
Unusual Parameter Sniffing: Big Problems with Small Data
Normally when we think about parameter sniffing, we think about a tiny data vs big data problem: the tiny data’s plan goes in first, and when we try to process big data, performance is terrible.
But sometimes, it’s the exact opposite.
I’ll start with the large Stack Overflow database (I’m using the 2018-06 version, but any large one will do) and write a stored procedure to find the most recent posts authored by folks in a specific location:
|
1 2 3 4 5 6 7 |
CREATE OR ALTER PROC dbo.RecentPostsByLocation @Location NVARCHAR(100) AS SELECT TOP 200 p.Title, p.Id, p.CreationDate FROM dbo.Posts p INNER JOIN dbo.Users u ON p.OwnerUserId = u.Id WHERE u.Location = @Location ORDER BY p.CreationDate DESC GO |
To help SQL Server out – I’m a giver like that – I’ll create a few indexes to give SQL Server some choices:
|
1 2 3 4 5 6 7 8 |
USE StackOverflow; GO DropIndexes; GO CREATE INDEX Location ON dbo.Users(Location); CREATE INDEX OwnerUserId ON dbo.Posts(OwnerUserId); CREATE INDEX CreatioDate ON dbo.Posts(CreationDate); GO |
Call it for tiny data first…
When we call the proc for a less-populated location first, SQL Server chooses to look up the people who live in Iceland (because there aren’t many), and then go find their posts. Small data finishes in under 1 second:

If we now run it for a larger location, like Germany, the query takes 24 seconds to run because we find so many people in Germany, and they’ve posted so many answers. (I’m sure they’re not asking a lot of questions. Germans are really smart.)

And the sort spills to disk because we only granted Iceland-size memory.
This is the typical parameter sniffing problem that people blog about: put the tiny data parameters in memory first, and SQL Server just isn’t equipped to deal with big data.
But if the big data plan goes in first…
Do things perform better? Let’s free the plan cache, then start with Germany:

This time around, SQL Server says, “Ah, Germany’s really common. You’re asking for these posts to be sorted by CreationDate – as a reminder, here’s your query and your indexes:”
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE OR ALTER PROC dbo.RecentPostsByLocation @Location NVARCHAR(100) AS SELECT TOP 200 p.Title, p.Id, p.CreationDate FROM dbo.Posts p INNER JOIN dbo.Users u ON p.OwnerUserId = u.Id WHERE u.Location = @Location ORDER BY p.CreationDate DESC GO CREATE INDEX Location ON dbo.Users(Location); CREATE INDEX OwnerUserId ON dbo.Posts(OwnerUserId); CREATE INDEX CreatioDate ON dbo.Posts(CreationDate); GO |
“So since you’re asking for the top 200 by CreationDate descending, I’ll just scan the CreationDate index from newest to oldest. For each post I find, I’ll go look up the Users table to see where that user’s from. I bet I won’t have to look up too many before I’ll find 200 of ’em that were posted by Germans.”
And he’s right: he only had to look up about 20,000 of them before he found 200 that were written by Germans. Very cool.
But…when we run this for Iceland…

SQL Server has to read over a million Posts, doing over a million Posts key lookups, and over a million checks into the Users table before it’s found 200 posts that were written by Icelanders. Ten seconds isn’t so bad, but if you pass in an even rarer location, like the charming and easy-to-pronounce Hafnarfjordur, Iceland:

SQL Server again scans the index on Posts, doing a key lookup on Posts for every single row that it finds, and I bet that sounds goofy. Oh it gets worse: for all 40,700,647 Posts, it does a clustered index seek against the Users table. We do over 124 MILLION logical reads on a table that only has 143K pages in it. We read the Users table 871 times over, and the Posts table 6 times over due to all the key lookups:

