[Video] Office Hours: Ask Me Anything About Microsoft Databases
8 Comments
I’m back at home in Vegas, taking your top-voted questions from https://pollgab.com/room/brento on a hillside enjoying the fall desert weather.
Here’s what we covered:
- 00:00 Start
- 03:10 Bruce: Howdy! When, if ever, would you recommend implementing a SQL Server Central Management Server?
- 04:09 Impostor Syndrome: Are multi-TB databases really all that rare? I have several that are over 10 TB, but I don’t think of myself as being in a top 1% company.
- 05:23 LikeHeardingCats: Hey Brent. You’ve mentioned in the past, I believe, that you deal with Imposter Syndrome. Being the SQL Guru that you are, do you still have doubts when it comes to SQL Server? If so, how do you manage those thoughts?
- 07:29 Stefano: Hi Brent, I make extensive use of temporary tables (
- #table) for complex reporting or data extraction queries, particularly for preprocessing data from linked servers (yes, they exist…). My tempdb is fast and capacious. Are there any drawbacks to this approach?
- 10:31 Dopinder: What’s your opinion of the various AI engines ability to optimize TSQL queries and sprocs? Which one is best?
- 12:02 Culloden: Hey Brent, Have you participated in any recent DBA interviews for your clients? If so, have you noticed any trends in what skillset employers are seeking?
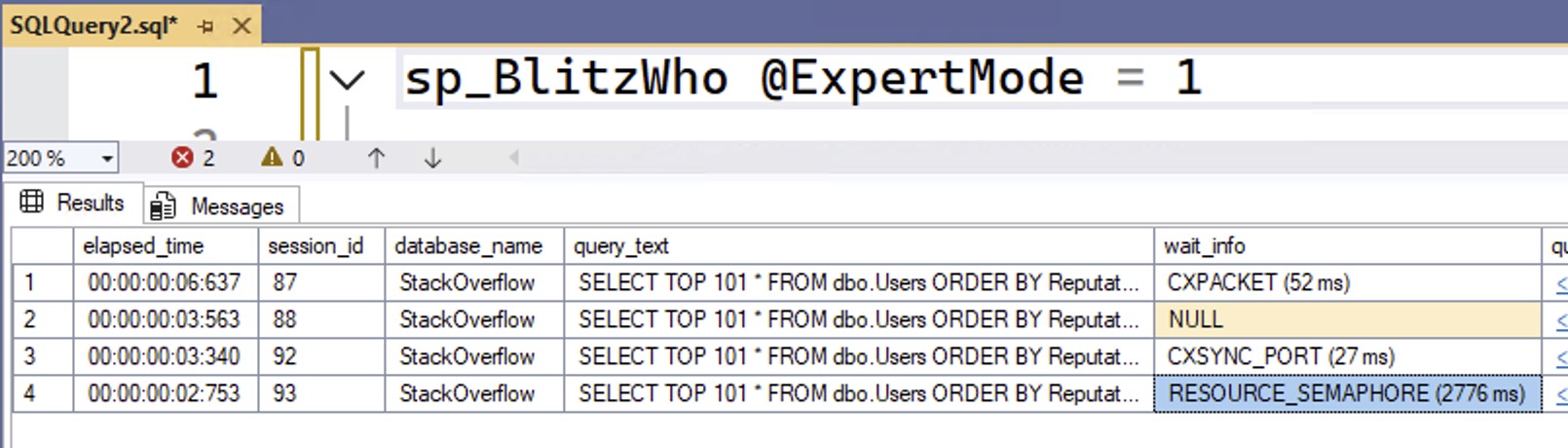
- 13:45 Parameter Sensitive Boyfriend: Terminology question: if I have a query with OPTION(RECOMPILE) that has massive variation in performance based on what arguments are passed in, is it considered parameter sensitive?
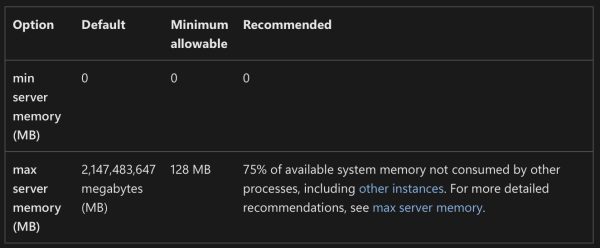
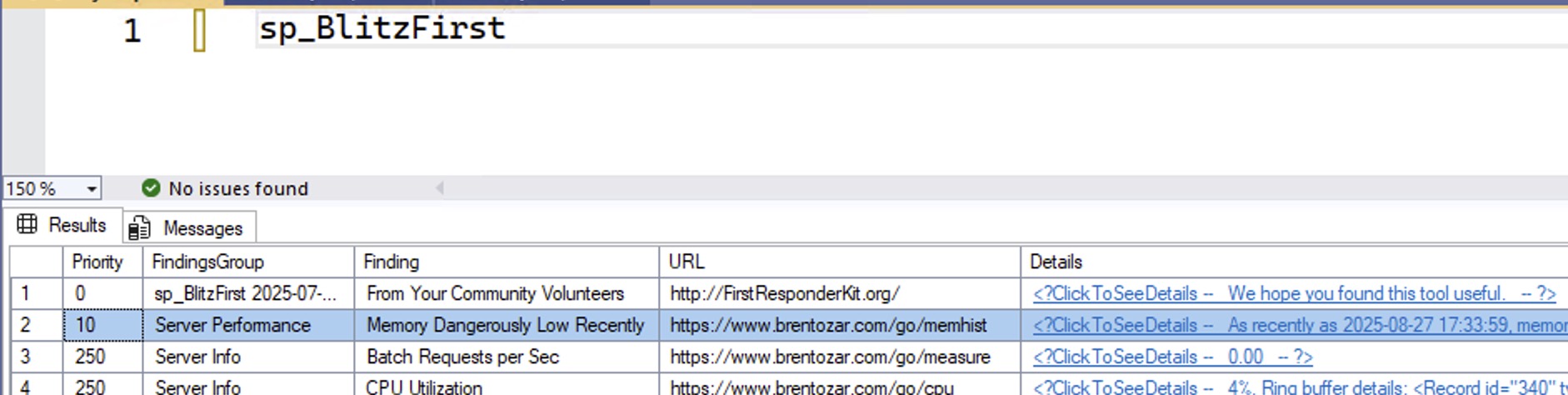
- 14:47 MyTeaGotCold: People tell me that 32 GB of RAM is enough for a high-end gaming PC. I’m looking to build one, but my DBA instincts say that anything less than 100 GB is unacceptable. How do you resolve this conflict in your machines?









 I’m teaching my two most important classes live, online, completely free!
I’m teaching my two most important classes live, online, completely free!