Thoughts About Stack Overflow’s Annual Developer Survey
7 Comments
Every year, Stack Overflow runs a developer survey about technology, work, community, and more. This year’s results include 65,437 responses from developers around the world.
The results are biased towards the kinds of developers who use Stack Overflow – 76% of the respondents reported that they have a Stack Overflow account. I would guess that it’s nowhere near a perfect picture of all developers worldwide, but let’s just focus on the fact that it does represent how over 65,000 developers feel – and that alone is useful enough to give you a picture of what’s happening in at least a lot of shops worldwide.
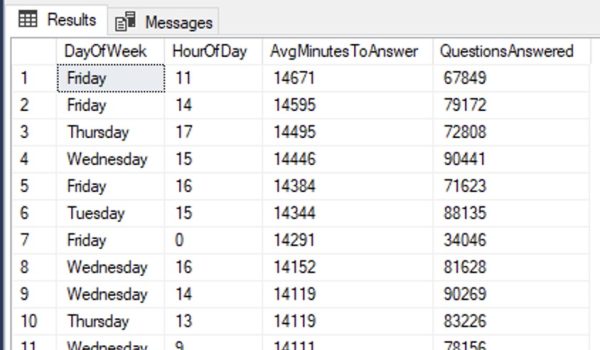
The most-used databases were PostgreSQL, MySQL, SQLite, and Microsoft SQL Server, in that order:

When Jeff Atwood and Joel Spolsky first started Stack Overflow, Jeff did a lot of evangelization work for it, and Jeff’s audience was heavily biased towards .NET development. I would imagine that’s part of why SQL Server is by far the highest paid database in the list (as opposed to open source.)
I have a total blind spot around SQLite, but often on my TikTok videos when the discussion of licensing costs comes up, some commenters will ask why everyone in the world doesn’t use SQLite. I’m sure there are a lot of apps worldwide that simply don’t need a database server, only a small local relational storage, and I can understand why those developers would have a similar blind spot about what it’s like to handle concurrent load in an enterprise-wide ERP app or e-commerce store.
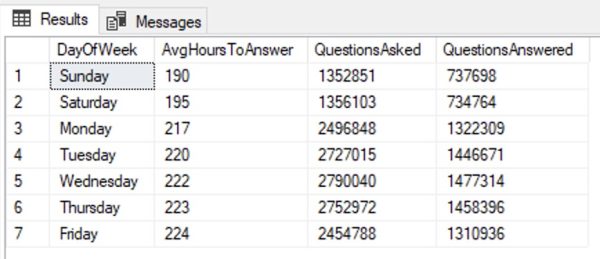
The next chart, admired-vs-desired, doesn’t make sense to me and I don’t trust the numbers:

From what I can tell, the blue scores indicate how much the respondents have worked with the database in the last year, and red scores indicate how much they want to work with it next year? I’m pretty confused by this one. Are the red scores exclusive to only the people who actually worked with the technology this year – meaning, out of the 15.4% of the audience that worked with SQL Server in the past year, 54.5% of them want to work with it next year?
And why don’t these numbers come anywhere near agreeing with the prior question? The prior question says 25.3% of the audience used it last year, but the admired-vs-desired question says only 15.4% did? I’m so lost. At first I thought this question is taking about “extensive” development work, whereas the first one might just be ANY database work – but the numbers don’t make sense there either, because Supabase scored 4% on the first question (any work), but 5.9% on this question (extensive work.) Both questions use the term “extensive.” I’m lost.
So yeah, I just discarded that question and didn’t bother to think about the results. It doesn’t make sense, so I don’t trust it.
There was also a question about which cloud provider folks used, and AWS dominated the market:

That’s been my experience too – the vast, vast majority of my cloud clients are on AWS – but I’m mentioning it here because I know that Azure users really seem to believe Azure’s the only game in town. When I talk to Microsoft MVPs, they seem dumbfounded that companies are actually using AWS extensively, and they also seem surprised that Microsoft is competing with Google for second place. (Google’s been throwing a lot of discounted/free compute power at prospective clients to win them over.)
There’s a lot more stuff in the overall results, especially the workplace trends section that talks about employment status, hybrid/remote/in-office, and salary. When you’re looking at each workplace graph, make sure to click on the geographic filter at the top of that graph so the numbers will be more meaningful to you, based on where you’re located.















 Goals:
Goals: