SQL ConstantCare® Population Report: Winter 2023
4 Comments
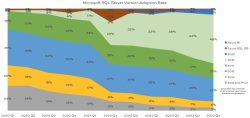
The short story: SQL Server 2019 continues its utter domination of the Microsoft data platform landscape this quarter. The long story: ever wonder how fast people are adopting new versions of SQL Server, or what’s “normal” out there for SQL Server adoption rates? Let’s find out in the winter 2023 version of our SQL ConstantCare®…
Read More