Does the Rowmodctr Update for Non-Updating Updates?

Update May 20 – make sure to read to the end for an update.
Okay, look, it’s a mouthful of a blog post title, and there are only gonna be maybe six of us in the world who get excited enough to check this kind of thing, but if you’re in that intimate group, then the title’s already got you interested in the demo. (Shout out to Riddhi P. for asking this cool question in class.)
The system table sys.sysindexes has a rowmodctr that tells you how many times rows have been updated in an object. This comes in handy when we need to figure out if it’s time to update the statistics on a table.
To set the stage, let’s create a table, put a couple of indexes on it, and check rowmodctr to see how many changes have been made:
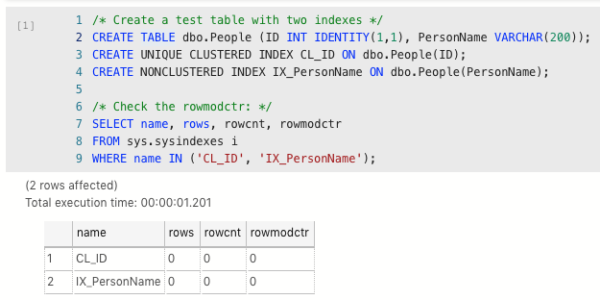
No rows have been modified yet since no data has been loaded. Let’s load 1,000 rows of data, and then check rowmodctr to see how many modifications have been made to the table:
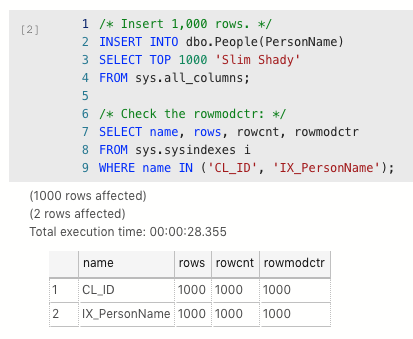
Rowmodctr is 1,000 because 1,000 rows have been modified in the table – hey, inserts count as modifications.
Now the fun starts: let’s update everybody’s PersonName to be the same thing:

Remember, we had rowmodctr 1,000 for both indexes just a second ago – and now the index has gone up (saying it was modified), and the clustered index stayed the same (indicating that it wasn’t.)
I’m gonna be honest with you, dear reader: this was not the result I expected.
As a naive, delicate flower, I expected SQL Server to treat the rowmodctr the same way on both the clustered and nonclustered indexes. Instead, here we’re showing zero new modifications on the clustered index, but 1,000 new modifications on the name index.
In the big scheme of things, this isn’t a showstopper problem. It’s not like I’m over here waving my hands going, “OMG, this violates the laws of space and time!” It’s a system table, and if anybody’s relying on this thing for razor-sharp accuracy, they probably deserve what’s coming to them. I just find it so amusing that it’s handled differently on the two kinds of indexes – even though neither of them were modified. Huh.
How about if we explicitly tell SQL Server to set it to the same value:
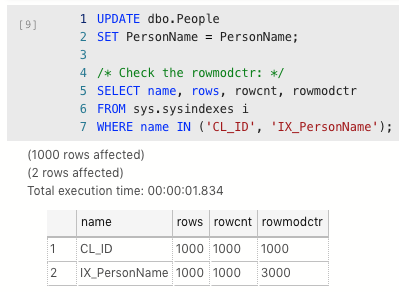
Again, the nonclustered index shows modifications, and the clustered index doesn’t.
So what’s the takeaway?
I don’t think this is a performance-shattering problem: it’s probably fairly rare that you find an application that runs updates even when no changes were made.
To be clear, the fix isn’t to switch to a delete-the-old-row-and-insert-a-new-row design pattern: that would be twice as bad, since now you’re doubling the number of rows modified with each operation.
People who bought this post also bought “The Impact of Non-Updating Updates” by Paul White and the excellent answers to this DBA.StackExchange question about updates.
Update May 20 – hoooweee, boy are my skills dated on rowmodctr. Since SQL Server 2005, Books Online points out that rowmodctr isn’t a counter for the number of modified rows, as the name might imply. Instead, it’s about the number of updates that would have affected the statistics on the index involved. Since the clustered index here is just about the Id column, and the updates weren’t on the Id, the rowmodctr doesn’t increment there. Doh! Shout out to the folks who DMd me on Twittter and left comments here. Good catch!
Free, 3× a week
Get my new posts by email
Three posts a week, plus a Monday roundup of the best database news from around the web.
“it’s probably fairly rare that you find an application that runs updates even when no changes were made.”
That’s adorable.
Most applications I’ve seen send an update back to the database if the user hits the button, regardless of whether or not any of the fields actually changed.
Is it possible that this happens because ID is not a Primary Key??
Doesn’t IX_PersonName have the PersonName value stored in the index itself since it is the indexed column? So, that value needs to change and the value in the table for the PersonName column needs to change, but the pointers between the non-clustered index and clustered index and the clustered index and the table do not change, so the clustered index is not being updated. To me this makes since. What am I missing?
Why should the index counter for the clustered index change if it does not include the column that has been changed? I really can’t find anything wrong or even smelling in the results shown. Also not that the modcounter has increased because it defenit lymhas eben executed, even if it got the same value as it had previously. Hmmm…
I agree with both Markus and Robert. If the purpose of rowmodctr is to indicate whether a statistics update would be appropriate, then it would not make any sense in the example above to increate this value for the clustered index; Nothing in the clustered index row order changes, so no need to update stats there.
One could argue whether increasing it on the NCLI due to updating PersonName by the very same value as before, but hey: the issue here is that the programmer got something wrong! (sorry Brent, I’m well aware that you would never do something like this unless it is for demonstrating an effect).
But I have another use case for this counter: checking whether there is any write access to a table! Take a snapshot of sys.indexes, wait an appropriate amount of time and then compare the current values of rowmodctr with those of the snapshot taken.
Hi folks! Yep, make sure to read the post. It’s been updated with my goof. Thanks!
Thanks for the post, but you didn’t include any code that could be used to identify which of the thousand rows contained the _real_ ‘Slim Shady’ and/or which were just imitators. I’m assuming it’s an undocumented DMF like sys.dm_db_standup()?
HA!
So…nobody is going to comment on the fact that this is an excellent post using SQL Notebooks? Only the second one I’ve seen – hat tip Jess Pomfret!
The moment they improve the Execution Plan functionality and add PowerShell support for Notebooks I’m thinking it’ll be “HELLO Azure Data Studio!” for me!
Shane – hahaha, thanks sir! Yeah, I’ve done another one here: https://www.brentozar.com/archive/2019/05/the-silent-bug-i-find-in-most-triggers/
I’m really excited about execution plan functionality as well – once that’s in, I’ll probably do all of my posts this way. I love having the blog post in an easy-to-consume format available offline, especially when I’m at client sites and they ask me a question that I know I’ve got a demo for.
Make that 7.