This year there’s a couple of special challenges you need to keep in mind for projecting your beautiful knowledge out to the audience.
Fixing the Contrast Levels
PASS distributes a custom PowerPoint template – looks great this year – but the contrast level is extremely light. The template uses light blue and light gray text on a white background. In a bright room with less-than-perfect projectors, this is going to wash out pretty badly, and people won’t be able to read your brilliant nuggets of wisdom.
To fix this, open the slide template and click View, Master, Slide Master. Mine is Office for the Mac, but the general idea will hold true across all versions of PowerPoint:

Click on the slide title (“Click to edit Master title style”) so that the whole entire title box is selected, not the text in the title, and click onto the Home tab of the ribbon. From there, you can change the font color:
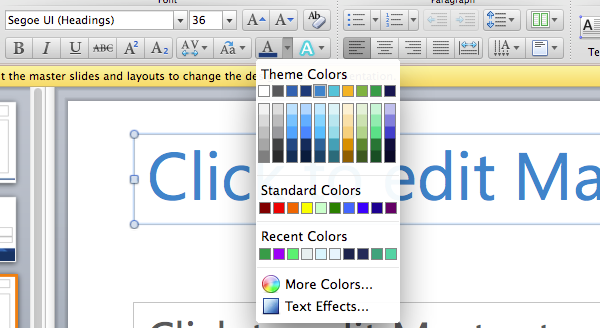
Just use a darker version of the existing color – that way the slides will still look matchy-matchy, but just have more contrast.
Repeat the same process with the content box as well, turning it into a darker gray or black.
This is totally okay – Lana Montgomery of PASS HQ writes, “Feel free to adjust the depths of the colors for the blue and grey for your presentation.”
Next: That Widescreen Thing
This year’s slide template is widescreen – 16:9 aspect ratio – and the projectors are widescreen as well. The minimum resolution will be 1280×720.
This is a fantastic resolution for slides, but if you’ve got demos, you need to make sure to test them at the 1280×720 resolution. There are some parts of SSMS’s user interface where buttons disappear at just 720 pixels of vertical resolution, for example. If you’re using a virtual machine, and you’re sacrificing some pixels at the top and bottom for toolbars, this may be even worse.
If you’re doing query demos, you may also want to take the widescreen effect into account. Often I run SSMS in a 4:3 aspect ratio, like 1280×1024, and there’s plenty of space to put the query at the top and my execution plan at the bottom. In a widescreen aspect ratio, that’s not the case – you’re better off putting the query in a pane on the left, and the plan in a pane on the right.
Knock ’em dead! And while you’re prepping, ask these 51 questions about your session.