T-SQL & Development
How Scalar User-Defined Functions Slow Down Queries
When your query has a scalar user-defined function in it, SQL Server may not parallelize it and may hide the work that it’s doing in your execution plan.
To show it, I’ll run a simple query against the Users table in the Stack Overflow database.
|
1 2 3 |
SELECT TOP 100 DisplayName, Location, Reputation, Id FROM dbo.Users ORDER BY Reputation DESC; |
I don’t have an index on Reputation, so SQL Server has to sort all of the Users by their Reputation. That’s a CPU-intensive operation, so SQL Server automatically parallelizes it across multiple CPU cores:
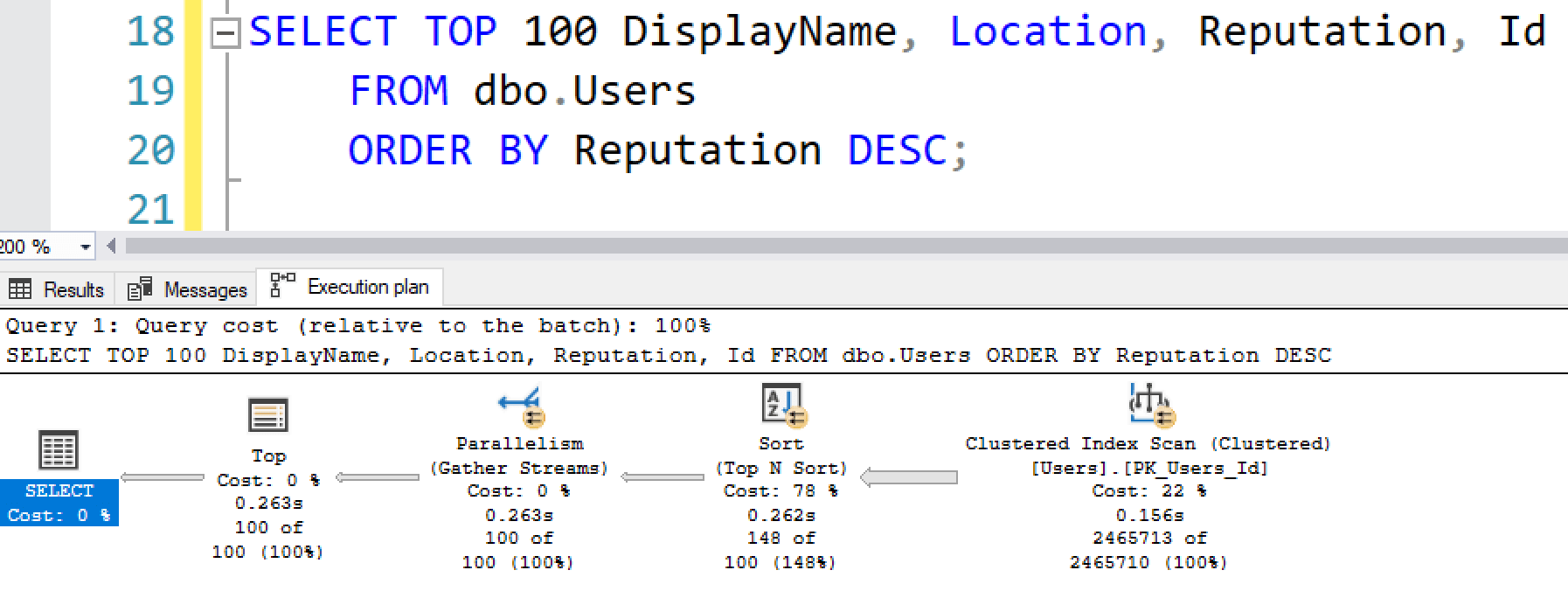
The racing stripes on the plan operators indicate that the operations went parallel. Another way to see that is by using SET STATISTICS TIME ON, which adds CPU time and execution time information to the Messages tab of SSMS:
|
1 2 |
SQL Server Execution Times: CPU time = 969 ms, elapsed time = 357 ms. |
See how CPU time is higher than elapsed time? That’s an indication that the query went parallel. Because work was distributed across multiple cores, SQL Server was able to get 969 milliseconds of work done in just 357 milliseconds.
But when we add a scalar user-defined function…
Say our users want to see their names and locations formatted a little more nicely. Instead of two columns that say “Brent Ozar” and “San Diego”, they want a single column that says “Brent Ozar from San Diego”. And I don’t want to put that concatenation logic all over the place in every query I write, so I encapsulate it in a function:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE OR ALTER FUNCTION dbo.FormatUsername (@DisplayName NVARCHAR(40), @Location NVARCHAR(100)) RETURNS NVARCHAR(200) AS BEGIN DECLARE @Output NVARCHAR(200); SET @Output = @DisplayName + N' from ' + COALESCE(@Location, N'Earth, probably'); RETURN @Output; END GO SELECT dbo.FormatUsername(N'Brent Ozar', N'San Diego'); |
The results are a little easier on the eyes:

Now, when I use that function inside the query, the query technically works fine:
|
1 2 3 4 |
SELECT TOP 100 dbo.FormatUsername(DisplayName, Location), Reputation, Id FROM dbo.Users ORDER BY Reputation DESC; |
But the execution plan is missing a little something:
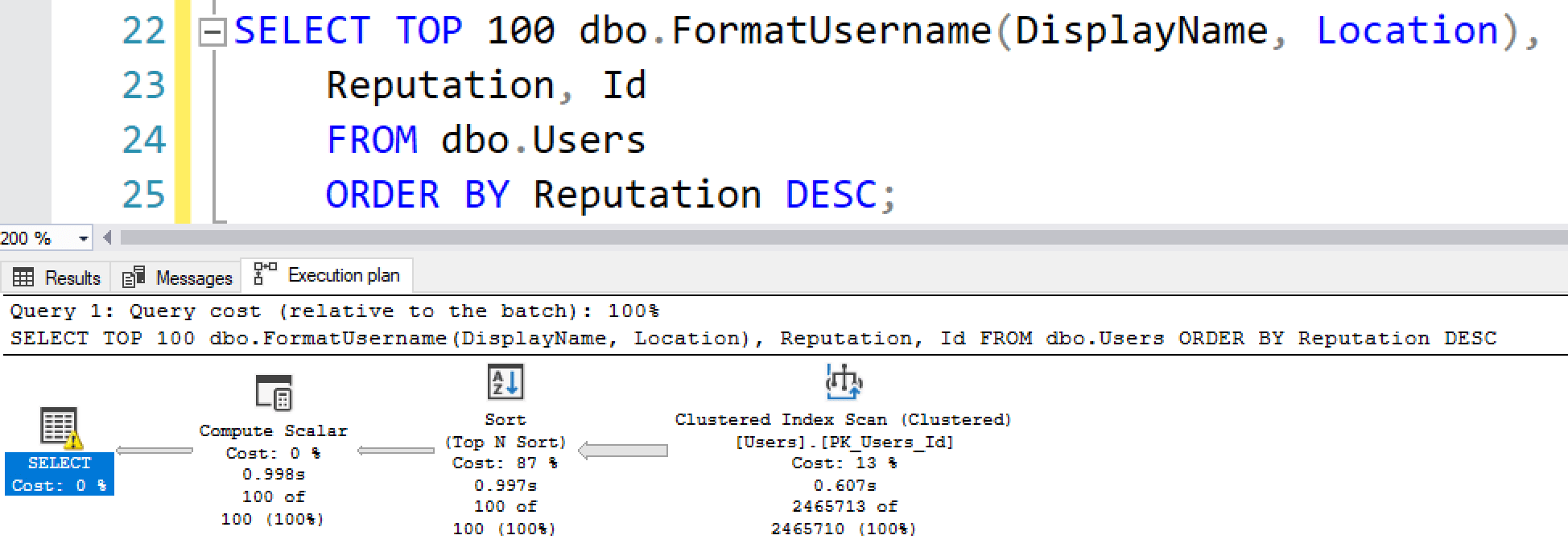
And the statistics time output shows that it still needed a lot of CPU, but since it didn’t go parallel, it took longer on the clock:
|
1 2 |
SQL Server Execution Times: CPU time = 1000 ms, elapsed time = 1093 ms. |
If you dig deeply enough in the execution plan properties, SQL Server notes that it couldn’t build a valid parallel execution plan, but it doesn’t say why:

There are a few ways to fix this.
One way is to inline the contents of your function – literally copy/paste the scalar function’s contents directly into your query:
|
1 2 3 4 |
SELECT TOP 100 (DisplayName + N' from ' + COALESCE(Location, N'Earth, probably')), Reputation, Id FROM dbo.Users ORDER BY Reputation DESC; |
This query goes parallel, proving that the concatenation and coalescing isn’t what was stopping us from going parallel – it was the presence of a scalar user-defined function:

Statistics time output shows that we went parallel and ran faster overall:
|
1 2 |
SQL Server Execution Times: CPU time = 1061 ms, elapsed time = 349 ms. |
Another way to fix it is to upgrade to SQL Server 2019 and set your database to 2019 compatibility level. One of 2019’s most ambitious features, code named Froid, aims to automatically inline scalar user-defined functions without you having to rewrite them.
