Computed Columns: Reversing Data For Easier Searching
10 Comments
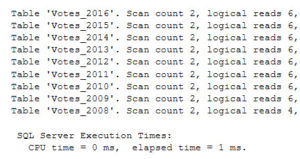
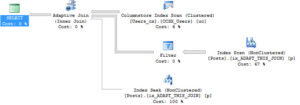
During Training We were talking about computed columns, and one of our students mentioned that he uses computed columns that run the REVERSE() function on a column for easier back-searching. What’s back-searching? It’s a word I just made up. The easiest example to think about and demo is Social Security Numbers. One security requirement is…
Read More