That sure is a lot of work – would be nice if SQL Server parallelized that query across multiple threads. No can do, though – the query plan was designed with Germany in mind, when SQL Server thought it’d find rows quickly. The whole time this query runs, it’s just hammering one of my CPU cores while the rest sit idle:
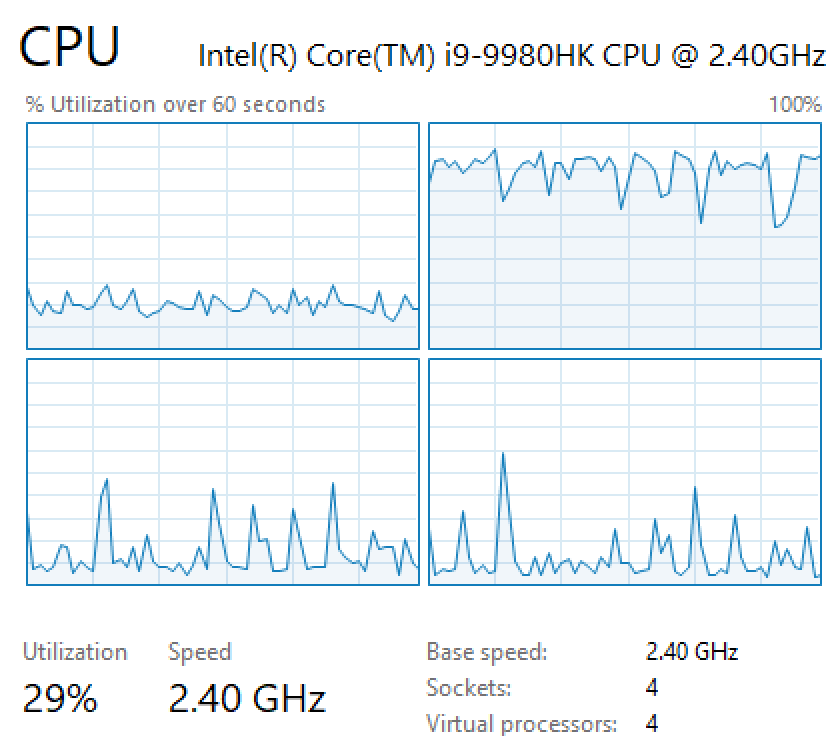
There is no one good plan here.
I always laugh when I see demos that talk about “the good plan” and “the bad plan.” I wish the real world was so simple, so black-and-white. In reality, queries have many possible plans, and many of ’em just don’t work for other sets of parameters.
SQL Server 2017’s “Automatic Tuning” does nothing here, either: it can try throwing a different plan in thinking there’s been a regression, but it’s not smart enough to pick different execution plans for different parameters. It picks one plan and tries to make it work for all of ’em – and that simply doesn’t work here.
It’s up to us to fix it, folks.
That’s why I teach my Fundamentals of Parameter Sniffing and Mastering Parameter Sniffing classes. Folks with a Live Class Season Pass can start watching the Instant Replays whenever they want, or drop in live. I’m teaching a bunch of classes over the next few weeks:

- Feb 3: Fundamentals of Parameter Sniffing – iCal
- Feb 4: How I Use the First Responder Kit – iCal
- Feb 5: Fundamentals of Columnstore – iCal
- Feb 8: Fundamentals of TempDB – iCal
- Feb 9-11: Mastering Server Tuning – iCal
- Feb 12-14: Mastering Index Tuning – iCal
- Feb 16-18: Mastering Parameter Sniffing – iCal
See you in class!

