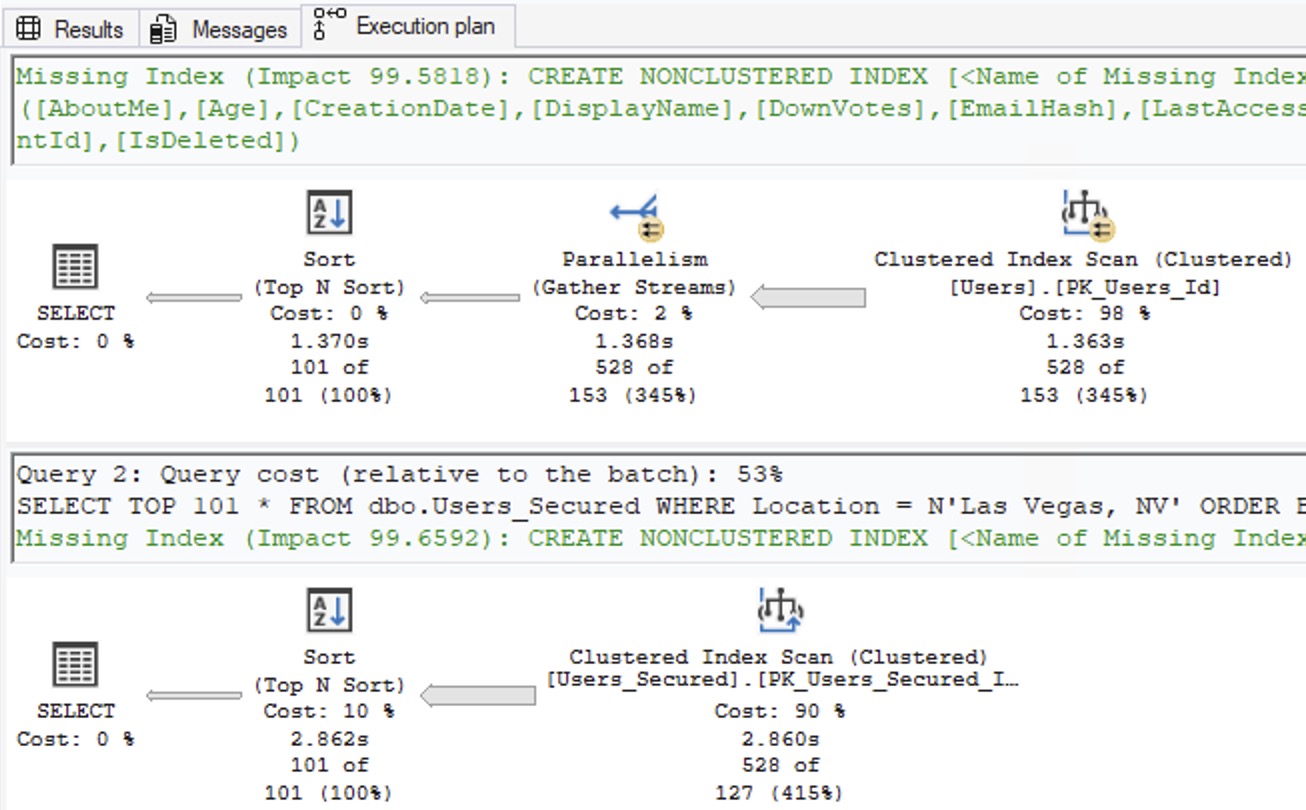
Inspired by Brent Ozar’s love of the K-Pop Demon Hunters theme song, this class is delivered almost entirely as live demos, not slides. Brent Ozar will run real queries against two environments labeled “dev” and “prod,” then work through them exactly the way an experienced DBA would in the real world: comparing server settings, analyzing execution plans, and uncovering the subtle differences that led SQL Server to make different decisions. Each “hunt” reveals another demon—statistics, configuration, data distribution, or plan choice—and shows how easily a test environment can lie.
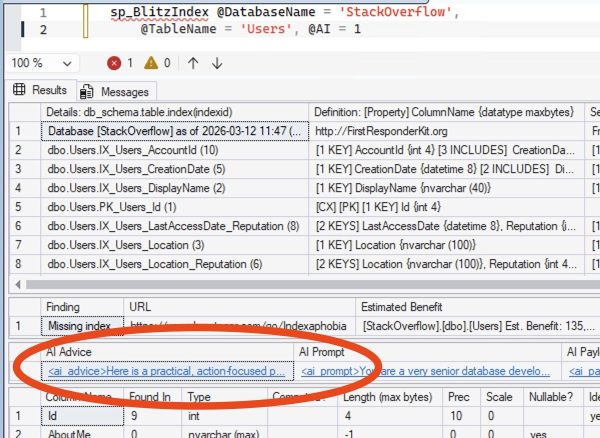
Along the way, Brent will demonstrate practical techniques you can use immediately: running sp_Blitz to surface meaningful environment differences, comparing execution plans to understand why SQL Server behaved differently, and making targeted changes to development so it better reflects production reality. By the end, you’ll understand how to stop guessing, stop blaming the engine, and follow the clues that lead to the truth—because when dev and prod finally move in sync, that’s when performance goes golden.
3 things you’ll get out of this session
- Discover what caused query plans to vary from production
- Learn how to quickly assess environment differences that would cause query plan changes
- Understand how to change dev to more closely match prod
Pre-requisites: You should already be comfortable writing queries, reading execution plans, and using the First Responder Kit to gather data about your server’s wait stats and health.
Registration is open now with early bird pricing expiring March 31 (quickly!), and attendees will get a free year of my Recorded Class Season Pass: Fundamentals. See you in Frankfurt!









 If your company is hiring, leave a comment. The rules:
If your company is hiring, leave a comment. The rules: