Updated First Responder Kit and Consultant Toolkit for July 2019
3 Comments
Nothing too dramatic, mostly bug fixes this month. Been pretty quiet on the development front the last couple of months. Some stability is nice around here, eh?
To get the new version:
- Download the updated FirstResponderKit.zip
- Azure Data Studio users with the First Responder Kit extension:
ctrl/command+shift+p, First Responder Kit: Import. - Download the updated Consultant Toolkit in your account
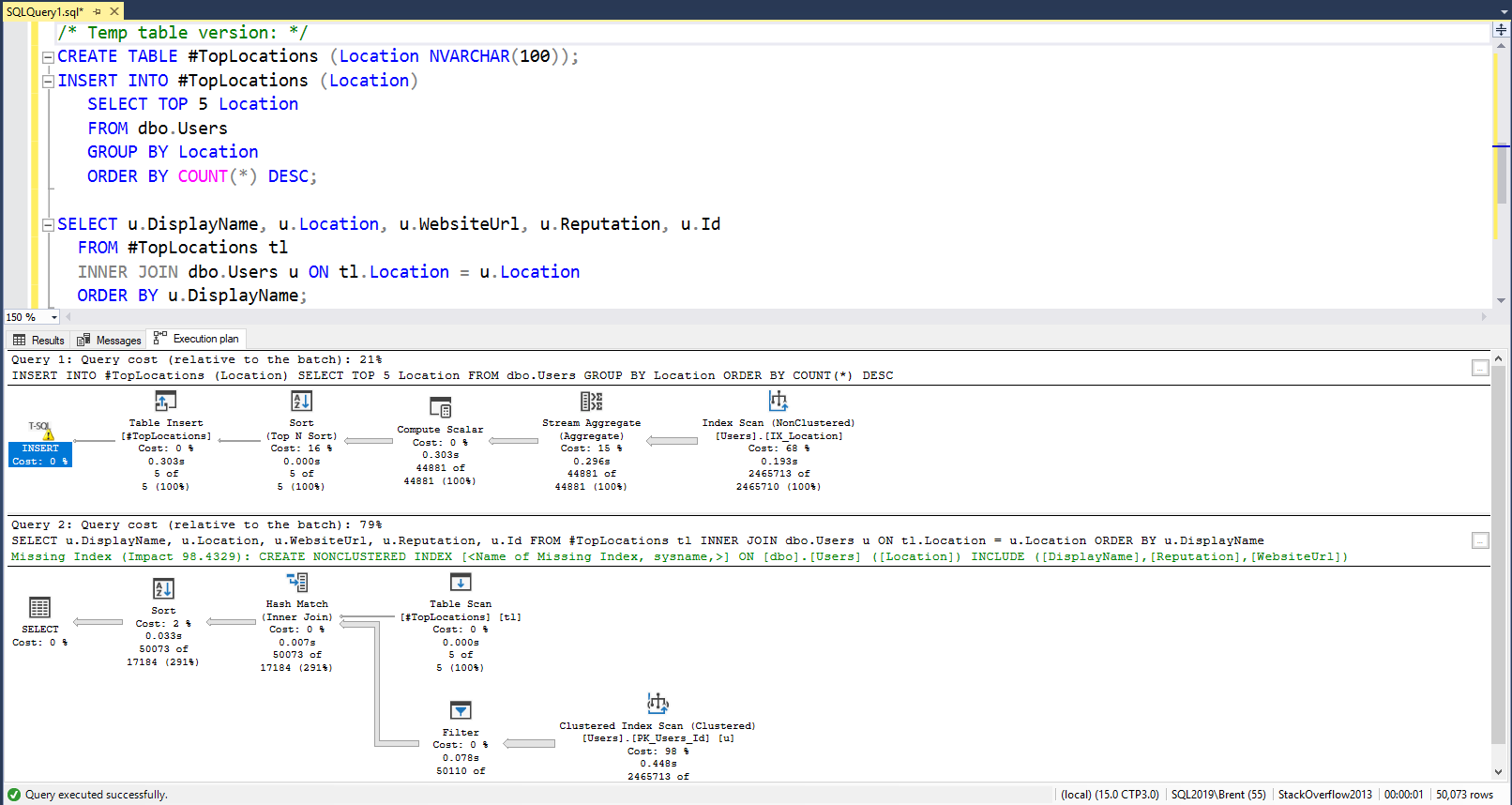
Consultant Toolkit Changes
- Improvement: the sp_BlitzCache recent compilations tab is now populated first to make sure that it shows user queries, not queries from the Consultant Toolkit itself.