22 Comments. Leave new
No problem if you don’t want to answer this b/c it’s in your course, but what is the solution?
Many many years ago when I did SQL Server for a living I fixed this by creating a wrapper procedure that the UI would call. In the wrapper I would do a quick count/query for whatever I could identify as being the “small” and “large” plan.
Then I would call either the small or large subproc from the wrapper…basically the same proc but with different names. That was enough to ensure the “small” subproc got a distinct plan from the large proc and they could be tuned accordingly.
It seemed to work but whenever I had to explain this goofiness to someone else (b/c no one reads the comments) I felt like I needed a shower. Someone would invariably say, “use OPTION RECOMPILE” but that didn’t work in our use case b/c the proc was like 500 lines long and the query that went off the rails was halfway down. Others told me later that “automatic tuning” would fix that but no one was able to actually fix it.
Wondering what the right pattern is? Am I really as clever as I think I am? Or did I miss something simple?
I really wish I could boil down the right solution to a blog post comment, but…that’s why I teach classes. Some problems are more challenging to solve.
You do seem pretty smart indeed, since you already identified the two solutions to try first.
In cases like this, if the query doesn’t execute too often and is not too long/complex, adding a query level recompile hint is often the best solution. And if that’s impossible, then using multiple sub procedures can be a great idea if you have a cheap enough way to figure out which one to use. That also enables you to do targeted further tuning to each of the sub procedures.
But yeah. You’re smart. You already knew that.
Not smart, lucky. And I’d rather be lucky than good.
I remember trying statement level recompile but it didn’t work. Can’t remember why and it could be I was doing something wrong.
Feels like there’s a small set of known good patterns to solve anti-patterns that any tsql developer ought know…and this is one of them, the problem is, I think, there may not be a simple pattern solution. Other antipatterns that do have good solutions: INNER JOINs with OR clauses; nolock, correlated subqueries, UPDATE statements that cause eager spools, etc.
Based on what you wrote in your first comment, you might have tried procedure level recompile. You need statement level for this to work. That’s the level where SQL Server can also “sniff” (the actual term is different; it’s called inlining) variables instead of just parameters.
Problem with parameter sniffing is that, apart from the two patterns of splitting across sub procs and stmt level recompile, there are no other standard patterns. If those can’t be used or don’t work, you really need to dig into what causes the sniffing, what the potential bad effect is, what the query does, how you might mitigate it (I try to think about the execution plan I want to get), and how you can affect the code to get there. A lot of work, for a single query.
I will never not be weirded out by your referring to SQL Server as “him”. I worry that you maybe dressed your servers up in little hats and Groucho glasses back when you used physical servers.
Actually now that I’ve said that it’s not a worry, that would be awesome ?
Brent will probably respond that he sees SQL Server as male because he’s stubborn and doesn’t ask for directions.
And to be fair, he has a point.
On the other hand, SQL Server is always making everyone wait for her when you desperately want to go. That might make her female? Well, only if the reason is she’s putting on makeup. But she isn’t. He’s probably spooling rows he shouldn’t spool, and going parallel where you want him serial.
So yeah. Definitely a bloke.
Hahaha, I’m so proud that you remember that line, Hugo!
I thought there was probably a good, likely funny, reason for it and I wasn’t disappointed 🙂
I am happy to see you writing about Iceland and Germany :-). Inspring article and already great comment feed with answers from Hugo. Thanks for the insights Brent!
I know there are ways to do this, but it would be lovely if we could set up some parameters with flags that tell the compiler to make one plan per parameter value, or have it make up a hashmap of param values and several plans, so it compiles once, and then maps the plan to the value for future runs.
There are several ideas like that, that I am surprised just aren’t part of how SQL runs even these days.
Andrew – I really like your param hashmap idea, how about adding this as a feedback item so we can try and vote it up.
Hi Brent! Great post!
If you add the option (recompile) to the stored procedure,
Will there be a parameter sniffing problem?
No, but CPU usage sure will be, since you’ll need to spend CPU time compiling a plan every time the query runs. To learn more about fixes, check out my Mastering Parameter Sniffing class. Thanks!
Thank you, Brent!
Without option recompile, If you override the parameter as below:
Declare @Newlocation Nvarchar(100) = @Location
Does SQL Server need to spend CPU time compiling a plan every time the query runs?
Will there be a parameter sniffing problem?
Mehdi- I sure do wish I could teach my entire 4 days of parameter sniffing training here in the blog post comments for free, but that’s not realistic. Fair enough? See you in class!
Short answer (hope Brent doesn’t mind):
1. That has the same effect as using OPTION (OPTIMIZE FOR (@Location UNKNOWN)). Since the latter clearly specifies the goal and avoids extra work, I always recommend the latter and never the former.
2. This method will not cause recompiles.
3. It will also not cause parameter sniffing issues since you effectively disable parameter sniffing for this parameter. But it might cause other issues. You’ll get a plan based on overall generic distribution. Fine in some cases. Terrible in other cases.
4. If it’s terrible in your case, then either give Brent some money to teach you the full four days. Or give me (or another consultant) some money to fix it for you.
Either way, even if the above solves your problem, I’d still recommend going to Brent’s class. Because one day you’ll have another problem and then you can fix it without giving anyone money.
The article is fantastic.
So, I was curious to know what happens if we have some changes.
Sure there are many things to learn.
I will definitely try to be in brent class if I can.
Thanks to brent.
His teachings are very useful.
You are right, I was curious.
I wish you success.
Sure, you bet! My classes are chock full of curious folks. See you there!
Whaha, I was literally laughing out loud when I was reading this:
“(I’m sure they’re not asking a lot of questions. Germans are really smart.)”
Please keep up the good work of throwing these jokes in between the information dense lines, helps me to keep on reading 🙂
Hahaha, thanks Frank!