When I set my database into 2019 compat level, the query with the scalar function goes parallel again:

And statistics time output shows the performance improvement:
|
1 2 |
SQL Server Execution Times: CPU time = 1062 ms, elapsed time = 351 ms. |
However, SQL Server 2019’s scalar function inlining comes with a huge number of drawbacks. Your query can actually go slower, or your scalar function may use features that SQL Server 2019 refuses to inline.
To fix this problem:
- Minimize the number of scalar functions you call – but keep in mind that even just one in your query causes the calling query to go single-threaded until SQL Server 2019 (and even in many cases in 2019, it’ll go single-threaded)
- Don’t use scalar user-defined functions in computed columns
- Don’t use them in check constraints, either
- Don’t use them in views, especially views that are called by lots of queries
Want to learn more about troubleshooting these kinds of issues?
 Check out my How I Use the First Responder Kit class. I walk you through using sp_BlitzWho, sp_BlitzFirst, sp_BlitzIndex, and many of the other scripts in the open source First Responder Kit.
Check out my How I Use the First Responder Kit class. I walk you through using sp_BlitzWho, sp_BlitzFirst, sp_BlitzIndex, and many of the other scripts in the open source First Responder Kit.
If you’ve got a Live Class Season Pass, you can drop in on this class or any of my live online classes at any time. Just head to my current training page, check out the schedule at the bottom of the page, and grab the calendar files for the classes you’re interested in. You don’t have to register ahead of time – just drop in anytime I’m streaming.
Or, if you’ve got a Recorded Class Season Pass, you can hop in and watch the recordings in your account at any time.
See you in class!
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
How does your above UDF perform when WITH SCHEMA BINDING is enabled within the function? Does that enable parallelism?
Makes no difference, sadly.
How about if you create a table-valued function to do the same same function, and applying it to the query?
(-1 for failing to check my grammar before hitting post)
Sure, go ahead and give that a shot – that’s why I use open source databases for my demos, so y’all can follow along and try your own experiments. (I cover that answer in my Mastering Query Tuning class, but it’s tough to do justice to it here in the comments.)
So scalar UDF when can they be used safely???
Hi Brent,
great post. Thanks for pointing this issue out. One follow up question/thought: Since the cost of the UDF is set to 0 inappropriateley, does this mean that the query optimizer does some “stupid” stuff? For example, if high costs would be associated with the UDF, then the optimizer would first try to reduce the amount of tuples on which the UDF is applied, right? However, if the cost is set to 0, the optimizer thinks that he can apply the UDF to all tuples altough some of them are not needed, right? Hence, the processing time is bad because we are doing some work that is not necessary.
From DB2 I know that there are some parameters, which can be used to control the behavior of UDFs. Is there something similar for Microsoft SQL Server?
Many thanks in advance! Looking forward to your response!
Thanks, glad you liked the post! Yes, we discuss these topics in more details in this lecture: https://training.brentozar.com/courses/1337725/lectures/30699589
Just ran into this issue when moving a SQL 2016 server VM to newer hardware on a new VM host. The modern HCI VM hosts have much faster CPUs, so there were quite a few less physical CPU cores, resulting in massive increases in runtimes for any stored procs using a scalar function inside a query with a decent sized row count. Inlining the function code obviously fixes the issue, and we were able to do this for the longest running queries to get runtimes back to reasonable levels. I’m wondering if it makes sense to convert scalar functions to procedural code inside an assembly and then mass replace the hundreds of places scalar functions are still being called with the procedural code methods. Replacing all the function calls with inline code would take forever, and with the amount of code on this server, a version upgrade could take many months of testing. Any idea if we’d see the same issue with a call to a method in an assembly as we see with the scalar functions?
I don’t have first-hand experience with that, no.
Hey Brent! Thanks for the helpful information, as always. I’ve been retroactively going through and devouring a lot of your content. (I just enrolled in a couple of your classes!)
Question for you, let’s say you’re using a scalar function inside of a stored procedure, but not in a query itself. For example, to aid with audit logging purposes or something, where there’s a scalar function set up to format text in a specific way for the log, that’s reuseable across all stored procedures that need to log a specific way.
That function will only run once for a single audit log inside of the stored procedure.
When you know the scalar function will only be ran once, and not inside of a query itself, is that still a harmful use of scalar functions? From what I’m gathering, the main reason why they’re bad, is because of the row-by-row execution which can easily rack-up CPU usage and time. Am I missing something that would make them harmful in an example like this?
Yep, that’s fine, as long as there’s no joins in the query calling the function, or the function itself. Cheers!
Holy cow! That was super quick. Thanks for being so responsive, Brent! Very appreciated. 🙂