- Improvement: if deep dive is turned on, also turn on sp_BlitzIndex’s @BringThePain = 1. This gathers data for over 50 databases.
- Fix: on the Plan Cache tab, the contents of column G are now accurate. (They were being overwritten by the contents of column H before.)
sp_Blitz Changes
- Improvement: easier troubleshooting when implicit transactions are running. (#2042)
- Improvement: @OutputType = ‘XML’ will now export the entire result set as a single XML field. (#2047, thanks Rich Benner.)
- Fix: fixed link typo on alerts URL. (#2055, thanks Rich Benner.)
sp_BlitzCache Changes
- Fix: excludes readable secondaries on 2016 by default. Otherwise, it was throwing an error when the database wasn’t available without specifying read-only intent. (We could probably improve this code to check for that as well.) (#2027, thanks sivey42.) Note that Adrian Buckman is still having issues with logging sp_BlitzCache to table on a readable secondary, and he’s tracking that down in issue #2072 if you want to give him a hand over there.
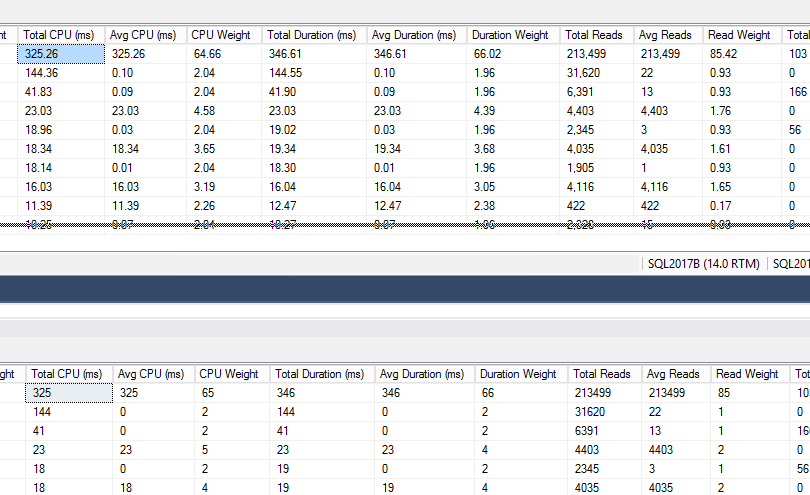
- Fix: many display fields are now rounded to ints (rather than formatting with the money datatype.) An example of the output is below – the top is before, below is after, showing the new rounded numbers. (#2046, thanks Ian Manton.)
sp_BlitzFirst Changes
- Improvement: easier troubleshooting when implicit transactions are running, and now only shows lead blockers. (#2042)
sp_DatabaseRestore Changes
- Fix: when @BackupPathFull was null, no transaction log backups were being applied. (#2036, thanks Troy Jennings for the bug report & code.)
sp_ineachdb Changes
- Improvement: compatibility with 2008 and R2, VMware snapshots where @@SERVERNAME returns the wrong name. (#2061, thanks sm8680.)
For Support
When you have questions about how the tools work, talk with the community in the #FirstResponderKit Slack channel. If you need a free invite, hit SQLslack.com. Be patient – it’s staffed with volunteers who have day jobs.
When you find a bug or want something changed, read the contributing.md file.
When you have a question about what the scripts found, first make sure you read the “More Details” URL for any warning you find. We put a lot of work into documentation, and we wouldn’t want someone to yell at you to go read the fine manual. After that, when you’ve still got questions about how something works in SQL Server, post a question at DBA.StackExchange.com and the community (that includes us!) will help. Include exact errors and any applicable screenshots, your SQL Server version number (including the build #), and the version of the tool you’re working with.