Free Webcast: Fixing Parameter Sniffing with Index Tuning
2 Comments
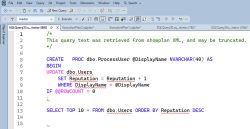
When a query is sometimes fast and sometimes slow, there are a lot of ways you can reduce the effects of parameter sniffing. We’re always going to have parameter sniffing in SQL Server and Azure SQL DB – it’s just the way the product is built – but there are a lot of options to reduce…
Read More