Updated “How to Think Like SQL Server” Videos
2 Comments
On my East Coast user group tour last month, I presented my How to Think Like the SQL Server Engine course to a few hundred folks. I’m always trying to learn and adapt my delivery, and I noted a lot of attendee questions this round, so I updated the course.
This is my favorite course I’ve ever done. In about an hour and a half, I cover:
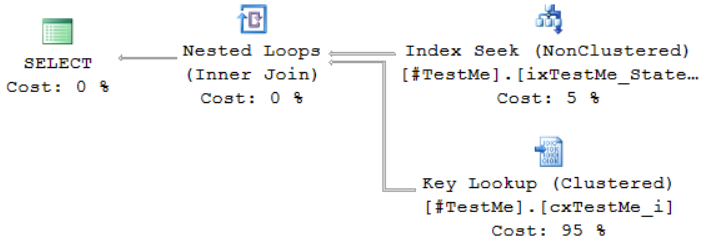
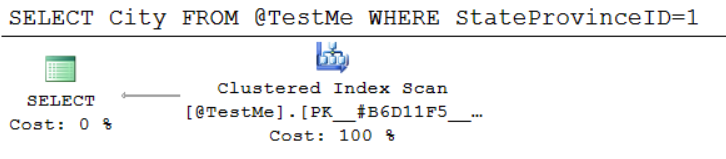
- Clustered and nonclustered indexes
- Statistics, and how they influence query plans
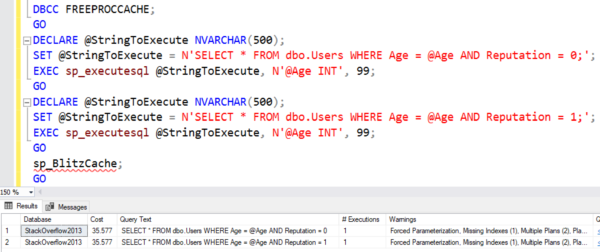
- How sargability isn’t just about indexes
- T-SQL problems like table variables and implicit conversions
- How SQL turns pages into storage requests
If you’ve always wanted to get started learning about SQL internals, but you just don’t have the time to read books, this course is the beginning of your journey.
Attendees give it rave reviews, but this one is one of my favorites:
@BrentO I came to that presentation thinking I was too cool to take notes then ended up furiously trying to keep up with taking notes.
— Andrew Notarian #BLM (@anotarian) April 4, 2014
Go check it out and let me know what you think.